以下内容来自小马哥视频学习笔记。
------------------------------------------------------------------------------------------------------------------------------------------------------------------
part 1 索引的原理:把无序的数据变成有序的查询。
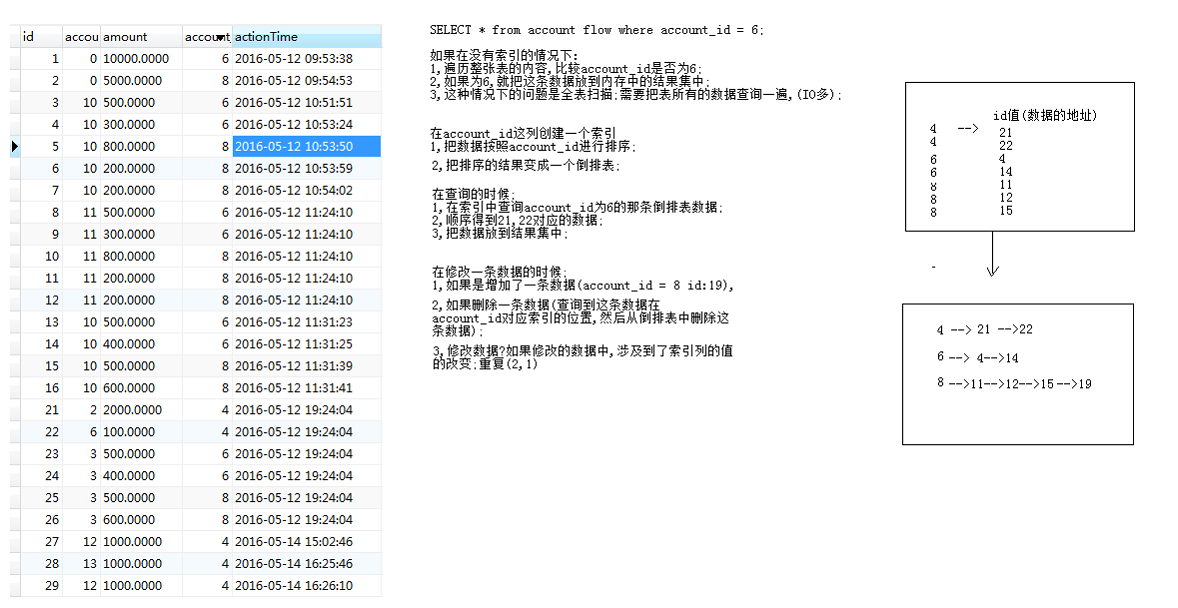
part 2 索引的物理结构:
1,数据库文件存储的位置:my.ini配置文件中dataDir对应的数据目录中;
2,每一个数据库一个文件夹;
1)MYISAM引擎:每一个表(table_name)-->
table_name.MYI:存放的是数据表对应的索引信息和索引内容;
table_name.FRM:存放的是数据表的结构信息;
table_name.MYD:存放的是数据表的内容;
2)InnoDB引擎:每一个表(table_name)-->
table_name.frm:存放的是数据表的结构信息;
数据文件和索引文件都是统一存放在ibdata文件中;
3)索引文件都是额外存在的,对索引的查询和维护都是需要消耗IO的;
part 3 索引的结构:
1,默认情况下,创建的表如果设置了主键,mysql会为该主键创建一个unique索引。
2,索引类型:
1)normal:普通索引,一个索引值后面可以关联多行数据。如上图倒排表所示。
2)unique:唯一索引,一个索引后面只能有一行数据。对列添加唯一约束,即为这列添加了unique索引;主键是非空加唯一约束,即有一个unique索引。
3)fulltext:全文检索,mysql中只能用myisam引擎,且性能低,不建议使用。
3,索引的方法:
1)b-tree:是mysql中使用最多的索引类型,在innodb中,存在两种索引类型,第一种是主键索引(primary key),在索引内容中直接保存数据的地址;
第二种是普通索引,在索引内容中保存的是指向主键索引的引用;所以在使用innodb的时候,要尽量的使用主键索引,速度非常快; b-tree中保存的数据
都是按照一定顺序保存的数据,是可以允许在范围之内进行查询;

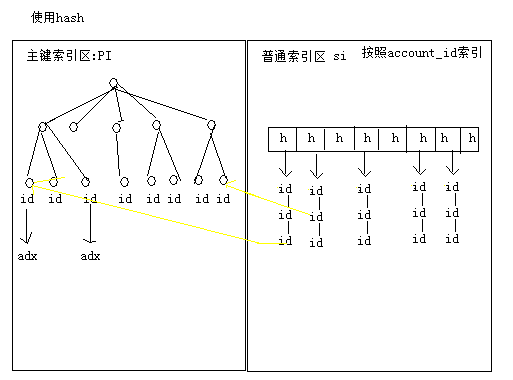
2)hash:把索引值做hash运算,存放hash表中。
优点:因为使用hash表存储,按照常理,hash的性能比B-TREE效率高很多。
缺点:1,hash索引只能适用于精确的值比较,=,in,或者<>;无法使用范围查询; 2,无法使用索引排序;
3,组合hash索引无法使用部分索引; 4,如果大量索引hash值相同,性能较低;
part 4 使用索引的利弊:
利:提高检索效率,如果排序的列或者分组的列刚好也是索引列,可以极大提高排序成本。
弊:额外的维护成本。索引文件是单独存在的文件,对数据增删改都需要更新相关的索引文件,降低增删改效率。
创建索引原则:a 频繁作为查询条件的字段适合 b唯一性太差的列,不能有效区分数据,不适合,比如性别 c 频繁更新的字段不适合,增加维护成本
d 不会出现在where子句中的字段不适合 e 只为必要的列创建索引:一次查询最多用一个索引,索引之间是独立的,所有索引都需要单独维护
part 5 索引的使用限制
1 BLOB 和TEXT 类型的列只能创建前缀索引
2 MySQL 目前不支持函数索引(索引只能是一个列的原始值,不能把列通过计算的值作为索引)
实例:请查询1981年入职的员工: SELECT * FROM emp WHERE year(hire_date)='1981'; 问题:查询的列是在过滤之前经过了函数运算;所以,就算hire_date作
为索引,year(hire_date)也不会使用索引; 解决方案: a SELECT * FROM emp WHERE hire_date BETWEEN '1981-01-01' AND '1981-12-31';
b,在创建一列,这列的值是year(hire_date),然后把这列的值作为索引;
3 使用不等于(!= 或者<>)的时候MySQL 无法使用索引
4 过滤字段使用了函数运算后(如abs(column)),MySQL 无法使用索引
5 Join 语句中Join 条件字段类型不一致的时候MySQL 无法使用索引
6 使用LIKE 操作的时候如果条件以通配符开始( '%abc...')MySQL 无法使用索引
1,字符串是可以用来作为索引的;
2,字符串创建的索引按照字母顺序排序;
3,如果使用LIKE,实例:SELECT * FROM userinfo WHERE realName LIKE '吴%';这种情况是可以使用索引的; 但是LIKE '_嘉' 或者LIKE '%嘉'都是不能使用索引的;
7 使用非等值查询的时候MySQL 无法使用Hash 索引
part 6 复合索引:
一次查询至多只能使用一个索引,所以,如果都使用单值索引(一个列一个索引),在数据量较大的情况下,不能很好的区分数据,MYSQL引入了多值索引(复合索引);
复合索引的原理:就是类似orderby(orderby后面可以跟多个排序条件order by hire_date,username desc);
复合索引,在查询的时候,遵守向左原则;
举例:
SELECT * FROM accountflow WHERE actionTime < 'xxxxx' AND account_id = 5 可以使用actionTime+account_id的复合索引;
SELECT * FROM accountflow WHERE actionTime < 'xxxxx' 可以使用actionTime+account_id的复合索引;
SELECT * FROM accountflow WHERE account_id = 5 不可以使用actionTime+account_id的复合索引;
SELECT * FROM accountflow WHERE account_id = 5 AND actionTime < 'xxxxx' 不可以使用actionTime+account_id的复合索引;