一、JML语言理论基础、应用工具链
(1)语言基础
JML的全程为Java Modeling Language,是一种用于规范java模块的行为接口规范语言。JML基本语法在JML level 0 手册中有比较详细的叙述
主要结构有:
JML表达式
·原子表达式
·量化表达式
·集合表达式
·操作符
方法规格
·前置条件
·后置条件
·副作用范围限定
类型规格
(2)应用工具链
·openJML: 对JML的语法和规格进行检查
·JML SMT Solver: 与openJML配合使用检查java模块是否满足jml规格
·JML UnitNG:根据JML自动生成测试代码对规格进行测试
二、部署SMT Solver
因为下图的原因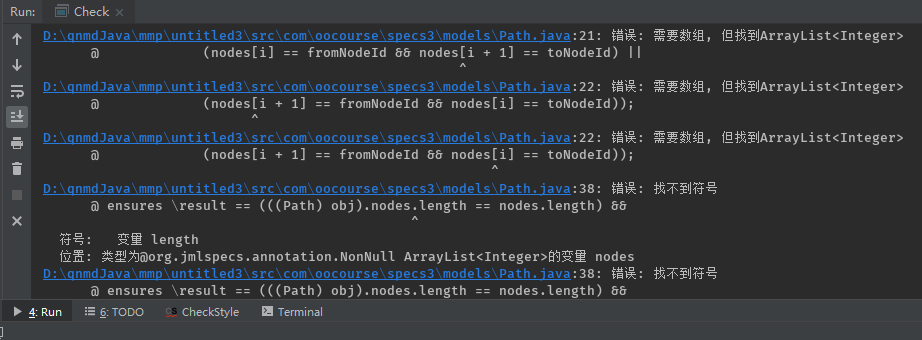
所以,我另外写了个文件配置smt solver运行openJML
如下图所示,存在数据溢出的问题
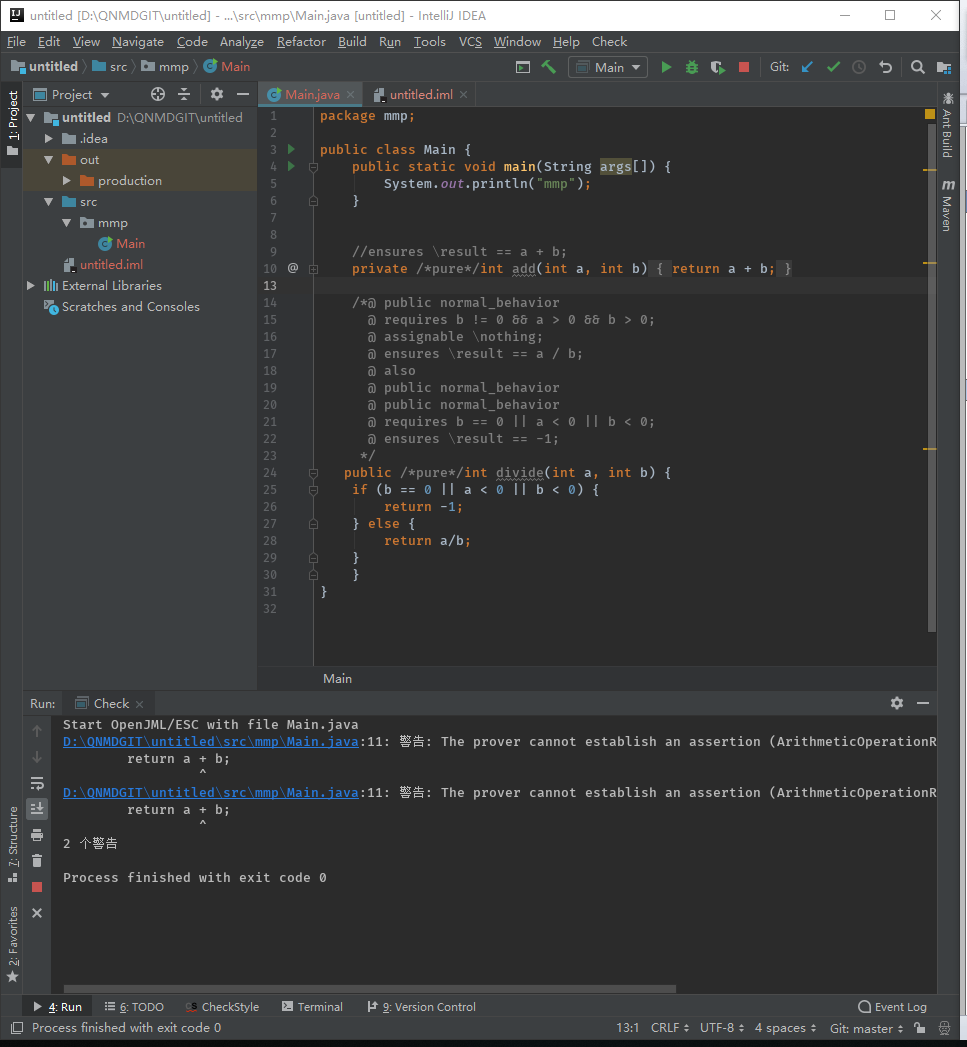
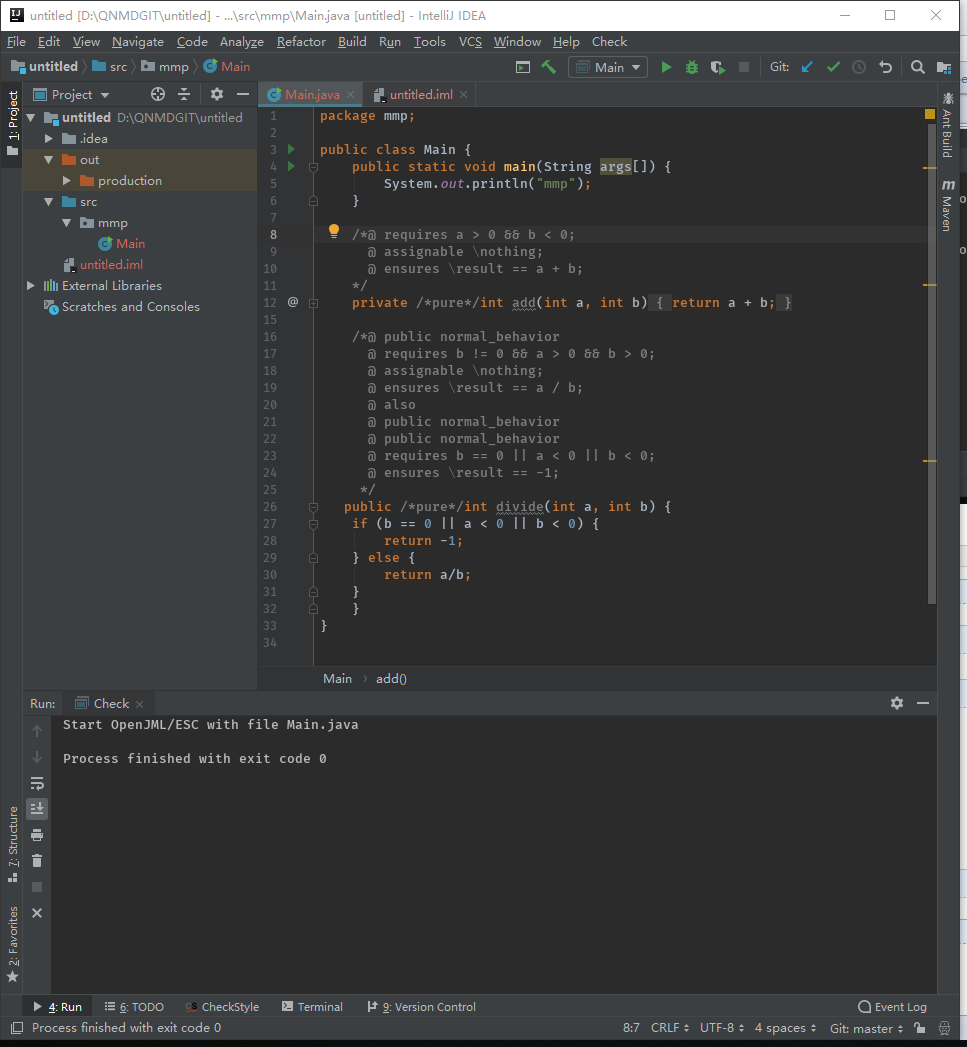
所以修改了一下add()函数的限制,
三、部署JMLUnitNG/JMLUnit
由于openJML不支持forall语句以及对于nodes的类型限制的过于死板,我写了个简单的文件使用JMLUnitNG自动生成测试代码,文件代码如下
public class blog { /*@ @ assignable othing; @ ensures esult == a + b; */ public /*pure*/int add(int a, int b) { return a + b; } /*@ public normal_behavior @ requires b != 0 && a > 0 && b > 0; @ assignable othing; @ ensures esult == a / b; @ also @ public normal_behavior @ requires b == 0 || a < 0 || b < 0; @ ensures esult == 0; */ public /*pure*/int divide(int a, int b) { if (b == 0 || a < 0 || b < 0) { return 0; } else { return a/b; } } /*@ public normal_behavior @ assignable othing; @ ensures (a >= b && a >= c)==>( esult == a) && (b>=a && b >= c) ==>( esult == b) && @ (c>=a && c>= b) ==> ( esult == c); */ public int findBiggest(int a, int b, int c) { if (a>=b&& a>=c) { return a; } else if (b >= a && b >= c){ return b; } else{ return c; } } }
很明显,add()会有上下溢出问题
JMLUnitNG生成的测试代码如下
[TestNG] Running: Command line suite Passed: racEnabled() Failed: <<mmp.blog@6842775d>>.add(-2147483648, -2147483648) Passed: <<mmp.blog@574caa3f>>.add(0, -2147483648) Passed: <<mmp.blog@64cee07>>.add(2147483647, -2147483648) Passed: <<mmp.blog@5ecddf8f>>.add(-2147483648, 0) Passed: <<mmp.blog@3f102e87>>.add(0, 0) Passed: <<mmp.blog@27abe2cd>>.add(2147483647, 0) Passed: <<mmp.blog@5f5a92bb>>.add(-2147483648, 2147483647) Passed: <<mmp.blog@6fdb1f78>>.add(0, 2147483647) Failed: <<mmp.blog@51016012>>.add(2147483647, 2147483647) Passed: constructor blog() Passed: <<mmp.blog@29444d75>>.divide(-2147483648, -2147483648) Passed: <<mmp.blog@2280cdac>>.divide(0, -2147483648) Passed: <<mmp.blog@1517365b>>.divide(2147483647, -2147483648) Passed: <<mmp.blog@4fccd51b>>.divide(-2147483648, 0) Passed: <<mmp.blog@60215eee>>.divide(0, 0) Passed: <<mmp.blog@4ca8195f>>.divide(2147483647, 0) Passed: <<mmp.blog@65e579dc>>.divide(-2147483648, 2147483647) Passed: <<mmp.blog@61baa894>>.divide(0, 2147483647) Passed: <<mmp.blog@b065c63>>.divide(2147483647, 2147483647) Passed: <<mmp.blog@768debd>>.findBiggest(-2147483648, -2147483648, -2147483648) Passed: <<mmp.blog@490d6c15>>.findBiggest(0, -2147483648, -2147483648) Passed: <<mmp.blog@7d4793a8>>.findBiggest(2147483647, -2147483648, -2147483648) Passed: <<mmp.blog@449b2d27>>.findBiggest(-2147483648, 0, -2147483648) Passed: <<mmp.blog@5479e3f>>.findBiggest(0, 0, -2147483648) Passed: <<mmp.blog@27082746>>.findBiggest(2147483647, 0, -2147483648) Passed: <<mmp.blog@66133adc>>.findBiggest(-2147483648, 2147483647, -2147483648) Passed: <<mmp.blog@7bfcd12c>>.findBiggest(0, 2147483647, -2147483648) Passed: <<mmp.blog@42f30e0a>>.findBiggest(2147483647, 2147483647, -2147483648) Passed: <<mmp.blog@24273305>>.findBiggest(-2147483648, -2147483648, 0) Passed: <<mmp.blog@5b1d2887>>.findBiggest(0, -2147483648, 0) Passed: <<mmp.blog@46f5f779>>.findBiggest(2147483647, -2147483648, 0) Passed: <<mmp.blog@1c2c22f3>>.findBiggest(-2147483648, 0, 0) Passed: <<mmp.blog@18e8568>>.findBiggest(0, 0, 0) Passed: <<mmp.blog@33e5ccce>>.findBiggest(2147483647, 0, 0) Passed: <<mmp.blog@270421f5>>.findBiggest(-2147483648, 2147483647, 0) Passed: <<mmp.blog@52d455b8>>.findBiggest(0, 2147483647, 0) Passed: <<mmp.blog@4f4a7090>>.findBiggest(2147483647, 2147483647, 0) Passed: <<mmp.blog@18ef96>>.findBiggest(-2147483648, -2147483648, 2147483647) Passed: <<mmp.blog@6956de9>>.findBiggest(0, -2147483648, 2147483647) Passed: <<mmp.blog@769c9116>>.findBiggest(2147483647, -2147483648, 2147483647) Passed: <<mmp.blog@6aceb1a5>>.findBiggest(-2147483648, 0, 2147483647) Passed: <<mmp.blog@2d6d8735>>.findBiggest(0, 0, 2147483647) Passed: <<mmp.blog@ba4d54>>.findBiggest(2147483647, 0, 2147483647) Passed: <<mmp.blog@12bc6874>>.findBiggest(-2147483648, 2147483647, 2147483647) Passed: <<mmp.blog@de0a01f>>.findBiggest(0, 2147483647, 2147483647) Passed: <<mmp.blog@4c75cab9>>.findBiggest(2147483647, 2147483647, 2147483647) =============================================== Command line suite Total tests run: 47, Failures: 2, Skips: 0 ===============================================
可以看出来这个JMLUnitNG生成测试用例的时候,对于int类型会生成-2147483648,0, 2147483647三种数据,然后输入这三种数据的排列组合进行测试,可以看出是负最小值,0,正最大值,用来测试是否会有上下溢出问题
但对于其他问题检测不到
由于我的测试用例比较简单测试使用的变量类型不够多,没有测试别的数据类型会有什么样的输入
四、作业架构梳理
(1)第一次作业 Path和PathContainer
1.实现思路
由于是第一次作业,比较简单,照着jml实现就行,主要有几点,一个是没有jml指导的compareTo(Path o)类,另一个是PathContainer里面的getDistinctNodeCount()这两个函数,compareTo()函数如果返回值计算方式不对,会导致溢出的问题;getDistinctNodeCount()则是要优化方法减少时间复杂度防止TLE问题。
2.代码架构
MyPath类里面使用ArrayList<Integer>类型保存nodes,同时使用HashMap<Integer,Integer>类型保存互补相同的node,以node为key,以node的出现的次数为value进行保存,虽然使用hashset就行,此外为了支持hashmap保存MyPath类,重写了hashCode()函数,同时为了保证安全性,重写了Iterator
MyPathContainer类里使用private HashMap<Integer, Path> pathList和private HashMap<Path, Integer> pidList保存path和pathid之间的偶对,方便使用path和pathid之间互相查找;同时还保存了一个HashMap<Integer,Integer> distinNode用来保存互不相同的点,跟MyPath里面的HashMap一样,以node为key,value是其node出现的次数。同时在addpath的时候,除了将path加入pathList和pidList中,此外还要遍历path,将path里面的点添加到distinNode中,如果distinNode中以及记录了node,则node计数增加。当使用removePath()和removePathById()函数的时候,除了将path从pathList和pidList中移除,还要遍历path中的点,如果distinNode的计数为1,则从distinNode中移除该点,否则计数减1。通过维护distinNode,这样虽然添加和删除path的时候,复杂度是O(n)但是进行getDistinctNodeCount()的时候,复杂度为O(1),由于总指令数为3000条,而加减path的指令数不超过300条,这样的数据结构是会对整体的复杂度有着不小的提升。
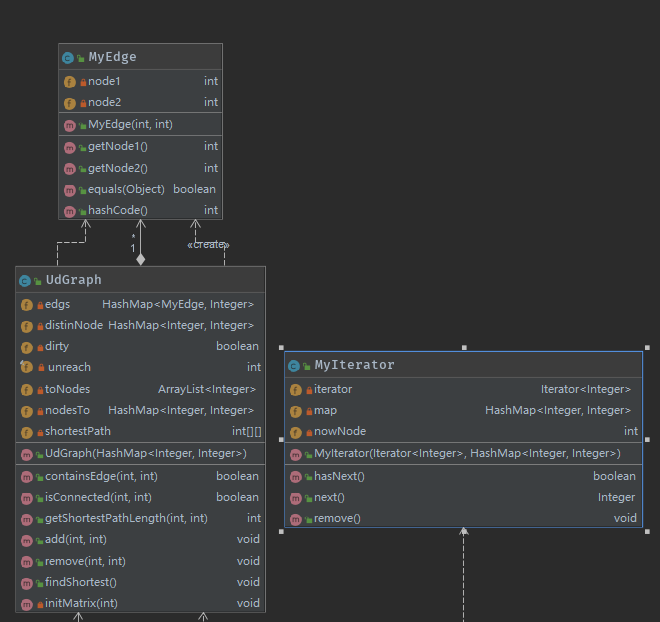
类之间的依赖关系如下图所示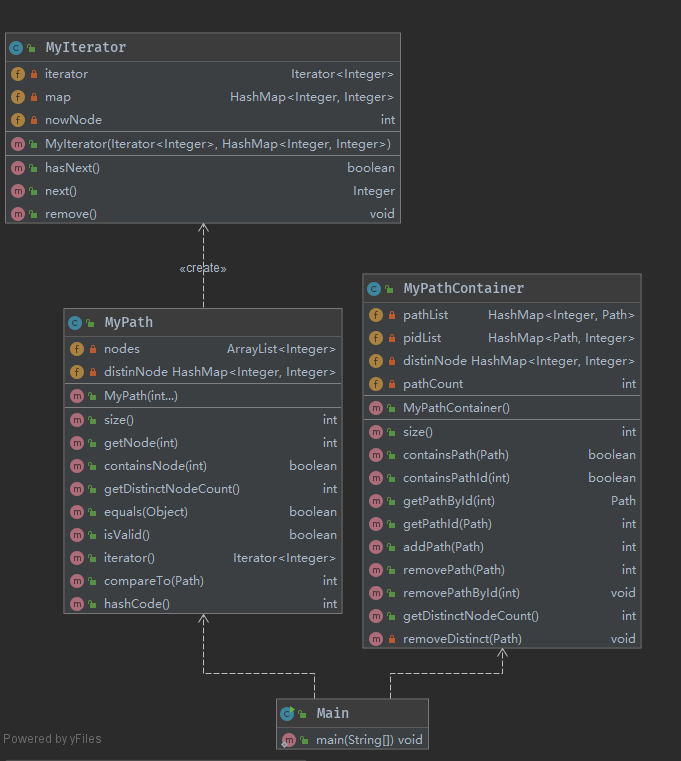
(2)第二次作业 Graph
1.实现思路
由于现在是图,两点之间存在边的关系,所以新建了一个MyEdge类保存点之间的无向偶对,此外还增加了一个新的UdGraph类,是第二次作业新加的函数的真正实现的部分;同时重写addPath()函数,使得除了第一次作业的部分还以边的形式将两个点传入UdGraph类中,UdGraph类里面保存和维护边集。此外,关于最短路径问题,使用的是弗洛伊德算法进行全局的最短路径的查找,然后保存在一个256*256的距离矩阵中,这种算法非常简洁优美。跟第一次作业一样,在添加和删除路径的时候进行一个全局最短路径的查找,其他时候直接访问距离矩阵得到两点之间的距离即可
2.代码架构
在MyGraph类创建的时候,同时创建一个UdGraph类,真正进行边和最短路径的管理,主要目的是对方法进行解耦,方便后续修改,同时方使得类的大小不会太大,其他就没什么可以讲的地方。

3.架构迭代
由于作业会继承上次作业的全部要求,所以这次作业可以使用继承和直接复制上次的代码。由于我们使用的属性都必须是private的,因此如果子类中要对父类中的属性进行调用,父类中必须实现一个public的接口将其传递给子类。同时由于需要对添加和删除path的函数进行重构,所以我是直接将上次作业的代码复制粘贴过来,添加了新的函数的实现,重写了添加和删除的函数。主要是因为这次对于path输入和删除的时候的方式有着很大的变化,所以使用了粘贴的方法。不过现在看来,不需要新添加一个UdGraph类进行新数据的管理,继承第一次作业的PathContainer,将弗洛伊德算法变成静态方法进行调用,只是需要在PathContainer中添加一个将distinNode传递出来的函数就行,只是重写添加和删除Path的函数会相对麻烦一点,不过复杂度不会有太大的改变。
(2)第二次作业 MyRailwaySystem
1.实现思路
使用王嘉仪大佬在讨论中提出的方法,在建立path的时候对path内的各点之间先找出最短路径的权值,然后在不同的path类之间进行组合的时候将之前算出的权值加上换乘之间的权值之后再进行全局最短路径之间的搜索,得到结果后减去一次多加的换乘权值就好,这样子就可以使用弗洛伊德算法,避免迪杰斯特拉算法的贪心算法属性带来的全局最优解与当前最优解矛盾的问题,也比bfs简洁优美。此外对于getConnectedBlockCount()函数,在得到距离矩阵之后使用染色算法会非常方便,复杂度也只是O(n)。
2.代码架构
为了支持这种设计,MyPath在建立的时候要跑一次弗洛伊德,计算最短路径,保存最小不满意度、最短距离,因此Path的建立方法要重写,也是由于类的所有属性都是private类型,所以我直接在之前的原代码上进行修改;不过由于改动不大,所以我的MyRailwaySystem直接继承了MyGraph类,跟第二次作业一样,新建了一个UdrGraph类保存边集和不满意度、换乘次数、票价的距离矩阵,题目要求的函数的具体实现也是在UdrGraph中,具体的类依赖关系如下
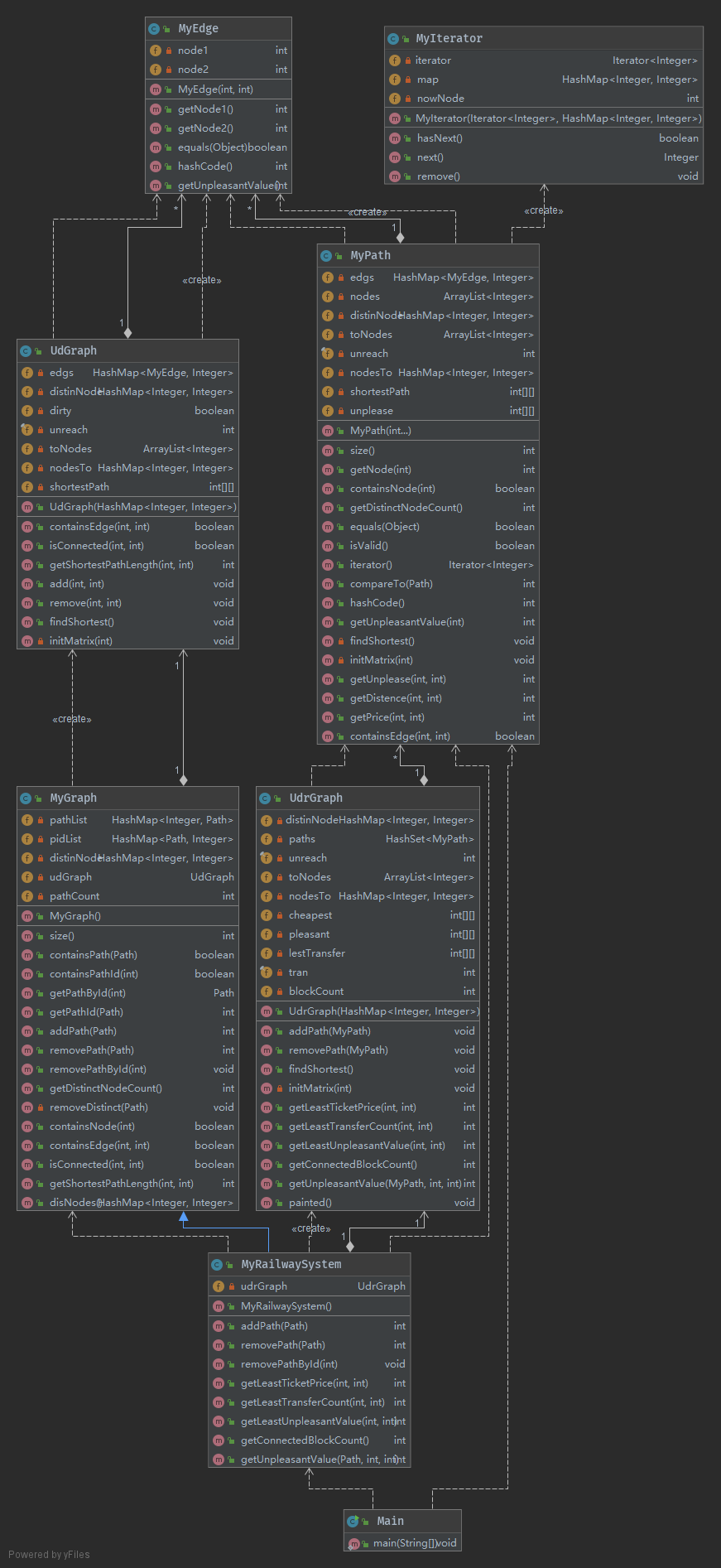
3.架构迭代
跟上一次作业一样,对于一些改动不大,只是需要增加功能的类,比如MyRailwaySystem继承上次作业所写的MyGraph类,像一些改动比较大的类,比如MyPath,没有用继承,直接重构之前的代码,是要是我们规定的属性的类型只能是private,不能是protected,使用继承挺麻烦的,其他还好,UdrGraph和UdGraph类之间的功能比较平行,虽然其中有一部分公用代码,独立成一个类也没什么问题;主要问题就是第二次作业写得弗洛伊德算法没有实现成一个静态类,在MyPath类、UdrGraph类和UdGraph类里面弗洛伊德算法计算全局最短路径的时候有不少重复的代码。
五、bug和修复情况
这次由于是使用jml和契约式编程方法,只要满足jml规定的格式,实际上bug就相对较少,我只在第一次遇到过两个bug,一个是compareTo函数中,由于当两个path之间相同index的node不同时,直接返回node之间的差值,会导致溢出问题;还有就是每次查询不同点的个数都会进行一次遍历,导致TLE,修复过程中主要也是这两种问题。
而第二次第三次作业有了第一次作业的教训,没有出现复杂度问题,也没有会造成溢出的计算,使用的弗洛伊德算法也早就被证明是正确的,所以没有什么bug,我互测也没有测出什么bug,不过同学遇到过删除时,数据之间的依赖关系没有整理好,导致删除路径的时候删除了点集,而删除边集则需要依赖点集因此带来的问题。
六、心得与体会
这次使用的jml这种语言进行规格设计和契约式编程设计是一种从未有过的体验,让我对工业化编程有了更多的了解。而且通过编写规格,我能够更多的从功能设计的角度上去思考一个方法,从需求出发,先对方法要实现的功能进行比较全面的考虑,再对方法进行设计寻找合适的算法那,而不是像以前一样从实现出发,对于方法的设计是在实现的过程中逐步完善的,这样子我编写代码的时候考虑的会更加周到,而且只要保证方法的规格不变,规格的具体实现进行重构的成本也非常低,不会涉及到整体结构的大范围修改,对于代码的迭代和类之间的去耦也非常有用。
总之,这次对于规格的学习让我对于程序员实际的工作方式有了更深的了解,也让我的代码的设计有了不小的提升。
七、一点吐槽
虽然课程已经结束了,不过还是对于这次的规格的学习给一些反馈,希望能够对课程的改进有一些帮助。
(1)openJML的问题,下次如果还需要jml的检测和自动化验证工具最好换一个,openJML对于数据规格限制的太过死板,而且也不支持forall、exist这类语法,新版的idea还不支持,希望之后能够换一种。
(2)checkstyle中对于属性类型的限制,能不能把protected也加进来,很多时候我想对之前的代码进行继承,但是父类中的一些变量是private类,对其进行管理就非常麻烦,所以就没有使用继承而是直接修改代码或者复制粘贴,希望以后能够使用protected类型的变量,这样使用继承的时候会方便很多。