在代码实现上,线程的实现与进程的实现很类似,创建对象的格式都差不多,然后执行的时候都是用到start()方法,与进程的区别是进程是资源分配和调度的基本单位,而线程是CPU调度和分派的基本单位。其中多线程的模块处于threading 中的Thread。
多线程实现例子
#coding=utf-8
import threading
import time
def saySorry():
print("吃饭睡觉打豆豆")
time.sleep(1)
if __name__ == "__main__":
for i in range(5):
t = threading.Thread(target=saySorry)
t.start() #启动线程,即让线程开始执行执行可以看到,虽然第六行有time.sleep(1)这一句,但是最终打印基本是同时出现的。
吃饭睡觉打豆豆
吃饭睡觉打豆豆
吃饭睡觉打豆豆
吃饭睡觉打豆豆
吃饭睡觉打豆豆注意:主线程会等待子线程结束而结束,主线程结束标志是程序运行返回初始状态,而不是说打印出程序最后一行的代码。
length = len(threading.enumerate())可用来查看当前线程数量。
自定义类来继承Thread从而实现线程
#coding=utf-8
import threading
import time
class MyThread(threading.Thread):
def run(self):
for i in range(3):
time.sleep(1)
msg = "I'm "+self.name+' @ '+str(i) #name属性中保存的是当前线程的名字
print(msg)
if __name__ == '__main__':
t = MyThread()
t.start()运行结果:
I'm Thread-1 @ 0#间隔1秒打印下一句
I'm Thread-1 @ 1#间隔1秒打印下一句
I'm Thread-1 @ 2结论:python的threading.Thread类有一个run方法,用于定义线程的功能函数,可以在自己的线程类中覆盖该方法。而创建自己的线程实例后,通过Thread类的start方法,可以启动该线程,交给python虚拟机进行调度,当该线程获得执行的机会时,就会调用run方法执行线程。
线程的执行顺序
#coding=utf-8
import threading
import time
class MyThread(threading.Thread):
def run(self):
for i in range(3):
time.sleep(1)
msg = "I'm "+self.name+' @ '+str(i)
print(msg)
def test():
for i in range(5):
t = MyThread()
t.start()
if __name__ == '__main__':
test()执行结果:
I'm Thread-1 @ 0
I'm Thread-2 @ 0
I'm Thread-5 @ 0
I'm Thread-3 @ 0
I'm Thread-4 @ 0
I'm Thread-3 @ 1
I'm Thread-4 @ 1
I'm Thread-5 @ 1
I'm Thread-1 @ 1
I'm Thread-2 @ 1
I'm Thread-4 @ 2
I'm Thread-5 @ 2
I'm Thread-2 @ 2
I'm Thread-1 @ 2
I'm Thread-3 @ 2结论说明
从代码和执行结果我们可以看出,多线程程序的执行顺序是不确定的。当执行到sleep语句时,线程将被阻塞(Blocked),到sleep结束后,线程进入就绪(Runnable)状态,等待调度。而线程调度将自行选择一个线程执行。上面的代码中只能保证每个线程都运行完整个run函数,但是线程的启动顺序、run函数中每次循环的执行顺序都不能确定。
- 每个线程一定会有一个名字,尽管上面的例子中没有指定线程对象的name,但是python会自动为线程指定一个名字。
- 当线程的run()方法结束时该线程完成。
- 无法控制线程调度程序,但可以通过别的方式来影响线程调度的方式。
- 线程的几种状态
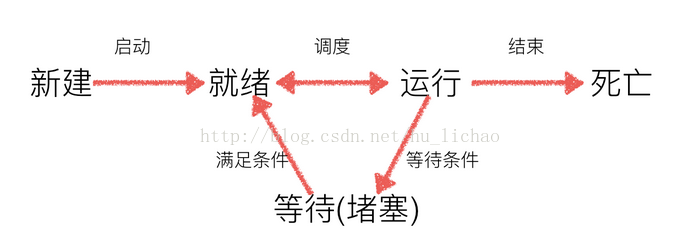
其他关于线程的重要知识点
各个线程共享全局变量和列表,这个正好与进程相反。用法上,单个变量需要用global来声明,而列表不需要。正因为共享全局变量和列表,所以缺点就是可能会造成线程不安全。
线程与进程的区别
-
一个程序至少有一个进程,一个进程至少有一个线程.
-
线程的划分尺度小于进程(资源比进程少),使得多线程程序的并发性高。
-
进程在执行过程中拥有独立的内存单元,而多个线程共享内存,从而极大地提高了程序的运行效率
-
线线程不能够独立执行,必须依存在进程中
-
线程和进程在使用上各有优缺点:线程执行开销小,但不利于资源的管理和保护;而进程正相反。
线程同步与互斥
正因为线程的不安全性,所以在具体应用时可能会发生死锁或者与预想结果不同的各种问题。python中提供了锁类机制,它是threading中的Lock模块。acquire()是锁上方法,relase()是释放方法。
from threading import Thread,Lock
from time import sleep
class Task1(Thread):
def run(self):
while True:
if lock1.acquire():
print("------Task 1 -----")
sleep(0.5)
lock2.release()
class Task2(Thread):
def run(self):
while True:
if lock2.acquire():
print("------Task 2 -----")
sleep(0.5)
lock3.release()
class Task3(Thread):
def run(self):
while True:
if lock3.acquire():
print("------Task 3 -----")
sleep(0.5)
lock1.release()
#使用Lock创建出的锁默认没有“锁上”
lock1 = Lock()
#创建另外一把锁,并且“锁上”
lock2 = Lock()
lock2.acquire()
#创建另外一把锁,并且“锁上”
lock3 = Lock()
lock3.acquire()
t1 = Task1()
t2 = Task2()
t3 = Task3()
t1.start()
t2.start()
t3.start()运行结果:
------Task 1 -----
------Task 2 -----
------Task 3 -----
------Task 1 -----
------Task 2 -----
------Task 3 -----
------Task 1 -----
------Task 2 -----
-----------省略----------生产者消费者模式
首先来理解什么是生产者消费者呢?
生产者消费者模式是通过一个容器来解决生产者和消费者的强耦合问题。生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯,所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,而是直接从阻塞队列里取,阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力。
这个阻塞队列就是用来给生产者和消费者解耦的。纵观大多数设计模式,都会找一个第三者出来进行解耦,如工厂模式的第三者是工厂类,模板模式的第三者是模板类。在学习一些设计模式的过程中,如果先找到这个模式的第三者,能帮助我们快速熟悉一个设计模式。
Python的Queue模块中提供了同步的、线程安全的队列类,包括FIFO(先入先出)队列Queue,LIFO(后入先出)队列LifoQueue,和优先级队列PriorityQueue。这些队列都实现了锁原语(可以理解为原子操作,即要么不做,要么就做完),能够在多线程中直接使用。可以使用队列来实现线程间的同步。
#encoding=utf-8
import threading
import time
#python2中
from Queue import Queue
#python3中
# from queue import Queue
class Producer(threading.Thread):
def run(self):
global queue
count = 0
while True:
if queue.qsize() < 1000:
for i in range(100):
count = count +1
msg = '生成产品'+str(count)
queue.put(msg)
print(msg)
time.sleep(0.5)
class Consumer(threading.Thread):
def run(self):
global queue
while True:
if queue.qsize() > 100:
for i in range(3):
msg = self.name + '消费了 '+queue.get()
print(msg)
time.sleep(1)
if __name__ == '__main__':
queue = Queue()
for i in range(500):
queue.put('初始产品'+str(i))
for i in range(2):
p = Producer()
p.start()
for i in range(5):
c = Consumer()
c.start()- 对于Queue,在多线程通信之间扮演重要的角色
- 添加数据到队列中,使用put()方法
- 从队列中取数据,使用get()方法
- 判断队列中是否还有数据,使用qsize()方法
线程使用自己的局部变量,在单个线程的多个参数之间传递参数
在多线程环境下,每个线程都有自己的数据。一个线程使用自己的局部变量比使用全局变量好,因为局部变量只有线程自己能看见,不会影响其他线程,而全局变量的修改必须加锁。
有三种方法,第一种是参数传递。这样很麻烦
def process_student(name):
std = Student(name)
# std是局部变量,但是每个函数都要用它,因此必须传进去:
do_task_1(std)
do_task_2(std)
def do_task_1(std):
do_subtask_1(std)
do_subtask_2(std)
def do_task_2(std):
do_subtask_2(std)
do_subtask_2(std)
第二种是全局字典,利用每个线程作为字典的key,也即利用空间换安全的思想。
global_dict = {}
def std_thread(name):
std = Student(name)
# 把std放到全局变量global_dict中:
global_dict[threading.current_thread()] = std
do_task_1()
do_task_2()
def do_task_1():
# 不传入std,而是根据当前线程查找:
std = global_dict[threading.current_thread()]
...
def do_task_2():
# 任何函数都可以查找出当前线程的std变量:
std = global_dict[threading.current_thread()]
...主要介绍第三种方法,第三种方式才是正确打开方式,那就是使用ThreadLocal方法
import threading
# 创建全局ThreadLocal对象:
local_school = threading.local()
def process_student():
# 获取当前线程关联的student:
std = local_school.student
print('Hello, %s (in %s)' % (std, threading.current_thread().name))
def process_thread(name):
# 绑定ThreadLocal的student:
local_school.student = name
process_student()
t1 = threading.Thread(target= process_thread, args=('小哥',), name='Thread-A')
t2 = threading.Thread(target= process_thread, args=('吴邪',), name='Thread-B')
t1.start()
t2.start()
t1.join()
t2.join()运行结果:
Hello, 小哥 (in Thread-A)
Hello, 吴邪 (in Thread-B)结论:
全局变量local_school就是一个ThreadLocal对象,每个Thread对它都可以读写student属性,但互不影响。你可以把local_school看成全局变量,但每个属性如local_school.student都是线程的局部变量,可以任意读写而互不干扰,也不用管理锁的问题,ThreadLocal内部会处理。
可以理解为全局变量local_school是一个dict,不但可以用local_school.student,还可以绑定其他变量,如local_school.teacher等等。
ThreadLocal最常用的地方就是为每个线程绑定一个数据库连接,HTTP请求,用户身份信息等,这样一个线程的所有调用到的处理函数都可以非常方便地访问这些资源。
一个ThreadLocal变量虽然是全局变量,但每个线程都只能读写自己线程的独立副本,互不干扰。ThreadLocal解决了参数在一个线程中各个函数之间互相传递的问题。
异步实现及其使用
- 同步调用就是你叫另外一个朋友吃饭,你等到朋友了,你们就一起去吃饭
- 异步调用就是你叫朋友吃饭,他正在忙,你就先看书,等到他忙完了,他叫你你就跟他一起吃饭去。
from multiprocessing import Pool
import time
import os
def test():
print("---进程池中的进程---pid=%d,ppid=%d--"%(os.getpid(),os.getppid()))
for i in range(3):
print("----%d---"%i)
time.sleep(1)
return "hahah"
def test2(args):
print("---callback func--pid=%d"%os.getpid())
print("---callback func--args=%s"%args)#观察这里args的结果
pool = Pool(3)
pool.apply_async(func=test,callback=test2)
time.sleep(5)
print("----主进程-pid=%d----"%os.getpid())运行结果
---进程池中的进程---pid=9401,ppid=9400--
----0---
----1---
----2---
---callback func--pid=9400
---callback func--args=hahah---#注意观察这里
----主进程-pid=9400----从上面可以看到。竟然可以从test2中得到test1的返回值。有没有很诡异,其中pool.apply_async(test) 等价于 pool.apply_async(func=test),非阻塞方式
分析思想:当子进程test1()执行完,也就是用了3秒时间,程序时间忽略不计,执行完之后,主进程发现有callback所以就去执行test2,从打印结果可以看到执行test2的是主进程而不是子进程,最后将子进程最后遗留的返回值返回给主进程的参数那里。所以最后打印出来hahah.