三、 多对一 –单向
场景:用户和组;从用户角度来,多个用户属于一个组(多对一 关联)
使用hibernate开发的思路:先建立对象模型(领域模型),把实体抽取出来。
目前两个实体:用户和组两个实体,多个用户属于一个组,那么一个用户都会对应于一个组,所以用户实体中应该有一个持有组的引用。
(一) 对象模型图:
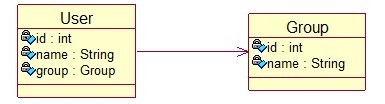
(二) 关系模型:
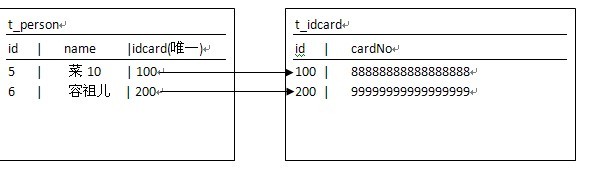
(三) 关联映射的本质:
将关联关系映射到数据库,所谓的关联关系是对象模型在内存中一个或多个引用。
(四) 实体类
User实体类:
public class User {
private int id;
private String name;
private Group group;
public Group getGroup() {return group; }
public void setGroup(Group group) {this.group = group;}
public int getId() {return id; }
public void setId(int id) { this.id = id;}
public String getName() {return name;}
public void setName(Stringname) { this.name = name;}}
Group实体类:
public class Group {
private int id;
private String name;
public int getId() {return id;}
public void setId(int id) { this.id = id;}
public String getName() {return name;}
public void setName(Stringname) {this.name = name;}
}
实体类建立完后,开始创建映射文件,先建立简单的映射文件:
(五) xml方式:映射文件:
1、 Group实体类的映射文件:
<hibernate-mapping>
<class name="com.wjt276.hibernate.Group" table="t_group">
<id name="id" column="id">
<generator class="native"/>
</id>
<property name="name"/>
</class>
</hibernate-mapping>
2、 User实体类的映射文件:
<hibernate-mapping>
<class name="com.wjt276.hibernate.User" table="t_user">
<id name="id" column="id">
<generator class="native"/>
</id>
<property name="name"/>
<!--<many-to-one> 关联映射 多对一的关系
name:是维护的属性(User.group),这样表示在多的一端表里加入一个字段名称为group,
但group与SQL中的关键字重复,所以需要重新命名字段(column="groupid").这样这个字段(groupid)会作为外键参照数据库中group表(t_group也叫一的一端),也就是就在多的一 端加入一个外键指向一的一端。 -->
<many-to-one name="group" column="groupid"/>
</class>
</hibernate-mapping>
3、 ※<many-to-one>标签※:
例如:<many-to-one name="group" column="groupid"/>
<many-to-one> 关联映射 多对一的关系
name:是维护的属性(User.group),这样表示在多的一端表里加入一个字段名称为group,但group与SQL中的关键字重复,所以需要重新命名字段(column="groupid").这样这个字段(groupid)会作为外键参照数据库中group表(t_group也叫一的一端),也就是就在多的一端加入一个外键指向一的一端。
这样导出至数据库会生成下列语句:
alter table t_user drop foreign keyFKCB63CCB695B3B5AC
drop table if exists t_group
drop table if exists t_user
create table t_group (id integer not nullauto_increment, name varchar(255), primary key (id))
create table t_user (id integer not nullauto_increment, name varchar(255), groupid integer,primary key (id))
alter table t_user add index FKCB63CCB695B3B5AC (groupid), add constraint FKCB63CCB695B3B5AC foreign key (groupid) referencest_group (id)
(六) annotation
Group(一的一端)注解只需要正常的注解就可以了,因为在实体类中它是被引用的。
User*(多的一端):@ManyToOne来注解多一对的关键,并且用@JoinColumn来指定外键的字段名
@Entity
public class User {
private int id;
private String name;
private Group group;
@ManyToOne
@JoinColumn(name="groupId")
public Group getGroup() {
return group;
}
(七) 多对一 存储(先存储group(对象持久化状态后,再保存user)):
session = HibernateUtils.getSession();
tx =session.beginTransaction();
Groupgroup = new Group();
group.setName("wjt276");
session.save(group); //存储Group对象。
Useruser1 = new User();
user1.setName("菜10");
user1.setGroup(group);//设置用户所属的组
Useruser2 = new User();
user2.setName("容祖儿");
user2.setGroup(group);//设置用户所属的组
//开始存储
session.save(user1);//存储用户
session.save(user2);
tx.commit();//提交事务
执行后hibernate执行以下SQL语句:
Hibernate: insert into t_group (name) values (?)
Hibernate: insert into t_user (name, groupid) values (?, ?)
Hibernate: insert into t_user (name, groupid) values (?, ?)
注意:如果上面的session.save(group)不执行,则存储不存储不成功。则抛出TransientObjectException异常。
因为Group为Transient状,Object的id没有分配值。2610644
结果:persistent状态的对象是不能引用Transient状态的对象
以上代码操作,必须首先保存group对象,再保存user对象。我们可以利用cascade(级联)方式,不需要先保存group对象。而是直接保存user对象,这样就可以在存储user之前先把group存储了。
利用cascade属性是解决TransientObjectException异常的一种手段。
(八) 重要属性-cascade(级联):
级联的意思是指定两个对象之间的操作联运关系,对一个 对象执行了操作之后,对其指定的级联对象也需要执行相同的操作,取值:all、none、save_update、delete
1、 all:代码在所有的情况下都执行级联操作
2、 none:在所有情况下都不执行级联操作
3、 save-update:在保存和更新的时候执行级联操作
4、 delete:在删除的时候执行级联操作。
1、 xml
例如:<many-to-one name="group"column="groupid" cascade="save-update"/>
2、 annotation
cascade属性:其值: CascadeType.ALL 所有
CascadeType.MERGE save+ update
CascadeType.PERSIST
CascadeType.REFRESH
CascadeType.REMOVE
例如:
@ManyToMany(cascade={CascadeType.ALL})
注意:cascade只是帮我们省了编程的麻烦而已,不要把它的作用看的太大
(九) 多对一 加载数据
代码如下:
session = HibernateUtils.getSession();
tx =session.beginTransaction();
Useruser = (User)session.load(User.class, 3);
System.out.println("user.name=" + user.getName());
System.out.println("user.group.name=" + user.getGroup().getName());
//提交事务
tx.commit();
执行后向SQL发出以下语句:
Hibernate: select user0_.id as id0_0_,user0_.name as name0_0_, user0_.groupid as groupid0_0_ from t_user user0_ whereuser0_.id=?
Hibernate: select group0_.id as id1_0_,group0_.name as name1_0_ from t_group group0_ where group0_.id=?
可以加载Group信息:因为采用了<many-to-one>这个标签,这个标签会在多的一端(User)加一个外键,指向一的一端(Group),也就是它维护了从多到一的这种关系,多指向一的关系。当你加载多一端的数据时,它就能把一的这一端数据加载上来。当加载User对象后hibernate会根据User对象中的groupid再来加载Group信息给User对象中的group属性。
四、 一对多 - 单向
在对象模型中,一对多的关联关系,使用集合来表示。
实例场景:班级对学生;Classes(班级)和Student(学生)之间是一对多的关系。
(一) 对象模型:

(二) 关系模型:

一对多关联映射利用了多对一关联映射原理。
(三) 多对一、一对多的区别:
多对一关联映射:在多的一端加入一个外键指向一的一端,它维护的关系是多指向一的。
一对多关联映射:在多的一端加入一个外键指向一的一端,它维护的关系是一指向多的。
两者使用的策略是一样的,只是各自所站的角度不同。
(四) 实体类
Classes实体类:
public class Classes {
private int id;
private String name;
//一对多通常使用Set来映射,Set是不可重复内容。
//注意使用Set这个接口,不要使用HashSet,因为hibernate有延迟加载,
private Set<Student>students = new HashSet<Student>();
public int getId() {return id; }
public void setId(int id) {this.id = id;}
public String getName() {return name;}
public void setName(Stringname) {this.name = name;}
}
Student实体类:
public class Student {
private int id;
private String name;
public int getId() {return id;}
public void setId(int id) { this.id = id;}
public String getName() {return name;}
public void setName(Stringname) { this.name = name;}
}
(五) xml方式:映射
1、 Student映射文件:
<hibernate-mapping>
<class name="com.wjt276.hibernate.Student" table="t_student">
<id name="id" column="id">
<generator class="native"/>
</id>
<property name="name" column="name"/>
</class>
</hibernate-mapping>
2、 Classes映射文件:
<hibernate-mapping>
<class name="com.wjt276.hibernate.Classes" table="t_classess">
<id name="id" column="id">
<generator class="native"/>
</id>
<property name="name" column="name"/>
<!--<set>标签 映射一对多(映射set集合),name="属性集合名称",然后在用<key>标签,在多的一端加入一个外键(column属性指定列名称)指向一的一端,再采用<one-to-many>标签说明一对多,还指定<set>标签中name="students"这个集合中的类型要使用完整的类路径(例如:class="com.wjt276.hibernate.Student") -->
<set name="students">
<key column="classesid"/>
<one-to-many class="com.wjt276.hibernate.Student"/>
</set>
</class>
</hibernate-mapping>
(六) annotateon注解
一对多 多的一端只需要正常注解就可以了。
需要在一的一端进行注解一对多的关系。
使用@OneToMany
@Entity
public class Classes {
private int id;
private String name;
// 一对多通常使用Set来映射,Set是不可重复内容。
// 注意使用Set这个接口,不要使用HashSet,因为hibernate有延迟加载,
private Set<Student>students = new HashSet<Student>();
@OneToMany//进行注解为一对多的关系
@JoinColumn(name="classesId")//在多的一端注解一个字段(名为classessid)
public Set<Student>getStudents() {
return students;
}
(七) 导出至数据库(hbmàddl)生成的SQL语句:
create table t_classes (id integer not null auto_increment, namevarchar(255), primary key (id))
create table t_student (id integer not null auto_increment, namevarchar(255), classesid integer, primary key (id))
alter table t_student add index FK4B90757070CFE27A (classesid), add constraint FK4B90757070CFE27A foreign key (classesid) referencest_classes (id)
(八) 一对多 单向存储实例:
session = HibernateUtils.getSession();
tx =session.beginTransaction();
Studentstudent1 = new Student();
student1.setName("10");
session.save(student1);//必需先存储,否则在保存classess时出错.
Studentstudent2 = new Student();
student2.setName("祖儿");
session.save(student2);//必需先存储,否则在保存classess时出错.
Set<Student>students = new HashSet<Student>();
students.add(student1);
students.add(student2);
Classesclasses = new Classes();
classes.setName("wjt276");
classes.setStudents(students);
session.save(classes);
tx.commit();
(九) 生成的SQL语句:
Hibernate: insert into t_student (name) values (?)
Hibernate: insert into t_student (name) values (?)
Hibernate: insert into t_classes (name) values (?)
Hibernate: update t_student set classesid=? where id=?
Hibernate: update t_student set classesid=? where id=?
(十) 一对多,在一的一端维护关系的缺点:
因为是在一的一端维护关系,这样会发出多余的更新语句,这样在批量数据时,效率不高。
还有一个,当在多的一端的那个外键设置为非空时,则在添加多的一端数据时会发生错误,数据存储不成功。
(十一) 一对多 单向数据加载:
session = HibernateUtils.getSession();
tx =session.beginTransaction();
Classesclasses = (Classes)session.load(Classes.class, 2);
System.out.println("classes.name=" + classes.getName());
Set<Student> students = classes.getStudents();
for(Iterator<Student> iter = students.iterator();iter.hasNext();){
Studentstudent = iter.next();
System.out.println(student.getName());
}
tx.commit();
(十二) 加载生成SQL语句:
Hibernate: select classes0_.id as id0_0_, classes0_.name as name0_0_ fromt_classes classes0_ where classes0_.id=?
Hibernate: select students0_.classesid as classesid1_, students0_.id asid1_, students0_.id as id1_0_, students0_.name as name1_0_ from t_studentstudents0_ where students0_.classesid=?
五、 一对多 - 双向
是加载学生时,能够把班级加载上来。当然加载班级也可以把学生加载上来
1、 在学生对象模型中,要持有班级的引用,并修改学生映射文件就可以了。。
2、 存储没有变化
3、 关系模型也没有变化
(一) xml方式:映射
学生映射文件修改后的:
<class name="com.wjt276.hibernate.Student" table="t_student">
<id name="id" column="id">
<generator class="native"/>
</id>
<property name="name" column="name"/>
<!--使用多对一标签映射 一对多双向,下列的column值必需与多的一端的key字段值一样。-->
<many-to-one name="classes" column="classesid"/>
</class>
如果在一对多的映射关系中采用一的一端来维护关系的话会存在以下两个缺点:①如果多的一端那个外键设置为非空时,则多的一端就存不进数据;②会发出多于的Update语句,这样会影响效率。所以常用对于一对多的映射关系我们在多的一端维护关系,并让多的一端维护关系失效(见下面属性)。
代码:
<class name="com.wjt276.hibernate.Classes" table="t_classes">
<id name="id"column="id">
<generator class="native"/>
</id>
<property name="name"column="name"/>
<!--
<set>标签 映射一对多(映射set集合),name="属性集合名称"
然后在用<key>标签,在多的一端加入一个外键(column属性指定列名称)指向一的一端
再采用<one-to-many>标签说明一对多,还指定<set>标签中name="students"这个集合中的类型
要使用完整的类路径(例如:class="com.wjt276.hibernate.Student")
inverse="false":一的一端维护关系失效(反转) :false:可以从一的一端维护关系(默认);true:从一的一端维护关系失效,这样如果在一的一端维护关系则不会发出Update语句。 -->
<set name="students"inverse="true">
<key column="classesid"/>
<one-to-many class="com.wjt276.hibernate.Student"/>
</set>
</class>
(二) annotateon方式注解
首先需要在多的一端持有一的一端的引用
因为一对多的双向关联,就是多对一的关系,我们一般在多的一端来维护关系,这样我们需要在多的一端实体类进行映射多对一,并且设置一个字段,而在一的一端只需要进行映射一对多的关系就可以了,如下:
多的一端
@Entity
public class Student {
private int id;
private String name;
private Classes classes;
@ManyToOne
@JoinColumn(name="classesId")
public ClassesgetClasses() {
return classes;
}
一的一端
@Entity
public class Classes {
private int id;
private String name;
// 一对多通常使用Set来映射,Set是不可重复内容。
// 注意使用Set这个接口,不要使用HashSet,因为hibernate有延迟加载,
private Set<Student>students = new HashSet<Student>();
@OneToMany(mappedBy="classes")//进行注解为一对多的关系
public Set<Student>getStudents() {
return students;}
(三) 数据保存:
一对多 数据保存,从多的一端进行保存:
session = HibernateUtils.getSession();
tx =session.beginTransaction();
Classesclasses = new Classes();
classes.setName("wjt168");
session.save(classes);
Studentstudent1 = new Student();
student1.setName("10");
student1.setClasses(classes);
session.save(student1);
Studentstudent2 = new Student();
student2.setName("祖儿");
student2.setClasses(classes);
session.save(student2);
//提交事务
tx.commit();
注意:一对多,从多的一端保存数据比从一的一端保存数据要快,因为从一的一端保存数据时,会多更新多的一端的一个外键(是指定一的一端的。)
(四) 关于inverse属性:
inverse主要用在一对多和多对多双向关联上,inverse可以被设置到集合标签<set>上,默认inverse为false,所以我们可以从一的一端和多的一端维护关联关系,如果设置inverse为true,则我们只能从多的一端维护关联关系。
注意:inverse属性,只影响数据的存储,也就是持久化
(五) Inverse和cascade区别:
Inverse是关联关系的控制方向
Casecade操作上的连锁反应
(六) 一对多双向关联映射总结:
在一的一端的集合上使用<key>,在对方表中加入一个外键指向一的一端
在多的一端采用<many-to-one>
注意:<key>标签指定的外键字段必须和<many-to-one>指定的外键字段一致,否则引用字段的错误
如果在一的一端维护一对多的关系,hibernate会发出多余的update语句,所以我们一般在多的一端来维护关系。