一、面向对象编程
(一)什么是面向对象编程
面向对象编程是一种编程套路,我们可以来跟面向过程编程做个对比。
1.面向过程编程
面向过程编程的核心是过程,过程指的是做事的步骤,即做事的先后顺序,基于该思想编写的程序,就相当于一条条流水线。
(1)优点
复杂的问题流程化,进而变得简单化。
(2)缺点
扩展性差。
2.面向对象编程
面向对象编程的核心是对象,对象就是一个用来盛放/整合相关数据与相关功能的容器。
(1)优点
程序解耦合强,扩展性好。
(2)缺点
比面向过程复杂,不适合扩展性低的使用场景,容易出现过度设计的问题。
(二)类与对象的使用
1.类与对象是什么
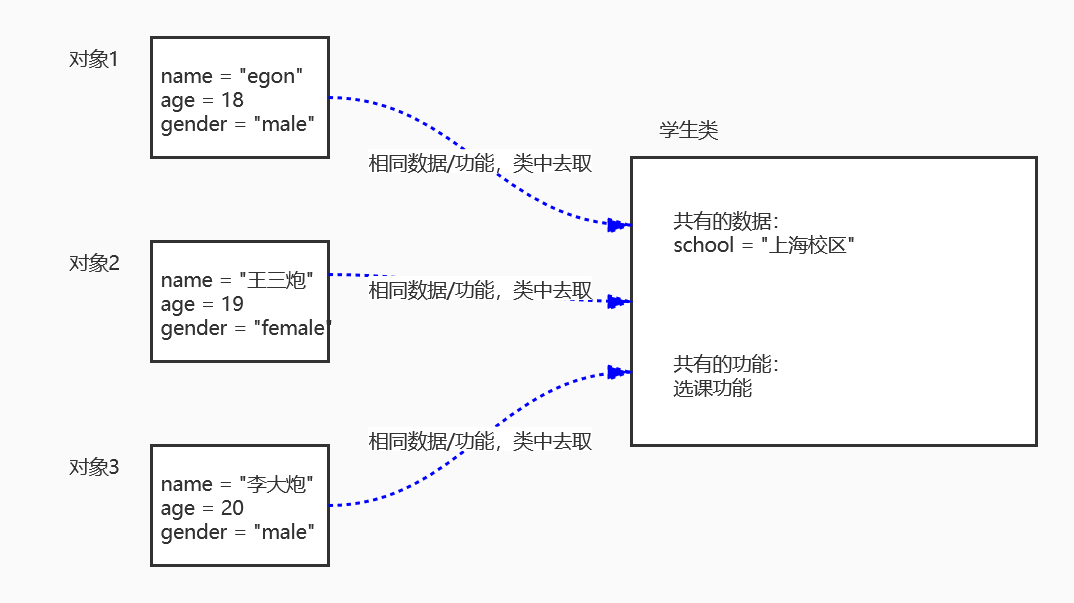
类即类别/种类,是面向对象设计最重要的概念,对象是数据与功能的集合体,而类则是对象之间相同数据与功能的集合体。
对象1:
# 学生1的数据
name = "egon"
age = 18
gender = "male"
对象2:
# 学生2的数据
name = "王三炮"
age = 19
gender = "female"
对象3:
# 学生3的数据
name = "李大炮"
age = 20
gender = "male"
学生类:
# 学生对象相同的数据
school = "上海校区"
# 学生对象相同的功能
选课功能
2.类的定义与使用
(1)在程序中必须先定义(类)
定义类就是申请内存空间,把对象之间共同的数据与功能存起来。
类在定义的时候就会立即执行类体代码,会产生类的名称空间,然后类名指向该名称空间。
class Student:
school = "上海校区"
def choose_course(self):
print("正在选课")
# 代码定义后会立即执行
print("====>") # ====>
#
print(Student.__dict__) # {'__module__': '__main__', 'school': '上海校区', 'choose_course': <function Student.choose_course at 0x0000016AE4258040>, '__dict__': <attribute '__dict__' of 'Student' objects>, '__weakref__': <attribute '__weakref__' of 'Student' objects>, '__doc__': None}
需要注意的点:
1)类中可以有任意python代码,这些代码在类定义阶段便会执行;
2)因而会产生新的名称空间,用来存放类的变量名与函数名,可以通过Student.__dict__查看
3)点是访问属性的语法,类中定义的名字,都是类的属性
(2)后使用(产生对象)
调用类来产生对象,调用类的过程又称之为实例化。
调用类的本质:产生一个与类相关联的子空间。
# 定义完类之后,接下来就是调用类来产生对象
stu1 = Student() # 实际上相当于创建了一个空对象 <__main__.Student object at 0x00000228F1CE5B50> print(stu1.__dict__) {}
stu2 = Student()
stu3 = Student()
stu1.__dict__["name"] = "egon" # 对象调用.__dict__功能,用来保存对象属性变量的键值对
# stu1.name = "egon" # 简化下来可以这样写,本质上实现的功能是一样的
stu1.__dict__["age"] = 18
# stu1.age = 18
stu1.__dict__["gender"] = "male"
# stu1.gender = "male"
print(stu1.__dict__) # {'name': 'egon', 'age': 18, 'gender': 'male'}
(三)详解.__ init __方法以及属性操作
1.使用.__ init __方法
python为类内置了一系列特殊属性:
# 常用的内置属性
类名.__name__# 类的名字(字符串)
类名.__doc__# 类的文档字符串
类名.__base__# 类的第一个父类(在讲继承时会讲)
类名.__bases__# 类所有父类构成的元组(在讲继承时会讲)
类名.__dict__# 类的字典属性
类名.__module__# 类定义所在的模块
类名.__class__# 实例对应的类(仅新式类中)
类的其他特殊属性
在调用类的过程中,我们需要给对象定制各自独有的属性,在类实例化之后再增加属性过于繁琐,所以python提供了在类内部增加__ init __ 方法,可以在实例化(调用类)的过程中就为对象初始化、传值。
class Student:
school = "上海校区"
# 空对象,"egon",18,"male"
def __init__(self, x, y, z):
self.name = x # 空对象.name="egon"
self.age = y # 空对象.age=18
self.gender = z # 空对象.gender="male"
# print("===>")
# 该函数内可以有任意代码,但是该函数不能返回非None值
# return 123
# stu1
def choose_course(self):
print('%s 正在选课' %self.name)
def func(self,x,y):
print(self.name,x,y)
stu1 = Student("egon",18,"male")
stu2 = Student("王三炮",19,"female")
stu3 = Student("李大炮",20,"male")
# 调用类的过程:
# 1、会先创造一个与类相关联的子空间,也就对象=》空对象
# 2、自动触发类内__init__(空对象,"egon",18,"male")
# 3、返回一个初始化好的对象,我们可以赋值给一个变量名
2.类属性操作
类与对象都可以通过 . 来访问属性来完成增删改查的操作
(1)访问类的数据属性
Student.school = "Shanghai" # 修改类的属性
Student.xxx = 111 # 增加类的属性
del Student.xxx # 删除类的属性
(2)访问类的函数属性
类的函数它就是一个普通函数,该传几个参数就传几个参数。
print(Student.choose_course) # <function Student.choose_course at 0x00000228E5628280>
Student.choose_course(stu1) # egon 正在选课 传入参数后立即执行
3.对象属性操作
(1)属性查找顺序:
对象_._属性,会先从对象自己的空间里找,没有的话去类里面找。
(2)类中的定义的数据属性为了给对象用的,而且是所有对象共享,大家访问的都是同一个地址。
print(id(Student.school)) # 1702345007920
print(id(stu1.school)) # 1702345007920
print(id(stu2.school)) # 1702345007920
print(id(stu3.school)) # 1702345007920
Student.school = "!!!" # 修改类的数据属性,所有对象都会跟着修改
print(stu1.school) # !!!
print(stu2.school) # !!!
stu1.school = "YYY" # 修改对象的数据属性,其他对象以及类都不会发生变化
print(stu1.__dict__) # {'name': 'egon', 'age': 18, 'gender': 'male', 'school': 'YYY'}
print(stu1.school) # YYY
print(Student.school) # !!!
print(stu2.school) # !!!
print(stu3.school) # !!!
(3)类中的定义的函数属性,类可以调用,但就是一个普通函数,而类中函数通常都是为对象准备的,也就是说是给对象用的,如何给对象用?绑定给对象。
# 绑定的方法
print(Student.choose_course) # <function Student.choose_course at 0x0000023962238280>
print(stu1.choose_course) # <bound method Student.choose_course of <__main__.Student object at 0x0000023962225B50>>
stu1.choose_course() # choose_course(stu1) egon 正在选课
stu2.choose_course() # choose_course(stu2) 王三炮 正在选课
stu3.choose_course() # choose_course(stu3) 李大炮 正在选课
stu1.func(18,"male") # egon 18 male
二、常用内置函数补充
(一)eval()
用来执行一个字符串表达式,并返回表达式的值
>>> n=81
>>> eval("n + 4")
85
dic={"k1":111}
with open('a.txt',mode='wt',encoding='utf-8') as f:
f.write(str(dic))
with open('a.txt',mode='rt',encoding='utf-8') as f:
line=f.read() # line="{'k1': 111}"
# print(type(line)) # <class 'str'>
line=eval(line)
print(line['k1']) # 111
(二)forzenset()
s=frozenset({1,2,3})
print(s) # frozenset({1, 2, 3})
(三)pow()
函数是计算x的y次方,如果z在存在,则再对结果进行取模,其结果等效于pow(x,y) %z
print(pow(10, 3)) # 1000 # 10 ** 3
print(pow(10, 3, 3)) # 1 # 10 ** 3 % 3
(四)reversed()
reversed 函数返回一个反转的迭代器。
l=[111,'aaa',333]
res=reversed(l)
print(res) # <list_reverseiterator object at 0x0000020AFE87F0D0>
for x in res:
print(x) # 333
# aaa
# 111
l=list(reversed(l))
print(l) # [333, 'aaa', 111]
(五)round()
round() 将一个数字四舍五入到给定的十进制精度中,默认精度是小数点后0位。
print(round(4.6)) # 5
print(round(4.5)) # 4
(六)slice()
切片函数操作
l=[111,222,333,44,555,666,777,888]
s=slice(0,5,2)
print(l[0:5:2]) # 0 2 4 [111, 333, 555]
print(l[s]) # 0 2 4 [111, 333, 555]
msg="hello world"
print(msg[s]) # hlo
(七)sorted()
返回一个新的列表,其中包含来自可迭代对象的所有元素,并默认按升序排列。
# 语法:
sorted(iterable, cmp=None, key=None, reverse=False)
# 参数:
1)iterable -- 可迭代对象。
2)cmp -- 比较的函数,这个具有两个参数,参数的值都是从可迭代对象中取出,此函数必须遵守的规则为,大于则返回1,小于则返回-1,等于则返回0。
3)key -- 主要是用来进行比较的元素,只有一个参数,具体的函数的参数就是取自于可迭代对象中,指定可迭代对象中的一个元素来进行排序。
4)reverse -- 排序规则,reverse = True 降序 , reverse = False 升序(默认)。
l = [444, 111, 222, 555, 666, 333, 777, 888]
new_l = sorted(l)
print(new_l) # [111, 222, 333, 444, 555, 666, 777, 888]
dic={
'zegon':3000,
"lxx":2000,
'axx':4000
}
res=sorted(dic,key=lambda x:dic[x],reverse=True)
print(res) # ['axx', 'zegon', 'lxx']
(八)sum()
求和函数,第二个元素用于相加
# 语法:
sum(iterable[, start])
# 参数:
1)iterable -- 可迭代对象,如:列表、元组、集合。
2)start -- 指定相加的参数,如果没有设置这个值,默认为0。
>>>sum([0,1,2])
3
>>> sum((2, 3, 4), 1) # 元组计算总和后再加 1
10
>>> sum([0,1,2,3,4], 2) # 列表计算总和后再加 2
12
(九)zip()
函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的对象(python2中直接返回列表),这样做的好处是节约了不少的内存。我们可以使用 list() 转换来输出列表。
msg = {"name": "egon"}
l = [111, 222, 333]
res = zip(msg, l)
print(list(res)) # [('name', 111)]
msg = "hello"
l = [111, 222, 333]
res = zip(msg, l)
print(res) # <zip object at 0x0000012F071D1680>
print(list(res)) # [('h', 111), ('e', 222), ('l', 333)]