一、主从复制
通过持久化功能,Redis保证了即使在服务器重启的情况下也不会损失(或少量损失)数据,因为持久化会把内存中数据保存到硬盘上,重启会从硬盘上加载数据。
。但是由于数据是存储在一台服务器上的,如果这台服务器出现硬盘故障等问题,也会导致数据丢失。为了避免单点故障,通常的做法是将数据库复制多个副本以部署在不同的服务器上,这样即使有一台服务器出现故障,其他服务器依然可以继续提供服务。为此, Redis 提供了复制(replication)功能,可以实现当一台数据库中的数据更新后,自动将更新的数据同步到其他数据库上。
在复制的概念中,数据库分为两类,一类是主数据库(master),另一类是从数据库[1] (slave)。主数据库可以进行读写操作,当写操作导致数据变化时会自动将数据同步给从数据库。而从数据库一般是只读的,并接受主数据库同步过来的数据。一个主数据库可以拥有多个从数据库,而一个从数据库只能拥有一个主数据库。
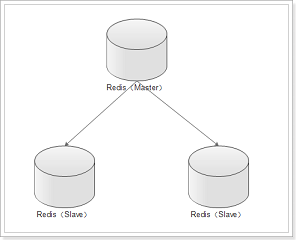
特点:
1、master/slave 角色
2、master/slave 数据相同
3、降低 master 读压力在转交从库
问题:
1.主节点只有一台服务器,因此写能力和存储能力收到了单机限制
2.一旦主节点出现故障,需要手动将一个从节点晋升为主节点,同时还需要修改应用方(如java程序)的主节点地址(连接redis的ip端口等),还需要命令其他从节点重新去复制新的主节点,整个过程需要人工干预。这个时候就需要用到哨兵机制了
二 Redis容灾部署哨兵(sentinel)
Redis Sentinel为Redis提供了高可用解决方案。实际上这意味着使用Sentinel可以部署一套Redis,在没有人为干预的情况下去应付各种各样的失败事件。
Redis Sentinel同时提供了一些其他的功能,例如:监控、通知、并为client提供配置。
哨兵的作用:
- 监控(Monitoring):Sentinel不断的去检查你的主从实例是否按照预期在工作。
- 通知(Notification):Sentinel可以通过一个api来通知系统管理员或者另外的应用程序,被监控的Redis实例有一些问题。
- 自动故障转移(Automatic failover):如果一个主节点没有按照预期工作,Sentinel会开始故障转移过程,把一个从节点提升为主节点,并重新配置其他的从节点使用新的主节点,使用Redis服务的应用程序在连接的时候也被通知新的地址。
- 配置提供者(Configuration provider):Sentinel给客户端的服务发现提供来源:对于一个给定的服务,客户端连接到Sentinels来寻找当前主节点的地址。当故障转移发生的时候,Sentinels将报告新的地址。
Sentinel的分布式特性
Redis Sentinel是一个分布式系统,Sentinel运行在有许多Sentinel进程互相合作的环境下,它本身就是这样被设计的。有许多Sentinel进程互相合作的优点如下:
- 当多个Sentinel同意一个master不再可用的时候,就执行故障检测。这明显降低了错误概率。
- 即使并非全部的Sentinel都在工作,Sentinel也可以正常工作,这种特性,让系统非常的健康。
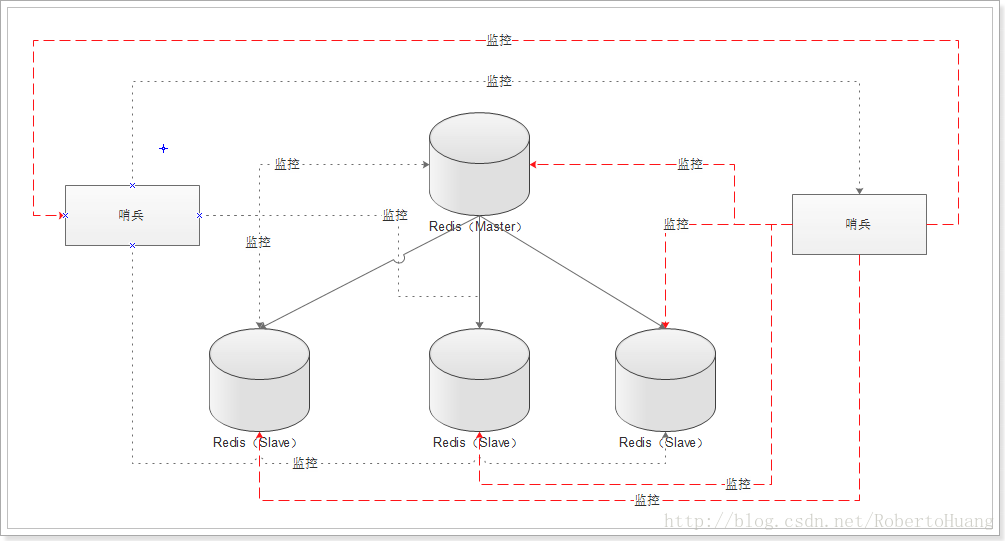
多个哨兵,不仅同时监控主从数据库,而且哨兵之间互为监控
例子: 1主2从 1哨兵,可以用命令起也可以用配置文件里 可以使用双哨兵,更安全, redis-server --port 6379 redis-server --port 6380 --slaveof 192.168.0.167 6379 redis-server --port 6381 --slaveof 192.168.0.167 6379 redis-sentinel sentinel.conf 哨兵配置文件 sentinel.conf sentinel monitor mymaster 192.168.0.167 6379 1 其中mymaster表示要监控的主数据库的名字,可以自己定义一个。这个名字必须仅由大小写字母、数字和“.-_”这 3 个字符组成。后两个参数表示主数据库的地址和端口号,这里我们要监控的是主数据库6379。 注意: 1、使用时不能用127.0.0.1,需要用真实IP,不然java程序通过哨兵会连到java程序所在的机器(127.0.0.1 ) 2、配置哨兵监控一个系统时,只需要配置其监控主数据库即可,哨兵会自动发现所有复制该主数据库的从数据库 这样哨兵就能监控主6379和从6380、6381,一旦6379挂掉,哨兵就会在2个从中选择一个作为主,根据优先级选,如果一样就选个id小的,当6379再起来就作为从存在。 主从切换过程: (1) slave leader升级为master (2) 其他slave修改为新master的slave (3) 客户端修改连接 (4) 老的master如果重启成功,变为新master的slave 哨兵监控1主2从,停掉主,哨兵会选出1个从作为主,变成1主1从。然而当我把原来的主再起来,它会作为新的从
特点:
1、保证高可用
2、监控各个节点
3、自动故障迁移
缺点:主从模式,切换需要时间丢数据
没有解决 master 写的压力
三、集群
Redis集群的概念:
RedisCluster是redis的分布式解决方案,在3.0版本后推出的方案,有效地解决了Redis分布式的需求,当一个服务挂了可以快速的切换到另外一个服务,当遇到单机内存、并发等瓶颈时,可使用此方案来解决这些问题
一、分布式数据库概念
1. 分布式数据库把整个数据按分区规则映射到多个节点,即把数据划分到多个节点上,每个节点负责整体数据的一个子集。比如我们库有900条用户数据,有3个redis节点,将900条分成3份,分别存入到3个redis节点
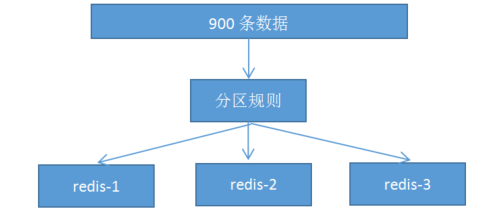
2. 分区规则:
常见的分区规则哈希分区和顺序分区,redis集群使用了哈希分区,顺序分区暂用不到,不做具体说明;
rediscluster采用了哈希分区的“虚拟槽分区”方式(哈希分区分节点取余、一致性哈希分区和虚拟槽分区)
3. 虚拟槽分区(槽:slot)
RedisCluster采用此分区,所有的键根据哈希函数(CRC16[key]&16383)映射到0-16383槽内,共16384个槽位,每个节点维护部分槽及槽所映射的键值数据
哈希函数: Hash()=CRC16[key]&16383 按位与
槽与节点的关系如下
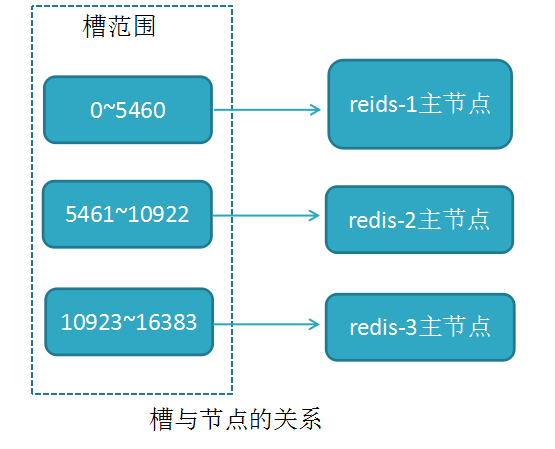

redis用虚拟槽分区原因:解耦数据与节点关系,节点自身维护槽映射关系,分布式存储
4. redisCluster的缺陷:
a,键的批量操作支持有限,比如mset, mget,如果多个键映射在不同的槽,就不支持了
b,键事务支持有限,当多个key分布在不同节点时无法使用事务,同一节点是支持事务
c,键是数据分区的最小粒度,不能将一个很大的键值对映射到不同的节点
d,不支持多数据库,只有0,select 0
e,复制结构只支持单层结构,不支持树型结构。
5、集群环境搭建-手动篇
部署结构图:6389为6379的从节点,6390为6380的从节点,6391为6381的从节点
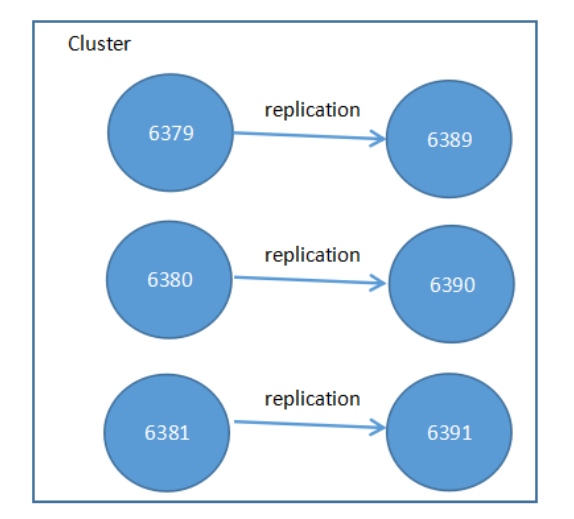
1.在/usr/local/bin/目录下新建一个文件夹clusterconf,用来存放集群的配置文件
2. 分别修改6379、 6380、 7381、 6389、 6390、 6391配置文件
以6379的配置为例:
port 6379 //节点端口
cluster-enabled yes //开启集群模式
cluster-node-timeout 15000 //节点超时时间(接收pong消息回复的时间)
cluster-config-file /usr/localbin/cluster/data/nodes-6379.conf 集群内部配置文件
其它节点的配置和这个一致,改端口即可
3. 配置完后,启动6个redis服务
./redis-server clusterconf/redis6379.conf &
./redis-server clusterconf/redis6380.conf &
./redis-server clusterconf/redis6381.conf &
./redis-server clusterconf/redis6389.conf &
./redis-server clusterconf/redis6390.conf &
./redis-server clusterconf/redis6391.conf &
4. 各节点启动后,使用cluster meet ip port与各节点握手,是集群通信的第一步(关键步骤1:集群搭建-与各节点握手)
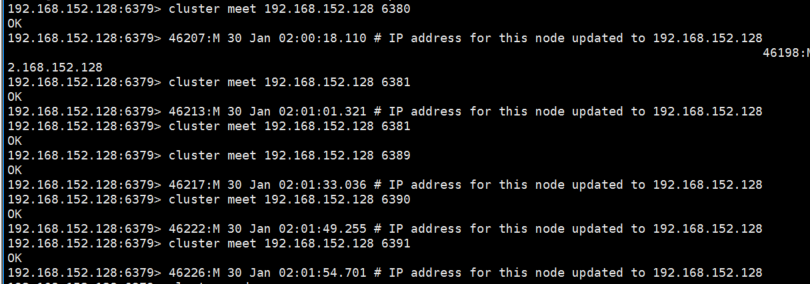
5. 握手成功后,使用cluster nodes可以看到各节点都可以互相查询到

6. 节点握手成功后,此时集群处理下线状态,所有读写都被禁止

7. 使用cluster info命令获取集群当前状态
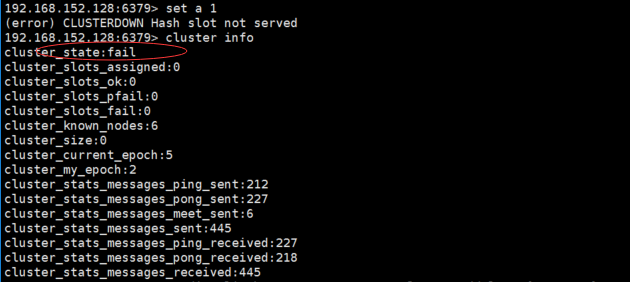
8. redis集群有16384个哈希槽,要把所有数据映射到16384槽,需要批量设置槽(关键步骤2:集群搭建-分配槽)
redis-cli -h 192.168.152.128 -p 6379 cluster addslots {0...5461}
redis-cli -h 192.168.152.128 -p 6380 cluster addslots {5641...10922}
redis-cli -h 192.168.152.128 -p 6381 cluster addslots {10923...16383}
9. 分配完槽后,可查看集群状态cluster info
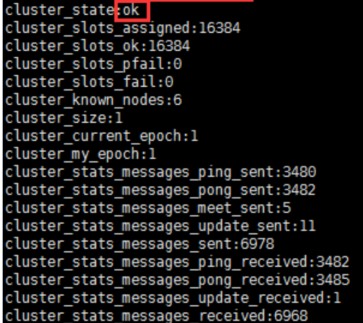
11. 然后再查看cluster nodes,查看每个节点的ID

12. 将6389,6390,6391与 6379,6380,6381做主从映射(关键步骤3:集群搭建-集群映射),到此redis集群手动搭建完成
192.168.152.128:6389> cluster replicate 9b7b0c22f95eb01fb9935ad4b04d396c7f99e881
192.168.152.128:6390> cluster replicate 5351c088472467ae485ed519cea271efda646bfa
92.168.152.128:6391> cluster replicate e718f126278072e1e180c3e518d73e0bc877b3dc
更多详解,可参考以下链接
https://www.cnblogs.com/leeSmall/p/8414687.html