一、java.lang.String
1、string对象不可变,被final修饰,不能被继承。
2、赋值方式:
(1)直接赋值。比如: String name = "rick";
(2)使用new关键字创建。比如:String name = new String("rick");
3、常用构造方法:
(1)public String(); //无参构造方法,用来创建空字符串的String对象。
(2)public String(String original); //用已知的字符串original创建一个String对象。
(3)public String(char value[]); //用字符数组value创建一个String对象。
(4)public String(char value[], int offset, int count); //用字符数组value的offset开始的count个字符创建一个String对象。
(5)public String(byte bytes[]); //用字节数组bytes创建一个String对象。
(6)public String(byte bytes[], String charsetName); //根据指定编码格式charsetName,用字节数组bytes创建一个String对象。
(7)public String(byte bytes[], int offset, int length, String charsetName); //根据指定编码格式charsetName,用字节数组bytes的offset开始的length个字符创建一个String对象。
4、常用方法:
(1)public int length() ; //返回该字符串的长度。
(2)public boolean isEmpty() ; //判断字符串是否为空。
(3)public char charAt(int index) ; //返回字符串中指定位置的字符;字符串范围为 0 ~ length()-1。
(4)public byte[] getBytes(String charsetName); //根据指定编码格式charsetName,将字符串转为字节数组。
(5)public boolean equals(Object anObject); //用于比较两个字符串内容是否相同。相同返回true,不同返回false。
(6)public boolean equalsIgnoreCase(String anotherString); //与equals比较类似,但忽略大小写。
(7)public int compareTo(String anotherString); //按字典顺序逐个字符进行比较,返回的数即为字符间的差距(大小关系)。若字符大于anotherString的字符,则返回正数,小于则返回负数,等于则返回0。
(8)public int compareToIgnoreCase(String str); //与compareTo类似,但忽略大小写。
(9)public boolean startsWith(String prefix); //判断字符串是否以指定字符串prefix开头。
(10)public boolean endsWith(String suffix); //判断字符串是否以指定字符串suffix结尾。
(11)public int hashCode(); //用于返回字符串的哈希码。
(12)public boolean contains(CharSequence s); //判断当前字符串是否包含 给定的子字符串s。
(13)public String concat(String str) ; //用于字符串的拼接。等价于 符号 “+”。
(14)public String trim(); //用于去除字符串首尾两端的空格。
(15)public String toLowerCase(); //将字符串全转成小写字符串。
(16)public String toUpperCase(); //将字符串全转为大写字符串。
(17)public char[] toCharArray() ; //将字符串转为字符数组。
(18)public String substring(int beginIndex); //从当前字符串中的beginIndex位置起,取出剩余的字符作为一个新的字符串返回。
(19)public String substring(int beginIndex, int endIndex); //从当前字符串中的beginIndex位置起,取出到endIndex-1位置的字符作为一个新的字符串返回。
(20)public String replace(char oldChar, char newChar); //用字符newChar替换当前字符串中所有的oldChar字符,并返回一个新的字符串。
(21)public String replaceAll(String regex, String replacement);将字符串中符合regex格式的子串替换成replacement,此时并未改变原始字符串。
(22)public String[] split(String regex); //将字符串使用regex标记分割,并将分割后的单词存入字符串数组中。
(23)public boolean matches(String regex); //判断当前字符串对象是否与参数regex格式相匹配。
二、java.lang.StringBuffer、java.lang.StringBuilder
1、当频繁修改字符串时,需要使用 StringBuffer 和 StringBuilder 类。与String 类不同的是,StringBuffer 和 StringBuilder 类的对象能够被多次的修改,并且不产生新的未使用对象。
2、StringBuffer与StringBuilder大体上相似,只是StringBuffer属于线程安全的。对于单线程的程序,推荐使用StringBuilder。
3、常用构造方法:(以StringBuffer为例)
(1)public StringBuffer(); //默认构造一个不带字符的字符串缓冲区,初始容量为16个字符。
(2)public StringBuffer(String str); //构造一个str.length() + 16的字符串缓冲区。
4、常用方法:(以StringBuffer为例)
(1)追加:
public synchronized StringBuffer append(Object obj); //将对象追加到字符串的末尾。
(2)插入:
public StringBuffer insert(int dstOffset, CharSequence s) ; //将字符串s插入到指定位置 dstOffset。字符串范围为 0 ~ length()-1。
(3)删除:
public synchronized StringBuffer delete(int start, int end); //删除start ~ end-1 范围的字符。
public synchronized StringBuffer deleteCharAt(int index); //删除指定位置的字符。
(4)替换:
public synchronized StringBuffer replace(int start, int end, String str); //用给定 String 中的字符替换此序列(start ~ end-1)的子字符串中的字符。
public synchronized void setCharAt(int index, char ch); //用给定的字符ch,替换指定位置的字符。
public synchronized void setLength(int newLength); // 将给定的字符串,裁剪成指定长度。
(5)获取子串:
public synchronized String substring(int start); //返回从start位置开始 的所有字符。
public synchronized String substring(int start, int end); //返回 start ~ end-1 位置的所有字符。
(6)字符串反转:
public synchronized StringBuffer reverse(); //将字符串倒序输出。
(7)查找:
public int indexOf(String str); //正序查找(从前往后找),返回指定子字符串在此字符串第一次出现的索引,若没有,则返回-1。
public synchronized int indexOf(String str, int fromIndex); //从 fromIndex 位置开始查找。返回指定子字符串在此字符串第一次出现的索引,若没有,则返回-1。
public int lastIndexOf(String str); //倒序查找(从后往前找)返回指定子字符串在此字符串第一次出现的索引,若没有,则返回-1。
public synchronized int lastIndexOf(String str, int fromIndex) ; //从 fromIndex 位置开始查找。返回指定子字符串在此字符串第一次出现的索引,若没有,则返回-1。
三、String、StringBuffer、StringBuilder的区别
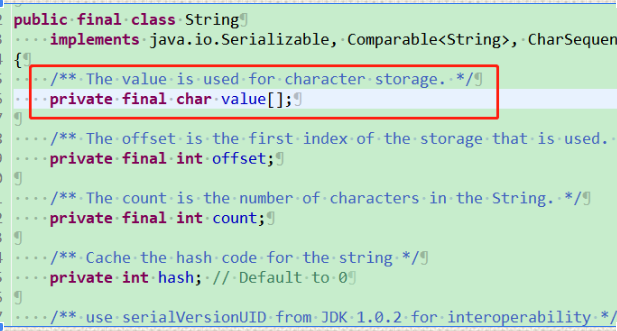
1、String中由final修饰的字符数组来保存字符串,即private final char value[],所以String不可变。
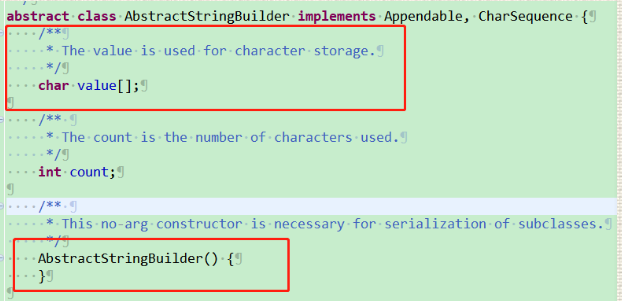
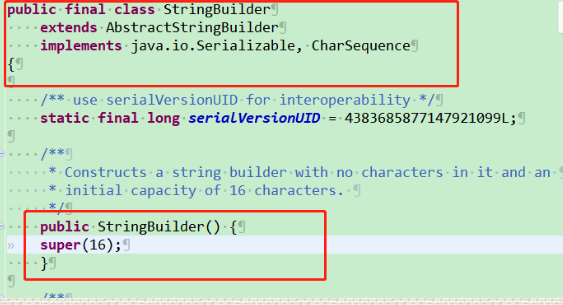
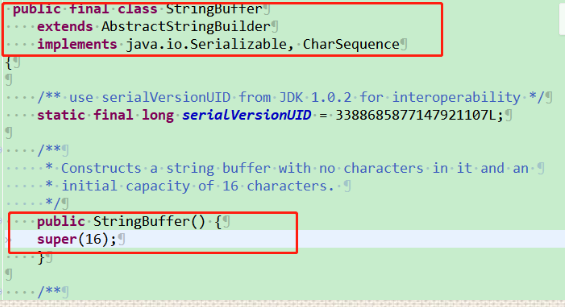
2、StringBuffer与StringBuilder继承 AbstractStringBuilder类,且其构造方法中调用AbstractStringBuilder类的构造方法,而AbstractStringBuilder类未使用final修饰字符数组来保存字符串,即char value[], 故StringBuilder与StringBuilder可变。
3、线程安全?
(1)String对象不可变,所以是线程安全的。
(2)StringBuffer由于方法加入同步锁,所以是线程安全的。
(3)StringBuilder没有同步锁,所以是线程不安全的。
4、对于String对象,给其赋值分两种情况:
(1)直接赋值,即String str = "123";时,若常量池中存在"123",则str指向这个字符串,若不存在,则创建一个"123"并置于常量池中,将其引用返回。
(2)使用new关键字,即String str = new String("123");如果常量池中没有"123",则创建"123"并置于常量池中,然后new关键字会在堆中创建一个String对象,并将堆中的引用返回。
5、使用情况?
(1)操作少量数据,推荐使用String。
(2)单线程下操作大量数据,推荐使用StringBuilder。
(3)多线程下操作大量数据,推荐使用StringBuffer。
四、java.util.StringTokenizer
1、String类中的split()方法是使用正则表达式分解字符串。使用StringTokenizer类可以不使用正则表达式分解字符串。
2、构造方法:
(1)public StringTokenizer(String str); //为字符串s构造一个分析器,使用默认的分隔标记(空白符),即空格符(多个空格被看成一个空格),换行符,回车符,Tab符等。
(2)public StringTokenizer(String str, String delim); //为字符串s构造一个分析器,使用delim中的字符作为分隔符。
注意:分隔标记的任意组合仍是分隔标记。
3、常用方法:
(1)public int countTokens() ; //获取当前分析器中按照标记切割后的单词数量
(2)public String nextToken(); //逐个获取字符串中分割的单词,每次成功获取,则单词数自动减一。
(3)public boolean hasMoreElements() //控制循环,若当前分析器中还有单词,即单词数大于1,则返回true。
1 import java.util.StringTokenizer; 2 3 public class Test { 4 public static void main(String args[]) { 5 StringTokenizer st = new StringTokenizer("hello,,, world", ","); 6 System.out.println("切割后单词数量为: " + st.countTokens());// 输出按标记切割后的单词数 7 System.out.println("单词分别为: "); 8 while (st.hasMoreTokens()) {// 控制循环 9 System.out.println(st.nextToken()); // 获取单词 10 } 11 } 12 } 13 /* 14 * 测试结果: 15 * 切割后单词数量为: 2 16 * 单词分别为: 17 * hello 18 * world 19 * 20 */