----------------------------我是分割线-------------------------------
本文翻译自微软白皮书《SQL Server In-Memory OLTP Internals Overview》:http://technet.microsoft.com/en-us/library/dn720242.aspx
译者水平有限,如有翻译不当之处,欢迎指正。
----------------------------我是分割线-------------------------------
事务隔离和并发管理
正如之前所介绍的 ,所有对 内存优化表数据的访问都是使用完全的乐观并发控制实现的,但也允许使用其他多个事务隔离级别进行访问。然而,在什么样的情况下允许什么样的隔离级别,看起来似乎有点混乱和不直观。需要考虑的隔离级别是那些涉及到交叉容器事务的隔离级别,这意味着任何引用内存优化表的解释型查询是来自于一个显式还是隐式的事务,或者是否处于自动提交模式下执行。在交叉容器事务中可以用于内存优化表的隔离级别取决于事务已经为SQL Server事务定义了什么隔离级别。大部分的限制都与一个事实有关,也就是即使是在同一个Transact-SQL事务中访问基于磁盘的表和内存优化表,基于磁盘的表上的操作与内存优化表上的操作各自都有它们自己的事务序列号。你可以把这种行为看作是一个较大的事务中具有两个子事务:一个子事务用于基于磁盘的表,一个子事务用于内存优化表。
首先,先笼统的看一下隔离级别的一些背景。这里不会完整的对隔离级别进行讨论,这样的讨论已经超出了本文的范围。隔离级别可以从保证的一致性属性来进行定义。最重要的属性如下:
- 读稳定性。如果事务T在处理过程中读取了一条记录的某个版本V1,我们必须保证到事务结束时,V1仍然是对事务T可见的版本,也就是说,V1并没有被另一个已提交的版本V2所取代。这可以通过锁定V1来阻止更新或者在提交事务前验证V1还没有别更新来实现。
- 幻影回避。我们必须能够保证事务T的扫描不会返回额外的在事务T开始时间与事务T提交时间之间增加的新版本。这可以通过两种方式来实现:锁定索引或表的已扫描部分,或者在提交事务前重新扫描来检查是否有新版本。
然后,我们可以基于这些属性来定义事务隔离级别。以下列出的第一个事务隔离级别(SNAPSHOT)没有提到这些属性,但后两个都提到了。
- SNAPSHOT
这个隔离级别规定,在一个事务中任何语句读取的数据与事务开始时存在的数据是事务一致的版本。事务只能够识别出在事务开始前已提交数据的修改。在当前事务开始后由其他事务进行的数据修改对于在当前事务中执行的语句都是不可见的。事务中的语句获得一个已提交数据的快照与事务开始时所存在的相同。
- REPEATABLE READ
这个隔离级别包括了SNAPSHOT隔离级别所提供的保证。此外,REPEATABLE READ还保证了读可靠性。对于事务读取的任何行,在事务提交时行还没有被其他事务更改。事务中的每一个读操作在事务结束前都是可重复的。
- SERIALIZABLE
这个隔离级别包括了REPEATABLE READ隔离级别所提供的保证。此外,SERIALIZABLE还保证了幻影回避。在事务中的操作不会错过任何行。在快照时间和事务结束之间不会出现幻影行。幻影行符合SELECT/UPDATE/DELETE的过滤条件。如果我们能够保证,在事务结束时所有重复的读取都可以看到完全相同的数据,那么这个事务则是可序列化的。
最简单和最广泛使用的多版本并发控制的方法是快照隔离(snapshot isolation ,SI),但快照隔离并不保证可序列化,因为逻辑上读取和写入在不同时间发生,读取是在事务开始时发生,而写入是在事务结束时发生。
访问基于磁盘的表还支持READ COMMITTED隔离,它只是保证该事务将不会读取任何脏(未提交)数据。访问内存优化表需要使用上述的三种隔离级别之一。表1列出了在一个交叉容器事务中可以一起使用的隔离级别。
|
基于磁盘的表 |
内存优化表 |
建议 |
|
READ COMMITTED |
SNAPSHOT |
这是基准组合,应该用于当前使用 READ COMMITTED 的大多数场景。 |
|
READ COMMITTED |
REPEATABLE READ / SERIALIZABLE |
这个组合可以在数据迁移期间使用,以及用于在互操作模式下(而不是在一个本地编译存储过程中)对内存优化表的访问。 |
|
REPEATABLE READ / SERIALIZABLE |
SNAPSHOT |
对内存优化表的访问只有插入操作。这个组合在进行迁移并且如果在内存优化表上没有进行并发写操作时也是有用的。 |
|
SNAPSHOT |
- |
不允许访问内存优化表(参见注释1) |
|
REPEATABLE READ / SERIALIZABLE |
REPEATABLE READ / SERIALIZABLE |
不允许这种组合 (参见注释2) |
表1 交叉容器事务中的兼容隔离级别
注释1:对于SNAPSHOT隔离,所有的操作都需要看到从事务开始时就存在的数据的版本。对于SNAPSHOT隔离,事务的开始是以访问第一个表的时间来计算的。但在交叉容器事务中,由于每个子事务可以在不同的时间点开始,在两个子事务的开始时间之间另一个事务可能已经改变了数据。交叉容器事务则没有快照所依据的一个时间点。
注释2:两个子事务(一个在基于磁盘的表和一个在内存优化表)不能都使用REPEATABLE READ或SERIALZABLE的原因是因为这两个系统以不同的方式实现隔离级别。设想一下图9中所示的两个交叉容器事务。
|
时间点 |
事务1 (SERIALIZBLE) |
事务2 (任何隔离级别) |
|
1 |
开始SQL或内存中的子事务 |
|
|
2 |
读取RHk1 |
|
|
3 |
开始SQL或内存中的子事务 |
|
|
4 |
读取RSql1 并更新为RSql2 |
|
|
5 |
读取RHk1 并更新为RHk2 |
|
|
6 |
提交 |
|
|
7 |
读取RSql2 |
表9 两个并发的交叉容器事务
事务1将首先从内存优化表中读取数据行,并且将不会保持任何锁,因此事务2可以完成并更改两个数据行。当事务1恢复时,当它从基于磁盘的表读取数据行,现在它将得到关于这两行的一组值,如果事务是被隔离运行的(即,如果事务是真正的可序列化。)那么这组值则应该不曾存在过。因此这个组合是不允许的。
有关隔离级别的详细信息,请参阅以下参考材料:
http://en.wikipedia.org/wiki/Isolation_(database_systems)
http://research.microsoft.com/apps/pubs/default.aspx?id=69541
内存优化表的持久性和存储
SQL Server必须确保内存优化表的事务持久性,使得所有已提交的事务的影响可以在发生故障后恢复。内存中OLTP通过采用检查点进程和事务日志记录进程写入到持久存储来实现这一点。虽然本文并不讨论,内存中OLTP还与AlwaysOn可用性组功能集成,这个功能维护了支持故障转移的高可用性副本。
写入磁盘的信息由检查点流和事务日志流所组成。
- 日志流包含了已提交事务所做的更改。
- 检查点流有两种类型:
- 数据流包含了一个时间戳间隔内插入的所有数据行的版本
- 增量流与一个特定的数据流相关联,并包含了一个整数列表,表明在其对应的数据流中哪些行版本已经被删除。
检查点流不定时进行。一对检查点文件,数据和增量文件,代表了事务日志的一个段,通常约含100MB的新数据行版本。
这些检查点文件对(checkpoint file pairs,CFP)积累并形成了一个完整的检查点(本节稍后会详细进行介绍)。最近完成的检查点加上从检查点以来最近的事务日志,就足以将内存优化表的内存中状态恢复到包括所有已提交事务的事务一致时间点。在详细介绍日志和检查点文件如何生成并使用之前,这里有几个需要注意的关键点:
- 日志流存储在常规的SQL Server事务日志中。
- 检查点流存储在SQL Server FILESTREAM文件中,这在本质上是完全由SQL Server管理的序列文件。 (FILESTREAM存储是在SQL Server2008中引入的,内存的OLTP的检查点文件利用了这一技术。有关FILESTREAM存储和管理的详细信息,请参阅此白皮书:http://msdn.microsoft.com/en-us/library /hh461480.aspx)
- 事务日志包含了关于已提交事务重做事务所需的信息。这些变化记录成行版本的插入和删除,并标记了它们所属的表。撤销信息不会写入事务日志。
- 内存优化表上的索引操作不会被记入日志。所有的索引在还原时都会被完全重建。
事务日志记录
内存中OLTP的事务日志记录针对可扩展性和高性能进行了设计。每个事务都记录在最少数量的日志记录中,这些可能很庞大的日志记录被写入到SQL Server常规事务日志中。日志记录包含了关于事务插入和删除的所有版本的信息。更新则被记录为旧版本数据行的删除和新版本数据行的插入。利用这些信息,在恢复过程中可以重做事务。
对于内存中OLTP的事务,只在提交时生成日志记录。比如,内存中OLTP并不使用处理基于磁盘的表上的操作时使用的预写日志(WAL)协议。使用预写日志, SQL Server在将任何更改的数据写入到磁盘之前先写日志,甚至写出在检查点期间未提交的数据也是有可能发生的。而对于内存中OLTP,脏数据(即未提交的更改)绝不会被写入到磁盘。此外,内存中OLTP试图将多个日志记录组成一个最大到24KB的日志记录,这能导致实际上写入更少的日志记录,以及更大的I/O操作。
与基于磁盘的表上的操作相比,内存中OLTP的操作可以产生更少的日志数据和更少的日志写入。下面简单的脚本说明了内存优化表极大地减少了日志记录。这个脚本将创建一个可以容纳内存优化表的数据库,然后创建两个类似的表。一个是内存优化表,一个是基于磁盘的表。
USE master GO IF EXISTS (SELECT * FROM sys.databases WHERE name='LoggingDemo') DROP DATABASE LoggingDemo; GO CREATE DATABASE LoggingDemo ON PRIMARY (NAME = [LoggingDemo_data], FILENAME = 'C:DataHKLoggingDemo_data.mdf'), FILEGROUP [LoggingDemo_FG] CONTAINS MEMORY_OPTIMIZED_DATA (NAME = [LoggingDemo_container1], FILENAME = 'C:DataHKStorageDemo_mod_container1') LOG ON (name = [hktest_log], Filename='C:DataHKStorageDemo.ldf', size=100MB); GO USE LoggingDemo GO IF EXISTS (SELECT * FROM sys.objects WHERE name='t1_inmem') DROP TABLE [dbo].[t1_inmem] GO -- create a simple memory-optimized table CREATE TABLE [dbo].[t1_inmem] ( [c1] int NOT NULL, [c2] char(100) NOT NULL, CONSTRAINT [pk_index91] PRIMARY KEY NONCLUSTERED HASH ([c1]) WITH(BUCKET_COUNT = 1000000) ) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA); GO IF EXISTS (SELECT * FROM sys.objects WHERE name='t1_disk') DROP TABLE [dbo].[t1_disk] GO -- create a similar disk-based table CREATE TABLE [dbo].[t1_disk] ( [c1] int NOT NULL, [c2] char(100) NOT NULL) GO CREATE UNIQUE NONCLUSTERED INDEX t1_disk_index on t1_disk(c1); GO
接下来,将基于磁盘的表填充了100行数据,并使用未公开的(和不受支持的)函数fn_dblog()检查事务日志的内容。
BEGIN TRAN DECLARE @i int = 0 WHILE (@i < 100) BEGIN 33 INSERT INTO t1_disk VALUES (@i, replicate ('1', 100)) SET @i = @i + 1 END COMMIT -- you will see that SQL Server logged 200 log records SELECT * FROM sys.fn_dblog(NULL, NULL) WHERE PartitionId IN (SELECT partition_id FROM sys.partitions WHERE object_id=object_id('t1_disk')) ORDER BY [Current LSN] ASC; GO
现在在内存优化表上运行类似的更新,类似于图10,你会看到只有三条日志记录。
BEGIN TRAN DECLARE @i int = 0 WHILE (@i < 100) BEGIN INSERT INTO t1_inmem VALUES (@i, replicate ('1', 100)) SET @i = @i + 1 END COMMIT -- look at the log SELECT * FROM sys.fn_dblog(NULL, NULL) order by [Current LSN] DESC; GO
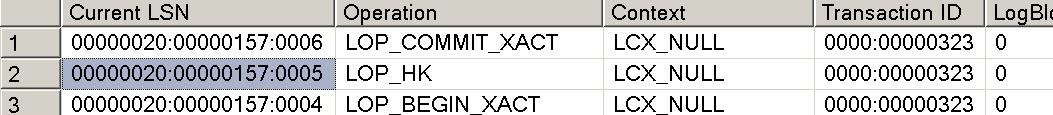
图10 100行事务显示成一条记录的SQL Server事务日志
输出显示全部100条插入都已经记录在类型为LOP_HK的单个日志记录中。 LOP表示“逻辑运算(logical operation)”和HK则是项目代码Hekaton的简称。另一个未公开的和不受支持的函数可以用来拆分LOP_HK记录。你需要将LSN值替换成你的LOP_HK纪录对应的LSN。
SELECT [current lsn], [transaction id], operation, operation_desc, tx_end_timestamp, total_size, object_name(table_id) AS TableName FROM sys.fn_dblog_xtp(null, null) WHERE [Current LSN] = '00000020:00000157:0005';
前几行的输出应该类似于图11。
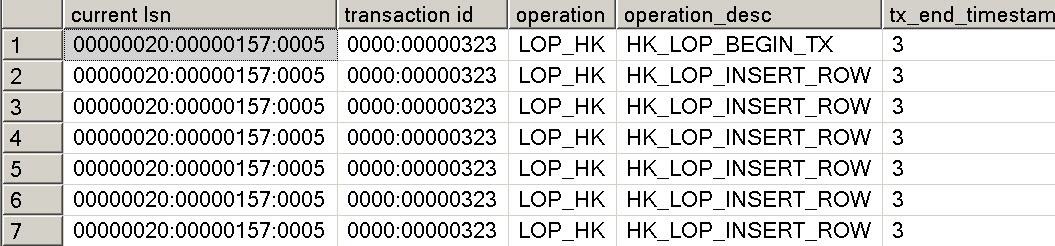
图11 将内存优化表上插入的日志记录拆分显示出受影响的各行
内存优化表上整个事务的单条日志记录,加上较少的日志记录信息,这有助于使得内存优化表上的事务更加高效。
检查点
与基于磁盘的表上的操作类似,检查点操作的主要原因之一是减少恢复的时间。内存优化表的检查点进程的设计满足两个重要的要求。
- 连续持久性。一个后台线程主动扫描事务日志记录,并填充磁盘上的数据/增量文件。
- I/O流。通过将新创建的数据行附加到当前数据文件的结尾以及将删除的数据行附加到对应的增量文件这样的只可附加的方式完成数据/增量文件的写入。
检查点操作是从事务日志中构建检查点文件(即数据文件和增量文件)的持续的过程。
数据文件只包含插入的版本或者数据行,正如我们之前所看到的,这是通过INSERT和UPDATE操作产生的。每个文件都覆盖了一个特定的时间戳范围。文件中包含了数据文件范围内的所有版本及其开始时间戳。当数据文件是打开的时,它们是只可附加的,一旦数据文件被关闭,它们则严格限制为只读。在恢复时,数据文件中的有效版本会被重新加载到内存中,并重建索引。
增量文件存储了包含在数据文件中但随后已被删除的版本的信息。增量文件和数据文件之间存在1:1的对应关系。在增量文件对应的数据文件的生命周期内,增量文件是只可附加的。在恢复时,增量文件被当作是一个过滤器,以避免将已删除的版本重新加载到内存中。每个数据文件都有一个搭配的增量文件,因此恢复工作的最小单位是一个数据/增量文件对。这使得恢复过程是高度并行化的。
分配成对的数据和增量文件被称为检查点文件对(CFP,Checkpoint File Pair)。一个数据库中最多支持8192个检查点文件对。
完成一个检查点
内存优化表的检查点操作是独立于基于磁盘的表的检查点之外。基于磁盘的表的自动检查点由恢复间隔选项所控制,这个选项与内存优化表的检查点没有什么关系。内存优化表的一个完整的检查点由多个数据和增量文件以及一个检查点文件清单所组成,检查点文件清单包含了所引用的组成一个完整检查点的所有数据和增量文件。检查点的完成过程包括将数据和增量文件的最新内容刷新到磁盘,以及构建写入到事务日志中的清单。
检查点以自动和手动两种方式完成:
- 检查点自动完成:从上次自动检查点以来,当事务日志超过512MB时完成。换句话说,对于包含了来自于内存优化表和基于磁盘的表的变化的日志记录,每积累512MB都会开始一个自动检查点。与基于磁盘的表的检查点不同,内存优化表的数据持久性是由一个后台线程连续完成的,完成一个检查点会更新内部的元数据信息。
- 检查点手动完成:当发出一个显示的CHECKPOINT命令时,启动基于磁盘的表和内存优化表上的检查点操作
一个完整的检查点结合事务日志尾部从而能够恢复内存优化表。检查点有一个时间戳表明了在检查点时间戳之前所有事务的影响都记录在检查点中,因此不需要恢复那些更早的事务日志。
合并检查点文件
检查点文件包含的文件集合会随着每次检查点增长。但是一个数据文件的活动内容是减少的,因为越来越多的版本在相应的增量文件中会被标记为已删除。由于恢复过程将读取检查点中所有数据和增量文件的内容,故障恢复的性能会随着每个数据文件中相应的行数减少而下降。
检查点系统通过一个名为合并的自动过程来处理这个问题。 SQL Server 2014实施以下合并策略:
- 在考虑已删除的行后,如果可以合并 2 个或更多的连续检查点文件对,则计划进行合并,这样,最后生成的行可以适合于 1 个检查点文件对的理想大小。 一个检查点文件的理想大小按如下方式确定:
- 如果计算机的内存小于16GB。则数据文件是 16MB,差异文件是 1MB。
- 如果计算机的内存大于16GB,则数据文件是 128MB,差异文件是 16MB。
- 如果数据文件超过 256 MB,并且删除的行超过一半,则单个 检查点文件对可自行合并。 数据文件可能增大到大于 128MB(例如,如果单个事务或多个并发事务插入或更新大量数据,迫使数据文件增大为超过其理想大小),因为事务不能跨多个检查点文件。
自动合并
为了确定进行合并的文件,一个后台任务定期查看所有活动的数据或增量检查点文件对,并标识零个或多个符合合并操作的检查点文件对组。每一组可以包含一个或多个彼此相邻的数据/增量文件对,这样生成的行集仍然可以适合于128MB大小的单个数据文件。图12展示了合并策略下,将选择被合并的文件的一些示例。
|
相邻的源文件(完整度百分比) |
合并选择 |
|
DF0 (30%) DF1 (50%), DF2 (50%), DF3 (90%) |
(DF1, DF2) |
|
DF0 (30%) DF1 (20%), DF2 (50%), DF3 (10%) |
(DF0, DF1, DF2). 从左侧开始选择文件 |
|
DF0 (80%), DF1 (10%), DF2 (10%), DF3 (20%) |
(DF0, DF1, DF2). 从左侧开始选择文件 |
图12 可选择进行文件合并操作的文件示例
有可能两个相邻的数据文件都为60%。它们则不会被合并,并且40%的存储不会被使用。因此实际上,持久的内存优化表的总磁盘存储大于相应的内存优化表的大小。
手动合并sys.sp_xtp_merge_checkpoint_files
在大多数情况下,检查点文件的自动合并足以将文件数量维持在一个可管理的数量。但是,在极少数情况下,或者用于测试目的,您可能需要使用手动合并。更多信息可以在这里找到:http://blogs.technet.com/b/dataplatforminsider/archive/2014/01/22/merge-operation-in-memory-optimized-tables.aspx
检查点文件存储相关的注意事项
假设合并和数据持久性是持续的,持久表占用的存储空间大小会明显大于相应的内存优化表的大小。对于一个数据库内所有持久表在内存中总的大小的建议限值为250 GB。假设在混合的插入/删除/更新操作情况下,需要250 GB内存空间的持久表平均需要内存优化的文件组中500 GB的存储空间,跨越4000个数据/增量文件对。数据库中活动的爆发可能会导致检查点和合并操作延迟一段时间,因此增加了所需的文件数量。作为这样爆发的缓冲,存储系统支持多达8000个数据/增量文件对或者1TB的存储,并且在达到上限时,数据库中新的事务将被阻止,直到检查点操作追上为止。8000个数据/增量文件对的缓冲允许持久表在内存中总的大小超过250GB,但如果长时间超过250GB应该注意,因为这会增加达到8000个文件对上限的风险。当达到8000个 检查点文件对的限制时,则可以通过前一节中描述的强制手动合并来减少检查点文件对的数量。请注意,手动合并允许超过8000个检查点文件对的上限并达到8192个检查点文件对,使得在达到8000个 检查点文件对上限时客户进行故障排除具有一定的灵活性。
检查点文件的垃圾收集
一旦合并操作完成后,源文件就不再需要,并且只要定期进行日志备份,源文件稍后就可能能够通过垃圾收集进程进行清除。在清除一个检查点文件之前,内存中OLTP引擎必须确定它不再需要。通常,垃圾回收进程是自动的,并且不需要任何干预。然而,有一个选项可以强制进行未使用的检查点文件的垃圾收集。
动态管理视图sys.dm_db_xtp_checkpoint_files可以查询内存优化文件组中所有检查点文件对的列表,包括它们所处的阶段。关于这个动态管理试图的详细信息,请参见http://blogs.technet.com/b/dataplatforminsider/archive/2014/01/22/merge-operation-in-memory-optimized-tables.aspx。
恢复
通过扫描日志尾部恢复最近的检查点清单的位置,开始内存中OLTP表的恢复。一旦SQL Server主机已经将检查点清单的位置传递给内存中OLTP的引擎,SQL Server和内存中OLTP的恢复就并行开始。
内存中OLTP的恢复本身是并行化的。每个增量文件都表示了无需从相应数据文件中加载的行的过滤器。这种数据/增量文件的架构意味着检查点加载可以跨多个IO流并行进行,每个流处理一个数据文件和增量文件。内存中OLTP引擎为每个内核创建一个线程来并行处理由I/O流产生的数据插入。插入线程在除去已经删除的行之后,将数据文件中的所有活动行(和所有索引)加载到内存中。每个内核一个线程的选择意味着加载过程可以尽可能有效地执行。
最后,一旦检查点加载过程完成后,从检查点的时间戳开始重播事务日志的尾部,把数据库恢复到崩溃时所存在的状态。
---------------------------全文完-------------------------------