看完国外一个APM厂商最后的一个业务介绍视频,终于想通了PE领域中最顶层的应用目标,也就是如标题所云。那么这个影响效果是如何做到的?最终的步骤其实很简单,也就是利用大数据进行分析。而自己先前还没有想到利用可视化的数据建模去做这个分析,数据可视化的概念促成了我可以通过不同的角度、维度去了解、度量软件系统性能是如何影响终端用户体验,甚至是如何影响公司营收的。
显然,要完成上面的事情,数据采集是最重要的步骤。基本上所有的公司都会进行各种各样的数据采集,但是问题同样也来了,以何种方式采集数据、需要采集什么样的数据在这些公司都是缺乏指引的,很多最终做成了四不像、既不是EUM或者RUM、也不是APM或者BSM。
采集数据的方式基本上分两种:静态插桩和动态插桩。静态插桩的优点是精确,可以在你需要的任何代码片段中插入。但是缺点也显而易见,对代码侵入性非常强,任何新开发的功能特性如需采集都需要重新加入桩,有时候盲目插入的桩可能随着业务变动而需要变更或者需要移除,以至于测试人员甚至需要对这些插桩本身进行测试。动态插桩的优缺点基本跟静态插桩是互补的,但当作为动态插桩的插件开发的比较全面合理时,基本是能够满足精确度要求。只是相应的成本也要高,所以一般中小型公司都会为了所谓的速度而采取简单的静态插桩方式。
接下来,对于需要采集什么样的数据更是五花白门,估计大部分公司都是由决策层和业务部门直接决定,基本不会和其他部门进行沟通。但业务部门一般仅仅采集跟业务相关的指标,关心业务的达成率、金额等等,对于客户端的延迟、请求的稳定性以及服务端的TPS、应用和系统资源漠不关心。
这些缺乏指引的策略就像化功散一样无形中对公司造成了非常大的伤害。
案例1,业务部门得到报警:某段时间注册用户数量骤降,以此来驱动技术部门来排查此问题,然后果然发现是注册服务出了问题。到这里,你可能还在想这样看上还挺不错,可以通过监控报警来了解线上状况。可是其实从注册服务真正出现问题到通过业务报警这中间是隔了一段不短的时间,有时候可能长达一个星期,相比我后面要说的,这种预警实在太后置了。
案例2,线上应用到数据库的连接泄露,导致数据库连接池爆满,此时部分用户在终端进行的业务操作会失败或超时,导致服务不可用的假象,一段时间后自然恢复,但是此问题周而复始,导致用户使用信心下降,活跃用户变为非活跃用户,甚至流失。此种情况业务方面采集到的数据根本反应不出来,统计和预警是失效的。
上面的两个案例告诉我们,光有业务指标采集是远远不够的,还有性能、可用性、可靠性、稳定性等多方面的数据需要收集,即使是业务本身,也需要进行更精细化的分解、比如支付,在业务中关心笔数、金额、成功率等,在APM中是作为一个transaction,如为了完成支付可能会调用到多个服务或者API,那么每一个环节的调用我们可以定义为一个event,同时在数据采集的时候会进行端到端、全链路的采集。
下面,通过一个APM厂商成熟的产品来展示下假如上面我们都做到了这些数据可以用来做什么。
不同请求的延迟:
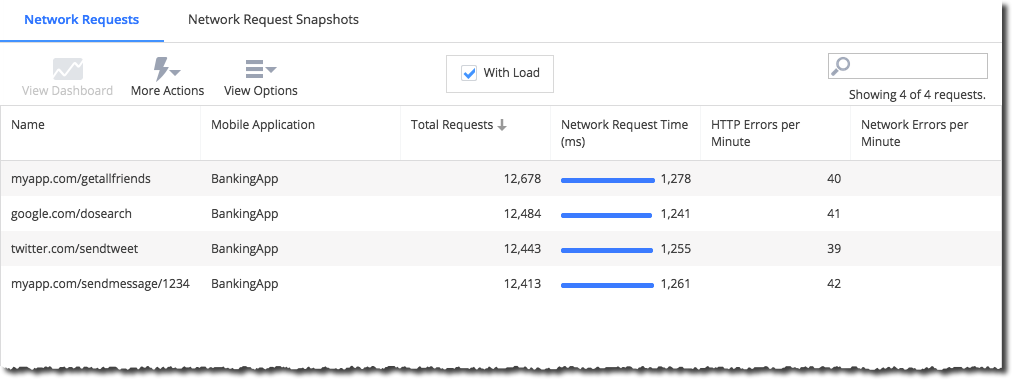
延迟分析:
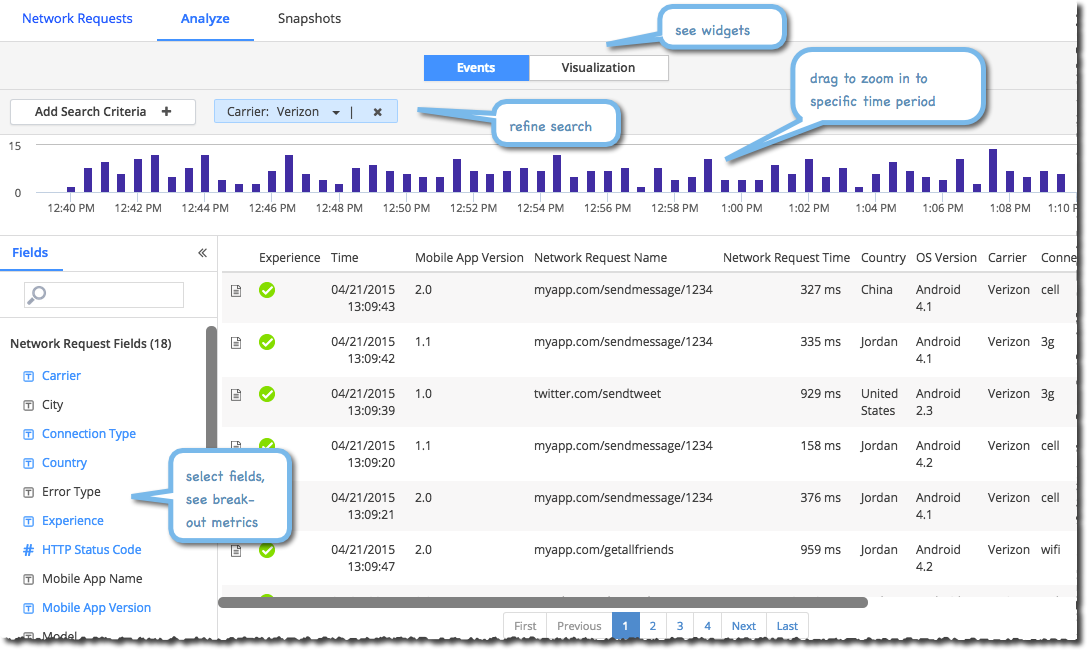
Http error的统计:
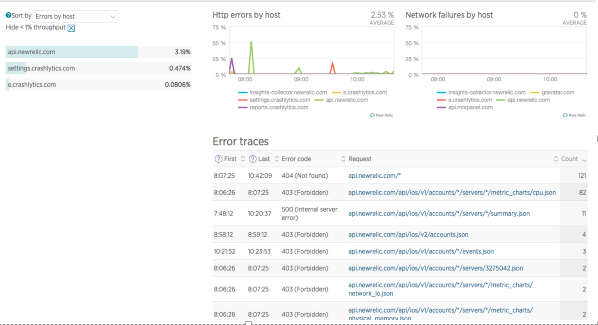
crash统计:

以上都是EUM方面的东西,接下来看看在APM收集到的数据都可以做到些什么。

做微服务的同学会发现,这里基本包含了Hystrix dashboard的所有东西,当然也更强大,可以从APM通过跟踪服务构建的拓扑图上更直观的看到性能数据,包括响应时间、调用速率、可靠性等。
单个transaction分析:
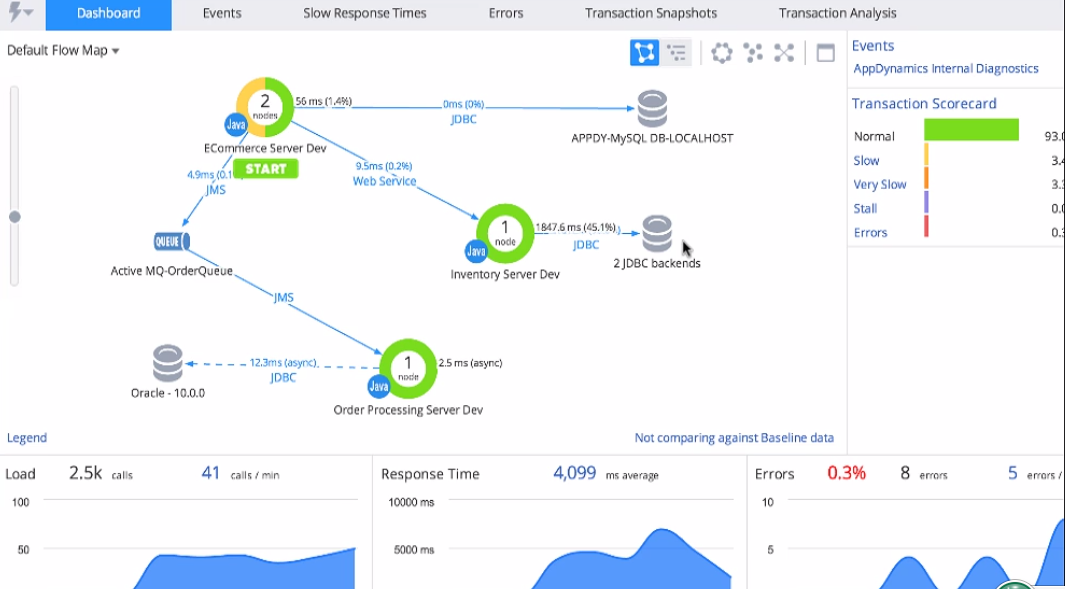
如果说上面的数据解决了实际的问题,那么接下来的可视化数据分析展示了这些数据更深层次的应用。

通过拟合不同的数据来了解性能跟营收之间的关系。
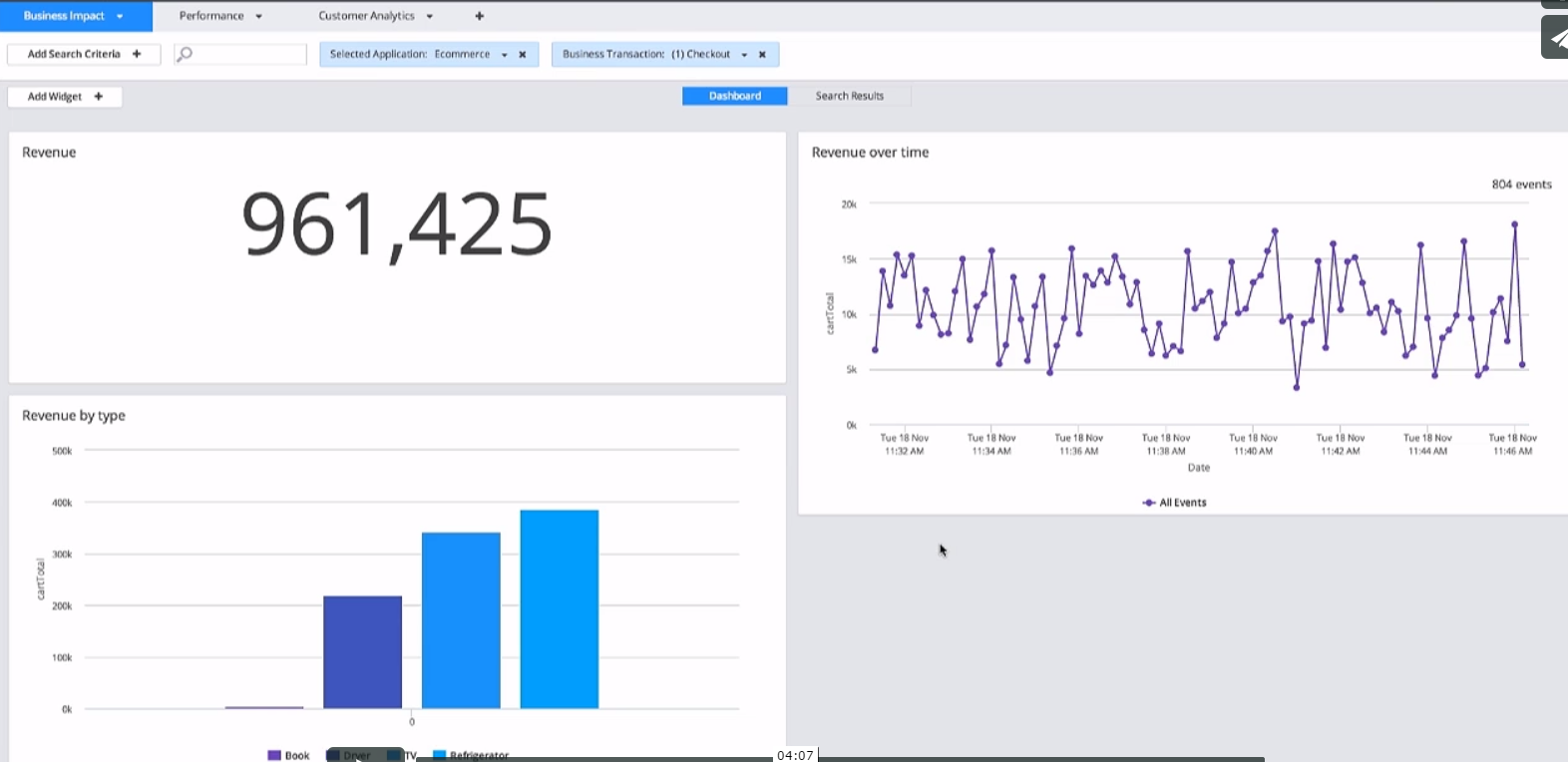
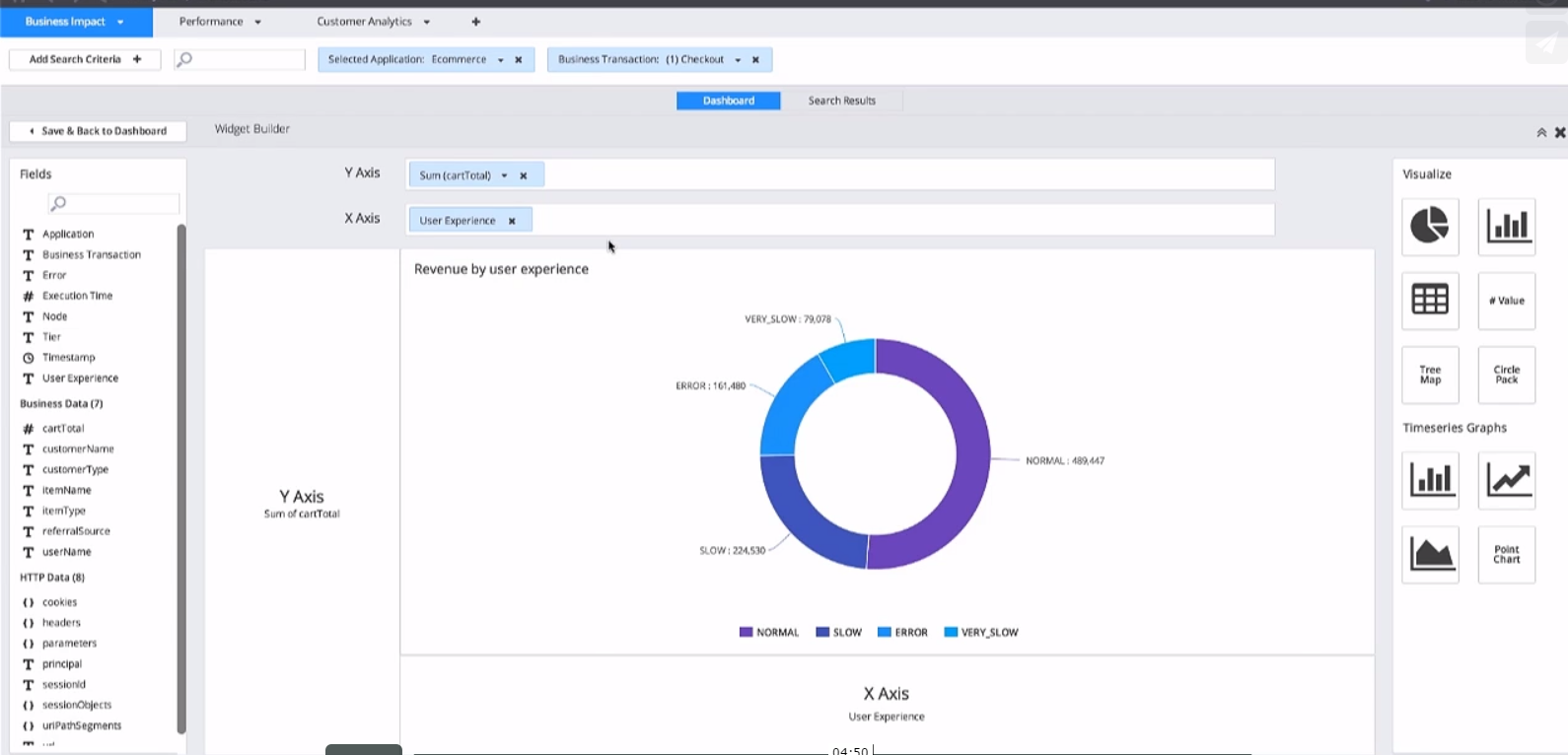
总结,我这里并不是推销APM产品,实际上总是先有这样的需求和思想,然后才有产品,所以只有理解软件性能工程的真正目的,并且思考如何解决现实业务问题,不断move forward,才可能达到最后通过数据分析规避或降低损失的目的。