目录
(见右侧目录栏导航)
- 1. RabbitMQ集群高可用
- 1.1 单一模式
- 1.2 普通模式
- 1.3 镜像模式
- 2. 集群的基本概念
- 3. RabbitMQ普通模式集群配置
- 3.1 安装 rabbitmq
- 4. RabbitMQ 镜像集群配置
- 5. 安装配置 Haproxy
1. RabbitMQ集群高可用
RabbitMQ是用erlang开发的,集群非常方便,因为erlang天生就是一门分布式语言,但其本身并不支持负载均衡。
Rabbit模式大概分为以下三种:
(1) 单一模式
(2) 普通模式
(3) 镜像模式
1.1 单一模式
最简单的情况,非集群模式。
1.2 普通模式
默认的集群模式
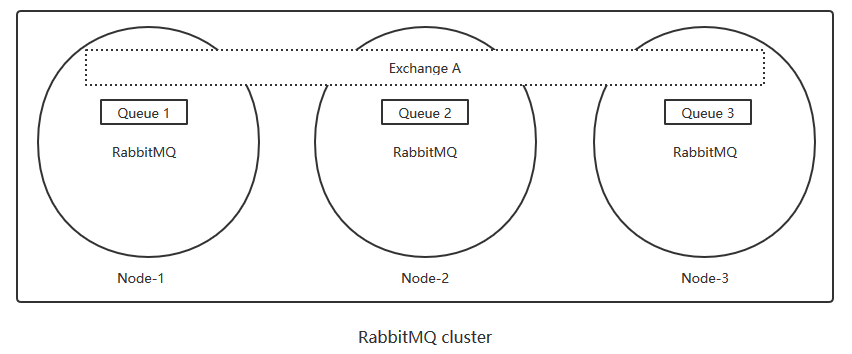
上面图中采用三个节点组成了一个RabbitMQ的集群,Exchange A (交换机)的元数据信息在所有节点上是一致的,而 Queue(存放消息的队列)的完整数据则只会存在于它所创建的那个节点上。其他节点只知道这个queue的metadata信息和一个指向queue的owner node的指针。
(1)RabbitMQ集群元数据的同步
RabbitMQ集群会始终同步四种类型的内部元数据(类似索引):
a. 队列元数据:队列名称和它的属性;
b. 交换机元数据:交换机名称、类型和属性;
c. 绑定元数据:一张简单的表格展示了如何将消息路由到队列;
d. vhost元数据:为vhost内的队列、交换机和绑定提供命名空间和安全属性;
因此,当用户访问其中任何一个RabbitMQ节点时,通过Rabbitctl查询到的queue/user/exchange/vhost等信息都是相同的。
对于Queue来说,消息实体只存在于其中一个节点,node1、node2、node3 三个节点仅有相同的元数据,即队列结构。
当消息进入node1节点的Queue中后,consumer从node2节点拉取时,RabbitMQ会临时在node1、node2之间进行消息传输,把node1中的消息实体取出并经过node2发送给consumer。
所以consumer应尽量连接每个节点,从中取消息。即对于同一个逻辑队列,要在多个节点建立物理Queue。否则无论consumer连A或B,出口总在A,会产生瓶颈。
该模式存在一个问题就是当node1节点故障后,node2、node3节点无法取到node1节点中还未消费的消息实体。
如果做了消息持久化,那么得等A节点恢复,然后才可被消费;如果没有持久化的话,那么数据就丢失了。
1.3 镜像模式
把需要的队列做成镜像队列,存在于多个节点,属于RabbitMQ的HA方案。
该模式解决了上述问题,其实和普通模式不同之处在于,消息实体会主动在镜像节点间同步,而不是在consumer取数据时临时拉取。
该模式带来的副作用也很明显,除了降低系统性能外,如果镜像队列数量过多,加之大量的消息进入,集群内部的网络带宽将会被这种同步通讯大大消耗掉。
所以在对可靠性要求较高的场合中适用
2. 集群的基本概念
RabbitMQ的集群节点包括内存节点、磁盘节点。顾名思义内存节点就是将所有数据放在内存,磁盘节点将数据放在磁盘。不过,如前文所述,如果在投递消息时,打开了消息的持久化,那么即使是内存节点,数据还是安全的放在磁盘。
一个rabbitmq集 群中可以共享 user,vhost,queue,exchange等,所有的数据和状态都是必须在所有节点上复制的,rabbitmq节点可以动态的加入到集群中,一个节点它可以加入到集群中,也可以从集群环集群会进行一个基本的负载均衡。
集群中有两种节点:
(1) 内存节点:只保存状态到内存(一个例外的情况是:持久的queue的持久内容将被保存到disk)
(2) 磁盘节点:保存状态到内存和磁盘。
内存节点虽然不写入磁盘,但是它执行比磁盘节点要好。集群中,只需要一个磁盘节点来保存状态 就足够了
如果集群中只有内存节点,那么不能停止它们,否则所有的状态,消息等都会丢失。
集群实现思路:
那么具体如何实现RabbitMQ高可用,我们先搭建一个普通集群模式,在这个模式基础上再配置镜像模式实现高可用,Rabbit集群前增加一个反向代理,生产者、消费者通过反向代理访问RabbitMQ集群,如图:
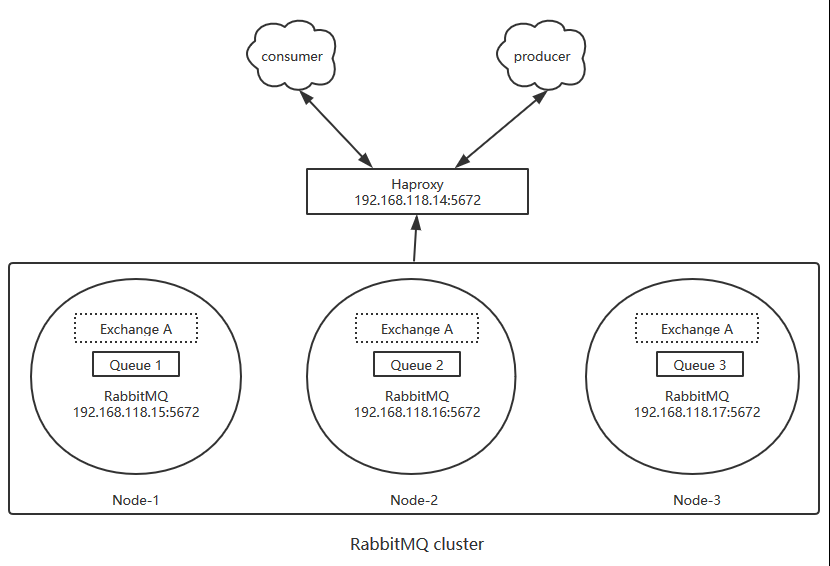
3. RabbitMQ普通模式集群配置
3.1 安装 rabbitmq
(1)修改主机名、安装 rabbitmq
192.168.118.15 、192.168.118.16、192.168.118.17 对应执行以下操作(主机各自的主机名)
[root@192.168.118.15 ~]# hostnamectl set-hostname node1
[root@192.168.118.15 ~]# hostname node1
[root@192.168.118.15 ~]# cd /opt/
[root@192.168.118.15 /opt]# ls??
# erlang、rabbitmq-server 下载地址:http://ww.rabbitmq.com/releases/
erlang-19.0.4-1.el6.x86_64.rpm??rabbitmq-server-3.6.13-1.el7.noarch.rpm
[root@192.168.118.15 /opt]# yum install *.rpm -y
只需在node1(192.168.118.15)上启动服务
[root@192.168.118.15 /opt]#systemctl start rabbitmq-server # 启动服务
[root@192.168.118.15 ~]#rabbitmq-plugins enable rabbitmq_management # 开启后端web管理
[root@192.168.118.15 ~]#netstat -ntplu | egrep beam
tcp 0 0 0.0.0.0:25672 0.0.0.0:* LISTEN 4557/beam
tcp 0 0 0.0.0.0:15672 0.0.0.0:* LISTEN 4557/beam
tcp6 0 0 :::5672 :::* LISTEN 4557/beam
(2)拷贝 .erlang.cookie
Rabbitmq的集群是依附于erlang的集群工作的,所以必须先构建起erlang的集群模式。erlang.cookie是erlang实现分布式的必要文件,erlang分布式的每个节点上要保持相同的.erlang.cookie文件,同时保证文件的权限是400
[root@192.168.118.15 ~]#cat /var/lib/rabbitmq/.erlang.cookie
GFCOJDLAKUIEJCLKCNVR
将 192.168.118.15 的 .erlang.cookie 文件拷贝到 192.168.118.16、192.168.118.17 对应的目录下并设置权限
[root@192.168.118.15 ~]#scp /var/lib/rabbitmq/.erlang.cookie node2:/var/lib/rabbitmq/
[root@192.168.118.15 ~]#scp /var/lib/rabbitmq/.erlang.cookie node3:/var/lib/rabbitmq/
分别在 192.168.118.16、192.168.118.17 赋予权限
192.168.118.16
[root@192.168.118.16 ~]#ll /var/lib/rabbitmq/.erlang.cookie
-r-------- 1 root root 20 Jan 7 20:43 /var/lib/rabbitmq/.erlang.cookie
[root@192.168.118.16 ~]#chown rabbitmq:rabbitmq /var/lib/rabbitmq/.erlang.cookie
192.168.118.17
[root@192.168.118.17 ~]#ll /var/lib/rabbitmq/.erlang.cookie
-r-------- 1 root root 20 Jan 7 20:45 /var/lib/rabbitmq/.erlang.cookie
[root@192.168.118.17 ~]#chown rabbitmq:rabbitmq /var/lib/rabbitmq/.erlang.cookie
开启 node2(192.168.118.16) node3(192.168.118.17) 服务
[root@192.168.118.16 ~]#systemctl start rabbitmq-server
[root@192.168.118.17 ~]#systemctl start rabbitmq-server
(3)将node2(192.168.118.16)、node3(192.168.118.17) 作为内存节点加入node1(192.168.118.15)节点集群中
node2(192.168.118.16)
[root@192.168.118.16 ~]#rabbitmqctl stop_app
Stopping rabbit application on node rabbit@node2
[root@192.168.118.16 ~]#rabbitmqctl join_cluster --ram rabbit@node1
Clustering node rabbit@node2 with rabbit@node1
[root@192.168.118.16 ~]#rabbitmqctl start_app
Starting node rabbit@node2
node3(192.168.118.17)
[root@192.168.118.17 ~]#rabbitmqctl stop_app # 停止rabbit应用
Stopping rabbit application on node rabbit@node3
[root@192.168.118.17 ~]#rabbitmqctl join_cluster --ram rabbit@node1 # 加入到磁盘节点
Clustering node rabbit@node3 with rabbit@node1
[root@192.168.118.17 ~]#rabbitmqctl start_app # 启动rabbit应用
Starting node rabbit@node3
A. 默认rabbitmq启动后是磁盘节点,在这个cluster命令下,node2和node3是内存节点,node1是磁盘节点。
B. 如果要使node2、node3都是磁盘节点,去掉--ram参数即可。
C. 如果想要更改节点类型,可以使用命令rabbitmqctl change_cluster_node_type disc(ram),前提是必须停掉rabbit应用。
(4)查看集群状态
[root@192.168.118.15 ~]#rabbitmqctl cluster_status
Cluster status of node rabbit@node1
[{nodes,[{disc,[rabbit@node1]},{ram,[rabbit@node3,rabbit@node2]}]},
{running_nodes,[rabbit@node3,rabbit@node2,rabbit@node1]}, # 正在运行中的集群节点
{cluster_name,<<"rabbit@node1">>},
{partitions,[]},
{alarms,[{rabbit@node3,[]},{rabbit@node2,[]},{rabbit@node1,[]}]}]
(5)为rabbit添加用户并授权
[root@192.168.118.15 ~]#rabbitmqctl add_user admin admin # 新建用户
Creating user "admin"
[root@192.168.118.15 ~]#rabbitmqctl set_user_tags admin administrator # 赋予管理员角色
Setting tags for user "admin" to [administrator]
[root@192.168.118.15 ~]#rabbitmqctl set_permissions admin '.*' '.*' '.*' # 授予管理、写、读权限
Setting permissions for user "admin" in vhost "/"
(6)登录rabbitmq web管理控制台,创建新的队列
打开浏览器输入 http://192.168.118.15:15672/ 刚才的创建的用户:admin 密码: admin,登录后出现如图:
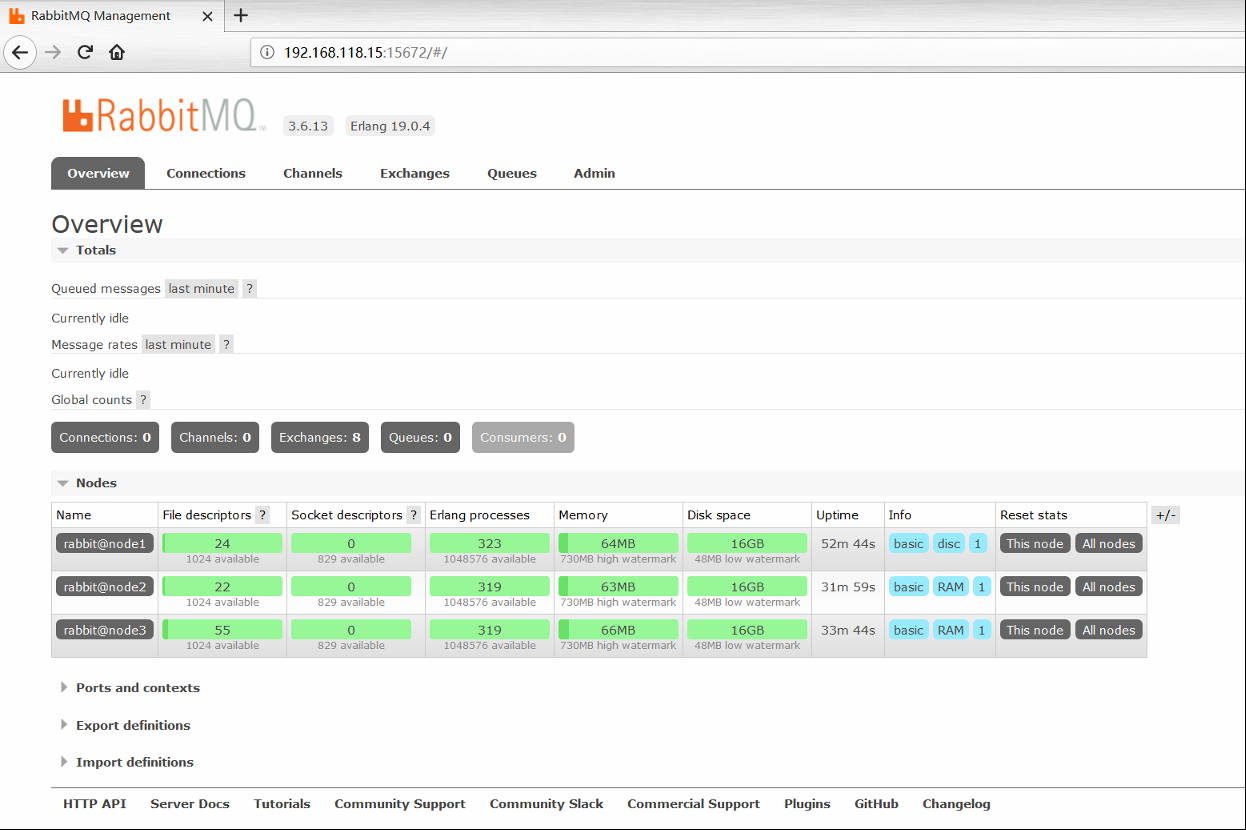
根据页面提示创建一条队列

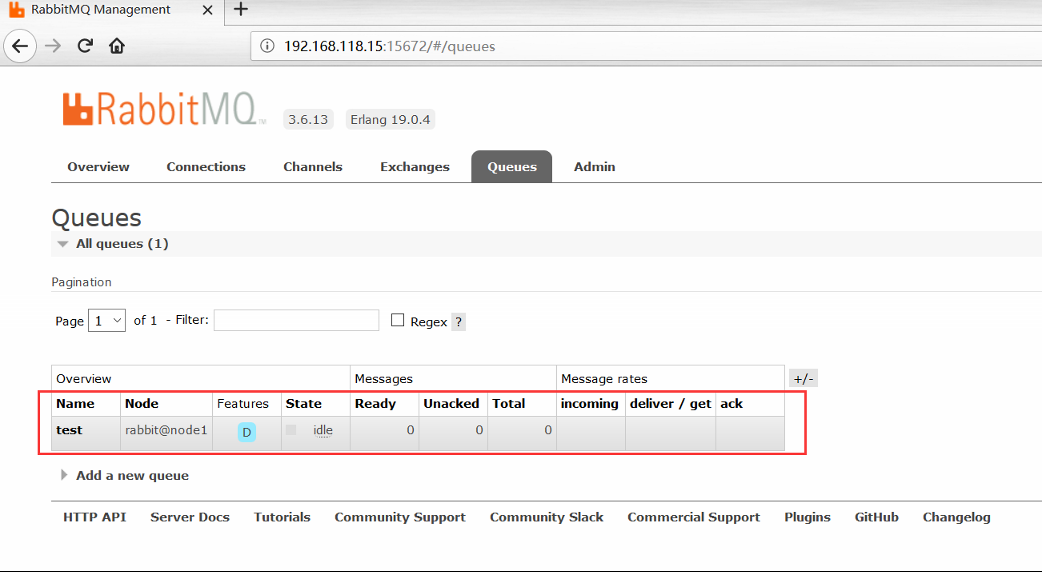
在RabbitMQ普通集群中,必须至少有一个磁盘节点,否则队列元数据无法写入到集群中,当磁盘节点宕掉时,集群将无法写入新的队列元数据信息。
到此,rabbitmq 普通模式搭建完毕。
4. RabbitMQ 镜像集群配置
上面已经完成RabbitMQ默认集群模式,但并不保证队列的高可用性,尽管交换机、绑定这些可以复制到集群里的任何一个节点,但是队列内容不会复制。虽然该模式解决一项目组节点压力,但队列节点宕机直接导致该队列无法应用,只能等待重启,所以要想在队列节点宕机或故障也能正常应用,就要复制队列内容到集群里的每个节点,必须要创建镜像队列。
镜像队列是基于普通的集群模式的,然后再添加一些策略,所以你还是得先配置普通集群,然后才能设置镜像队列,我们就以上面的集群接着做。
设置的镜像队列可以通过开启的网页的管理端,也可以通过命令,这里说的是其中的网页设置方式。
(1) 创建rabbitmq策略
在node1(192.168.118.15)节点的控制台上创建策略
A. 点击admin菜单–>右侧的Policies选项–>左侧最下下边的Add/update a policy。
B. 按照图中的内容根据自己的需求填写。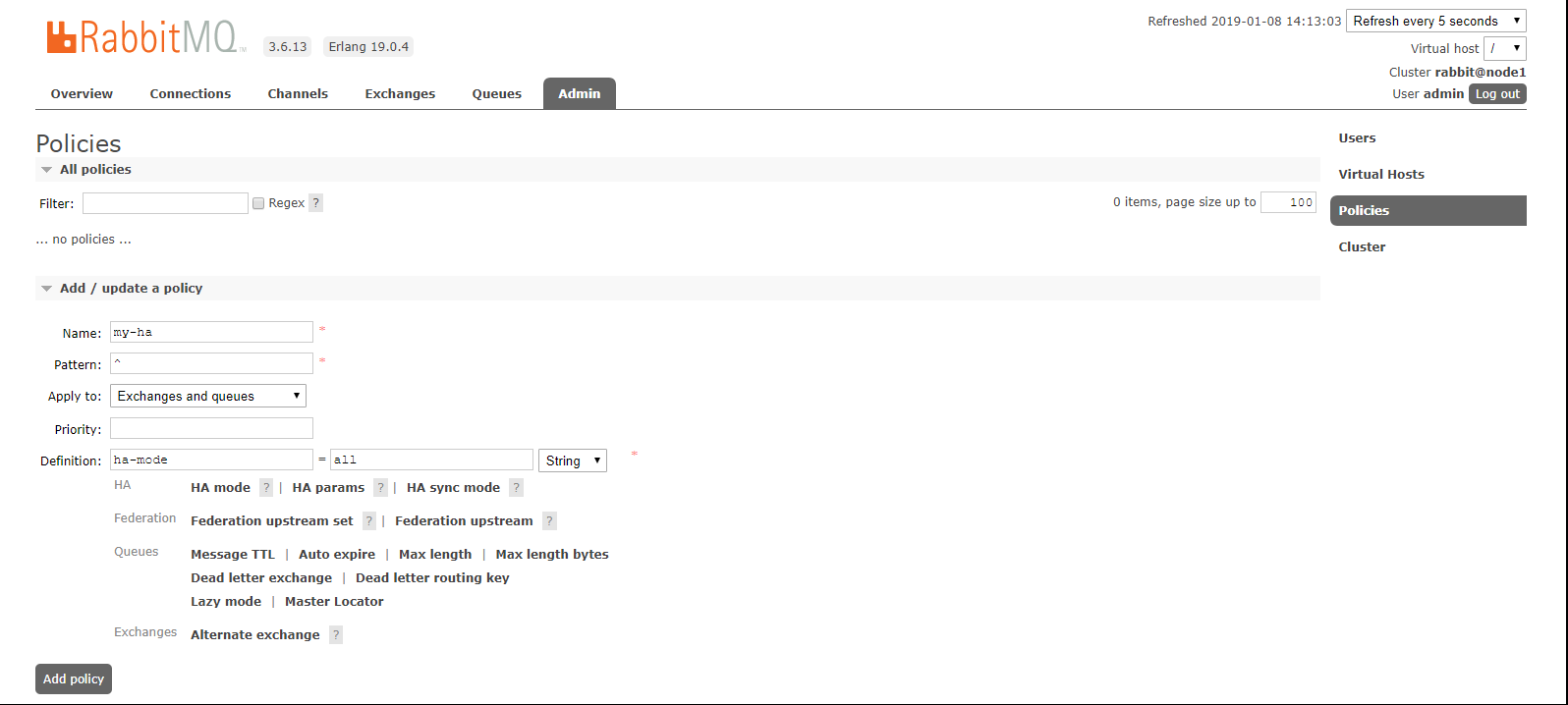
Name:策略名称
Pattern:匹配的规则,这里表示所有的队列,如果是匹配以a开头的队列,那就是^a.
Definition:使用ha-mode模式中的all,也就是同步所有匹配的队列。问号链接帮助文档。
点击Add policy添加策略
此时分别登陆node2、node3两个节点的控制台,可以看到上面添加的这个策略,如图所示:
node2
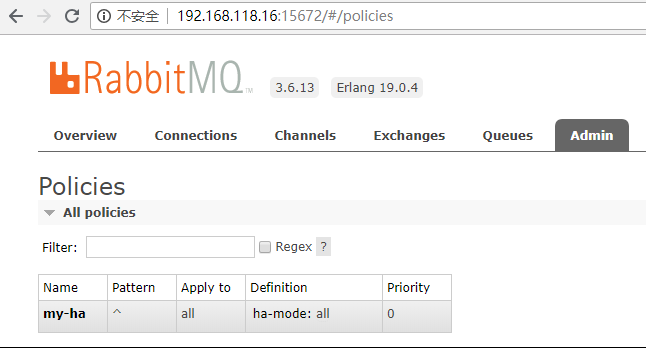
node3

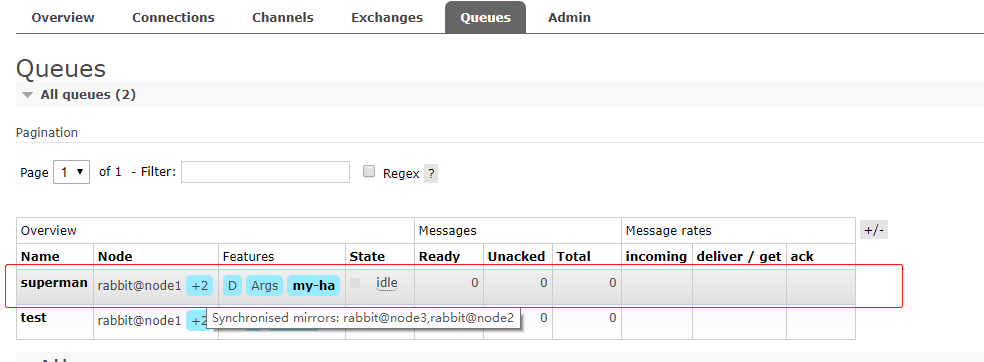
(2)添加队列
在node1节点的控制台上添加队列
A. 点击Queues菜单–>左侧下边的Add a new queue
B. 输入Name和Arguments参数的值,别的值默认即可
Name:队列名称
Durability:队列是否持久化
Node:消息队列的节点
Auto delete:自动删除
Arguments:使用的策略类型
将鼠标指向+2可以显示出另外两台消息节点。
(3)创建消息
A. 点击superman队列按钮
B. 拖动滚动条,点击publish message
C. 填写相关内容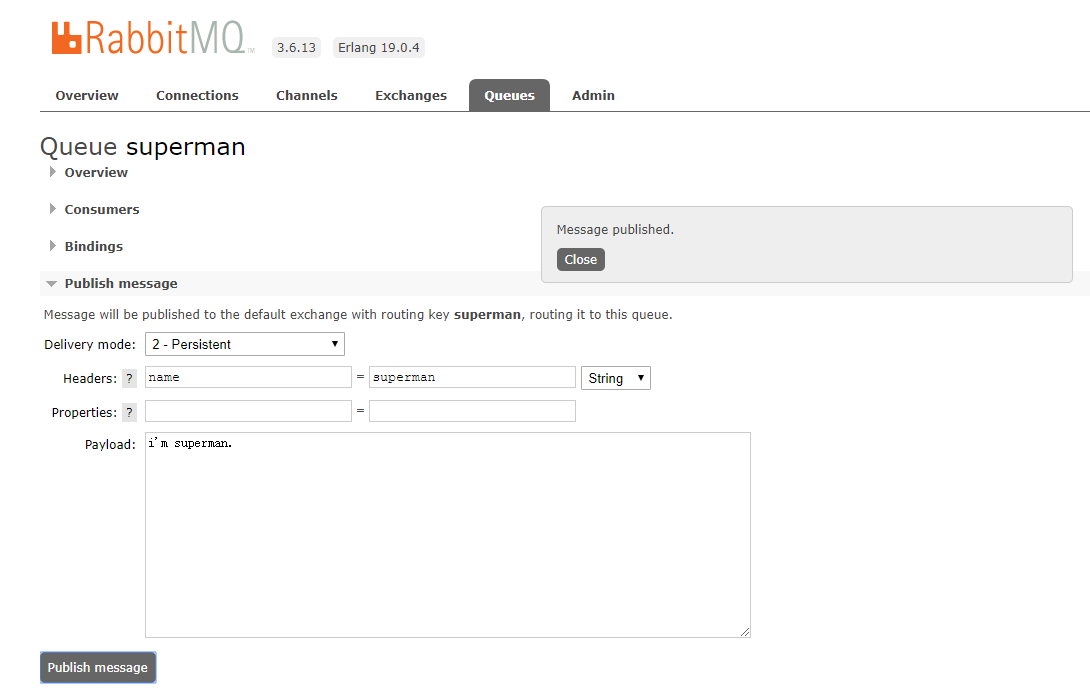
2-Persistent:表示持久化
Headers:随便填写即可
Properties:点击问号,选择一个消息ID号
Payload:消息内容
点击queue按钮,发现superman队列的Ready和Total中多了一条消息记录。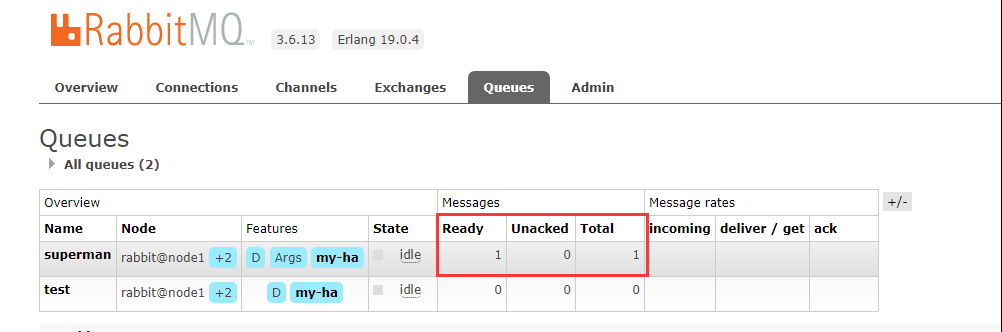
(4)做破坏性测试
A. 将node1节点的服务关闭,再通过node2和node3查看消息记录是否还存在。
停止 node1 rabbitmq服务
[root@192.168.118.15 ~]#systemctl stop rabbitmq-server
node2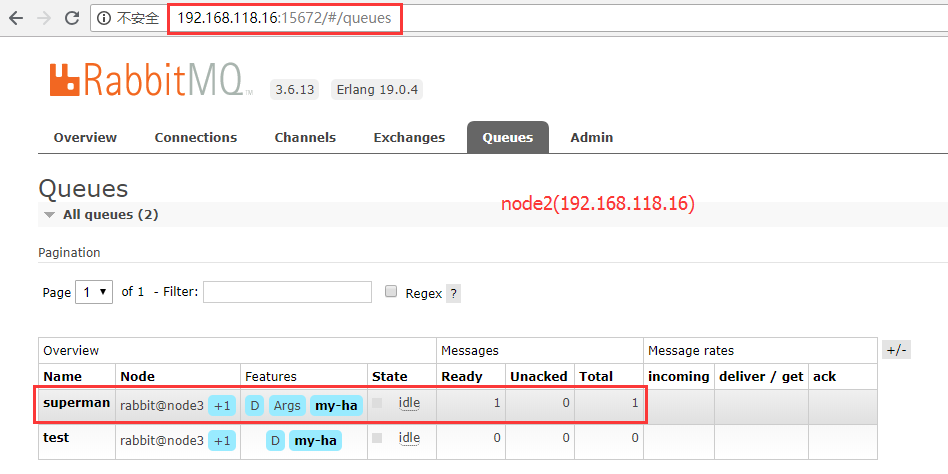
node3
从中可以看到ab队列已经从之前的+2显示成+1了,而且消息记录是存在的。
B. 再将node2(192.168.118.16)节点的服务关闭,通过node3查看消息记录是否还存在。
[root@192.168.118.16 ~]#systemctl stop rabbitmq-server
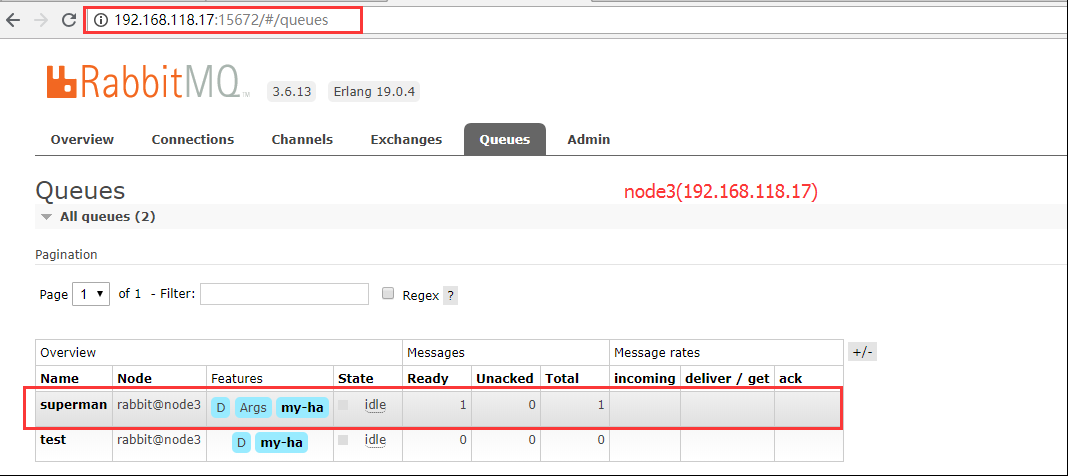
从中可以看到superman队列和消息记录还是存在的,只是变成了一个节点了。
C. 将node1和node2的服务再启动起来
[root@192.168.118.15 ~]#rabbitmqctl sync_queue superman
[root@192.168.118.16 ~]#rabbitmqctl sync_queue superman
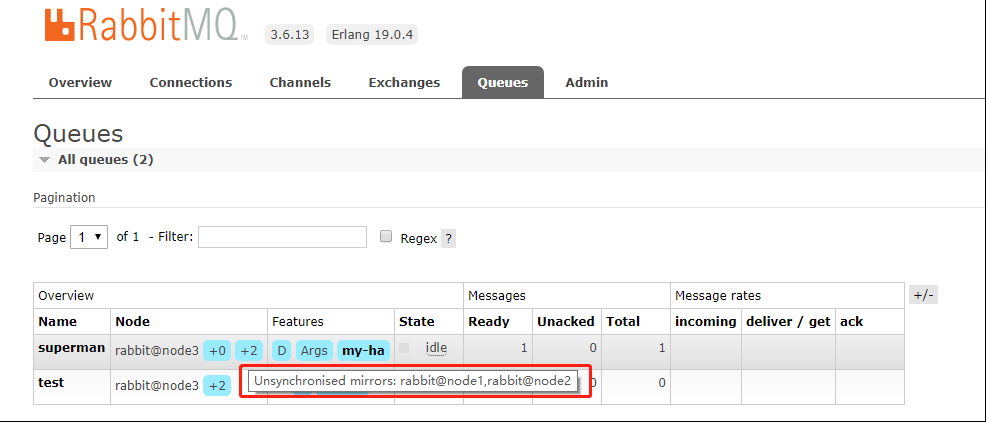
从提示中显示镜像无法同步。如果这时候停掉node3节点的服务,那么队列里面的消息将会丢失。
启动后,不同步的解决方法是在node1、node2节点上执行同步命令。
[root@192.168.118.15 ~]#rabbitmqctl sync_queue superman
[root@192.168.118.16 ~]#rabbitmqctl sync_queue superman
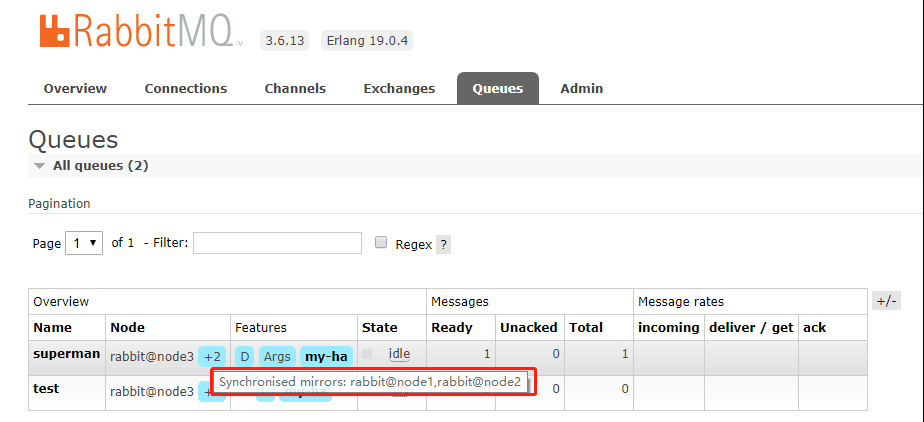
同步完成后,就显示同步镜像的节点。
这样,我们就测试了rabbitmq集群的破坏性测试,说明集群配置成功。
5. 安装配置 Haproxy
(1)修改主机名
[root@192.168.118.14 ~]#hostnamectl set-hostname haproxy ; hostname haproxy
(2)安装haproxy 这里就直接使用epel源安装haproxy
[root@192.168.118.14 ~]#yum install haproxy -y
(3)修改配置文件
[root@192.168.118.14 ~]#egrep -v '#|^$' /etc/haproxy/haproxy.cfg
global
log 127.0.0.1 local2
chroot /var/lib/haproxy
pidfile /var/run/haproxy.pid
maxconn 4000
user haproxy
group haproxy
daemon
stats socket /var/lib/haproxy/stats
defaults
mode http
log global
option httplog
option dontlognull
option http-server-close
option forwardfor except 127.0.0.0/8
option redispatch
retries 3
timeout http-request 10s
timeout queue 1m
timeout connect 10s
timeout client 1m
timeout server 1m
timeout http-keep-alive 10s
timeout check 10s
maxconn 3000
listen http_front # haproxy 管理后台
bind 0.0.0.0:1080 # 监听端口
mode http # 开启模式为http
stats enable # 开启后台统计
stats hide-version # 隐藏统计页面上HAProxy的版本信息
stats refresh 30s # 统计页面自动刷新时间
stats uri /stats # 统计页面uri
stats realm Haproxy Manager # 统计页面密码框上提示文本
stats auth admin:admin # 统计页面用户名和密码设置
stats admin if TRUE # 此项是实现haproxy监控页的管理功能的
listen rabbitmq_cluster # RabbitMQ 集群负载
bind 0.0.0.0:5672 # 监听端口
option tcplog
mode tcp
timeout client 3h
timeout server 3h
option clitcpka
balance roundrobin # 负载均衡算法
server node2 192.168.118.16:5672 check inter 5s rise 2 fall 3
server node3 192.168.118.17:5672 check inter 5s rise 2 fall 3
server <name>:定义haproxy内RabbiMQ服务的标识
ip:port: 标识了后端RabbitMQ的服务地址
check inter 5s: 表示每个5秒检测RabbitMQ服务是否可用
rise 2: 表示RabbitMQ服务在发生故障之后,需要2次健康检查才能被再次确认可用
fall 3: 表示需要经历 3 次失败的健康检查之后,HaProxy才会停止使用此RabbitMQ服务
具体HaProxy 相关说明:https://www.cnblogs.com/hukey/p/5586765.html
(4)启动haproxy
[root@192.168.118.14 ~]#systemctl start haproxy
[root@192.168.118.14 ~]#netstat -ntplu | egrep haproxy
tcp 0 0 0.0.0.0:5672 0.0.0.0:* LISTEN 19006/haproxy
tcp 0 0 0.0.0.0:1080 0.0.0.0:* LISTEN 19006/haproxy
udp 0 0 0.0.0.0:43437 0.0.0.0:* 19005/haproxy
通过浏览器登录haproxy统计后台 http://192.168.118.14:1080/stats

到此,RabbitMQ + HaProxy 高可用集群搭建完毕,后面可自行进行测试。
本文参考链接:
http://blog.51cto.com/11134648/2155934
https://www.jianshu.com/p/6376936845ff