2.1 永不停止的脚步——数据库优化之路
前言
2016年双11已经顺利落下帷幕,在千亿电商流量的冲击下,集团数据库整体表现完美。完美表现的背后,隐藏着数据库团队对技术的执着追求。这是一个什么样的团队,他们究竟做了什么,是什么支持着双11这一全民狂欢的数字一次次突破?笔者以一个亲历者的角度来给大家揭开双11背后,阿里巴巴数据库团队的神秘面纱。
1. 我们是谁
- 我们是阿里巴巴集团基础架构事业群-数据库技术团队,我们团队维护着阿里巴巴集团、蚂蚁金服、菜鸟网络所有的数据库,是整个大阿里系,坚强的存储中台。
- 我们是阿里巴巴集团神秘的MySQL分支——AliSQL的开发者,传说中的AliSQL拥有者远超原生MySQL的性能,并且有着为阿里巴巴电商、金融业务场景量身定制的优化。
- 我们为整个阿里巴巴集团的异地多活提供底层基础架构——DRC。DRC提供超远距离(中美超过10,000公里),超低延时(中美同步延时小于500ms)的数据库同步订阅服务。
- 我们致力于将阿里巴巴的优秀技术和沉淀,通过云产品的形式提供给广大公有云的用户,如DTS——数据传输,DMS——数据管理,CloudDBA——用户身边的数据库专家。
2. 交易查询优化
在2014年双11时,交易的AliSQL秒级查询量已经到了一个天量。虽然当天交易系统一切平稳,但交易的数据库负责人深知这数字背后隐藏的风险。
为了保障交易系统下一年的稳定,数据库团队在2015年花了大量的时间,深入了解业务特点,分析每一次查询SQL,最终产出在优化器中注入PK_Access的优化方案。
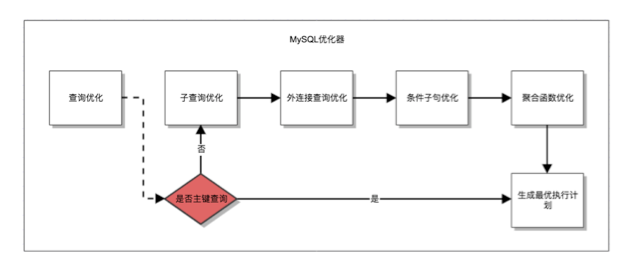
当2015年双11来临时,交易的秒级查询量再次达到一个峰值,这一切都在掌握之中。PK_Access优化方案让交易库的查询能力提升了27%,RT下降48%。
光鲜数据的背后,不只是一个数据库优化方案的结果,更多的是交易业务系统一堆人花了大量的时间梳理接口并确定流控阈值的结果。这里有这么一个数据,2015年交易系统的对外限流预案一共有125个。回想起交易同学的一句话,“如果明年还需要这样,我肯定疯了”。业务同学的话让我们反思,系统能力的提升 不能建立在业务缺失的基础上。
再次回到pk_access的方案,交易的查询在目前的条件下,已经做到了最优,server层的sql_parse是瓶颈点,但是在sql的方式下,没有办法提高更多了。那么能不能将sql_parse也省掉呢?这个时候我们想到了被人遗忘的MySQL插件,InnoDB memcached plugin。

由于插件本身的使用场景偏少,且自身的功能缺失,一直并未广泛使用。换句话说,这是一块未被开发的沃土。从原理上证明这是一个有效方案之后,数据库团队马上集中精力,说干就干。最终修复bug 15个,新功能开发6个,才满足了交易的基本查询。测试中发现,在完整交易场景下,memcached plugin和SQL的对比结果来看,memcached plugin qps可以达到42万,SQL才能达到12万,qps提升了接近4倍。在单SQL场景下,交易单条查询接口的rt下降约30%。在相同流量的引流测试中,通过memcached plugin查询,应用load 4.8,cpu 45%;通过sql查询,应用load 13,cpu 72%。通过各个维度的比较,memcached plugin带来的收益远远超出每个人的预期。
就在刚刚落幕的2016年双11,交易系统秒级查询量突破千万,再次刷新秒级查询量,也是数据库团队第一个秒级破千万的系统。这一次的增长可谓是“爆炸式”的。
从今年交易数据库运行情况来看:
- 数据库不扩容,整体压力翻翻,并且仍有一定的余量。
- 业务降级预案大幅减少,做到对业务无损。
- 交易应用服务器扩容大幅减少。业务访问数据库从SQL接口切换到Memcached接口之后,还带来的一个显著优化就是应用服务器的CPU开销大幅降低,这也导致最终需要扩容的应用服务器数量大幅减少。
3. 库存中心扣减能力提升
热点库存,相信无论是有多年双11备战经验的技术同学,还是资深的剁手党,对这个名词都不会感到陌生。因为每年双11,总有那么些爆款商品特别热销,大家的抢购热情异常高涨,这几年双11,小米/华为手机、优衣库衣服等,都曾经加入过这个热点商品的家族之中。其实,热点商品是一直存在的,但是热点商品带来的问题,我们是2012年底2013年初才真正意识到的。
从那时起,2013、2014、2015、2016,每一年我们在AliSQL内核层面针对此问题都有优化,优化单Key(单商品)的秒级扣减能力。但是,只有今年,我们将此问题做到了技术上的极致,未来可以预见的几年内,库存热点问题,将从双11备战中消失。
2013年,2014年和2015年,库存中心随着AliSQL版本升级和硬件升级,轻轻松松渡过了双11的技术大考,AliSQL的单行扣减能力,从原生MySQL的每秒500笔,提升到了2015年的每秒5000笔。
轻松并不等于放松,阿里人绝对不会满足现状,如何才能继续提升单行扣减性能?答案是批处理!我们认真思考了2013年做的优化,它们都有一个共同点,就是在串行的基础上进行的,而且已经做到极致。于是我们想到了是否可以通过批处理来提高吞吐。2016年经过半年的闭关开发测试,“史诗级怪兽”补丁hotspot横空出世;

通过添加两条流水线轮流提交,并且使用group commit,在双11来临之前的一次测试,我们成功的将单行热点扣减能力提升到了10万,有20倍以上的提升,并且可实现自动的热点识别,不影响非热点商品的正常扣减。在跟库存应用完成对接之后,几次全链路压测,AliSQL的热点处理能力甚至远高于下游的处理能力。
2016年双11,数据库使用新版本的补丁平稳运行。按照双11实际的表现来看,未来几年内,库存热点问题将彻底告别双11的历史舞台。
4. 数据库大中台全面升级
数据库最重要的是数据和SQL,数据表示结果,SQL表示过程,两者缺一不可。
在2011年初,数据库第一代监控体系tianji成型,其中包含了基于定量收集网络包的SQL采集工具MyAWR,标志着第一代数据库SQL采集体系正式形成。这种方式是通过TCPDUMP抓取1万个网络包,然后将抓取到的网络包解析成SQL语句,最后算出单位时间内的SQL数,反推出某时间段内的整体SQL情况,用公式表达为:
每分钟SQL数 = 每万个网络包的SQL数 * 60秒 / 每万个网络包的耗时
这种方式存在一个非常大的弊端,就是准确度的问题。But better than nothing。这种方式一直持续到2013年。
2014年至2015年,数据库团队自研MySQL插件DAM(DataBase Activity Monitor),用于记录数据库的执行事件,从安全方面来对数据库异常活动进行监测和审计。但后面由于资源和使用的问题,DAM项目失败,继续沿用着MyAWR。
2016年,倔强的我们再次提出全量SQL采集的目标,并且要求双11当天也能采集,采集内容不仅只是SQL文本,还需要了每一条SQL的运行时间、扫描行数等关键信息。换句话描述,就是要求数据库以INFO级别打印数据库日志。这是一次史无前例的挑战。设想一下,当一个数据库在1万/秒的请求压力下,还要1万/秒的输出日志,这无论对磁盘和数据库本身都是非常苛刻的要求。
这一次团队内高度合作,有团队保证高性能的全量SQL输出,有团队保证高效的全量采集,有团队保证海量存储,有团队保证精准分析和使用。最终完成了第二代全量SQL采集系统。

在ODPS上,我们可以进行全面的SQL分析计算,如10分钟内有多少用户连续下单等问题。在AliRocks上,我们可以精准的给出SQL直方图,如TOP SQL问题。
2016年双11当天,我们打开了集团交易核心集群的全量SQL采集功能。当天全量SQL输出对数据库仅有5%不到的影响,并且实时计算峰值处理速度为每秒千万级别,平均处理速度每秒百万级别,全天实时性能计算延迟平均在100ms以下。 全量SQL流水目前都存入SLS/ODPS中,实时性能计算数据存储在AliRocks中。这是我们第一次真正获取到了双11 100%的SQL信息,为今后留下了一笔宝贵的财富。
今天,基于全量采集的SQL信息,我们的CloudDBA不仅将全部SQL流水存储做离线分析,双11当天我们还通过实时计算分析出SQL实时性能数据。有了这些基础数据只是开始,后面我们会基于这些基础数据借助数据挖掘和机器学习等手段,帮助用户更多维度地理解业务数据趋势,提供主动的异常发现/诊断,资源预估等更丰富的数据库服务。 帮助用户不仅能够通过CloudDBA自助地诊断和优化自己的数据库,还能够通过CloudDBA更好地理解业务如何使用数据库以及如何用好数据库。

同样在双11负责传输海量数据的中台另一重要基础设施,就是DRC(Data Replication Center)。DRC负责解析增量数据库日志,分发给大数据、搜索和应用,同时负责异地多活数据同步。随着实时数据计算业务的增长,DRC任务数增长迅速,今年DRC集群架构做了重大突破,能够单集群支撑数万个数据同步进程,对外自动化接入API响应时间减半,通过akka框架使得集群容灾速度得到极大提升,通过合并一个Region(地区)的集群和自动负载均衡降低整体运营成本,以更低的成本和更高的稳定性支撑了更大的双11峰值压力。
在性能上,DRC解析核心做了很大的技术优化,同时在同步链路上通过bucket冲突算法优化和热点合并技术提升了峰值同步能力,在分发链路通过连接池化技术,使得单个解析存储进程可以同时分发给上千个下游用户,对业务快速接入和低成本共享数据通道的能力打下坚实的基础。DRC支撑了异地多活下,多个异地机房间的数据亚秒级同步,在双11这样的峰值压力下,依然保障了500ms以内的数据库端到端同步延时。
2016年DRC除了在性能和规模支撑能力得到提升,我们还在数据质量上精益求精,今年DRC全面开启了行校验做数据同步,支持数据加密传输。对于上游数据源的变化做到了自动化联动,包括数据库的迁移和拆分,使得订阅实时数据的下游业务完全无需感知。DRC在队列存储上开放了完整的SQL查询能力,使得下游用户可以通过SQL很快查到1条记录,在DRC通道里是否存在,快速定位数据质量问题。同时这个能力支持了部分用户做数据对账和灵活轻量的增量报表,拓展了DRC的服务能力。可以预见,DRC在未来将给业务带来更多超越预期的价值。
总结
以上几个例子仅仅只是阿里巴巴数据库团队在今年双11中众多优化中的几个,同样还有很多优秀的内容无法一一为大家道来。正如开篇提到的一样,数据库团队是一个有追求的团队,面对技术,我们追求极致,面对未知,我们勇于挑战。
2016年双11已经过去,但是数据库团队已经放下了过去取得种种成绩,准备重新出发了,2017年,AliSQL5.7、AliSQL X-Cluster (基于三副本Paxos/Raft协议的AliSQL)、AliRocks (基于RocksDB存储引擎的AliSQL分支)、Ceph On AliSQL(存储计算分离)、DBPaas,CloudDBA等等每一件事都已经在路上,而且样样极具挑战。
海到无边天作岸,山登绝顶我为峰,如果正在阅读的你热衷新事物,追求极致,敢于挑战,那么就不要犹豫,赶快加入我们。