最近在写一个项目的后台时,前端请求指定资源后,返回JSON格式的数据,突然发现在返回的字节数过大时,最后的message中文数据乱码了,对于同一个接口的请求:当数据小时不会乱码,当数据量大了中文就乱码了。
基本的Controller代码如上,有的人也许一眼发现了问题所在,有人会质疑我的写法,但是在这里我想找的不是这个。
对于这个情况,在抓包后得到的状况如下:(记住大概你觉得陌生的地方,继续往下看)


可以明显的观察到,这里在中文乱码时出现了更多的TCP数据报。
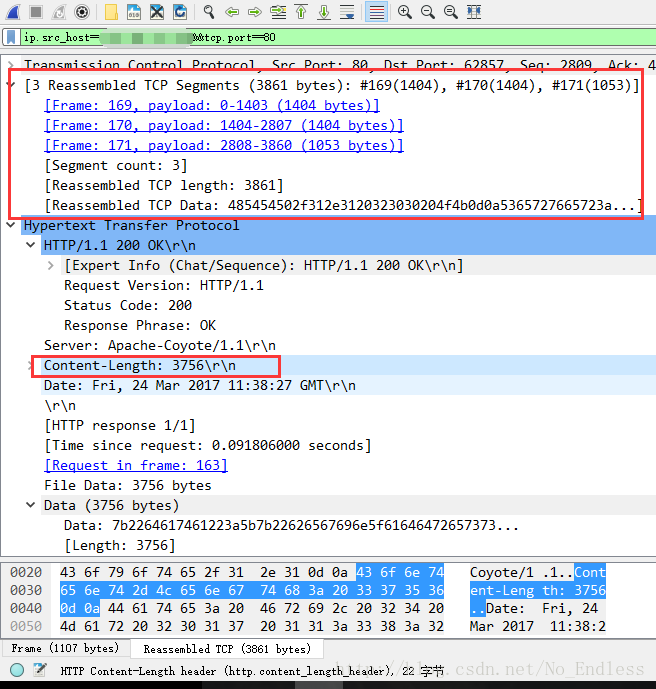
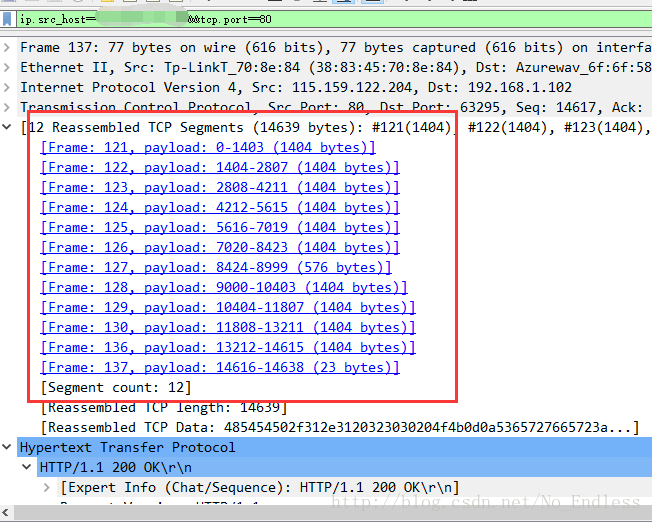
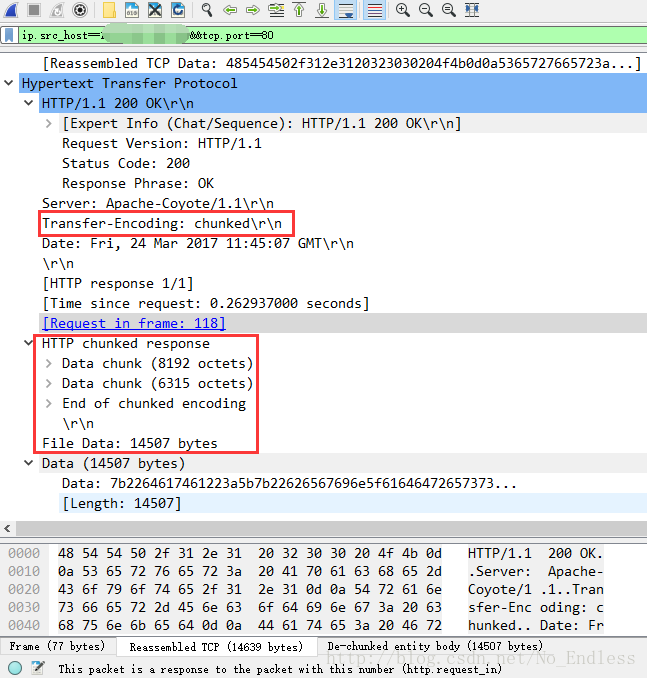
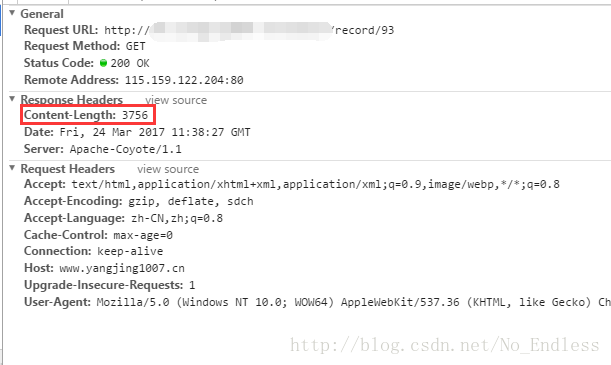
到了抓包的地方,我们就可以观察到HTTP响应头发生了变化,在正常状态下,会返回Content-Length,但是在数据很多,即中文乱码的情况下,Content-Length属性被Transfer-Encoding:chunked属性取代了。



一开始想修改一下Chrome浏览器的编码试试,但是发现在Chrome 55之后的版本,字符集编码的修改功能被移除了。按照Google方面的说法如下:
大概就是,自动检查分析字符集的功能虽然使出现乱码的情况减少,但是拖慢了页面加载时间大概10%~20%;选择功能同时会在页面已经声明其编码的情况下有几率地,使用户因为自己设置的编码而看到乱码,所以页面声明编码时,直接调用选择,否则,默认使用Chrome的UI语言。
当不能预先确定报文体的长度时,或是报文长度过长时,无法使用Content-Length来指明报文体长度,此时就需要通过Transfer-Encoding域来代替。
Transfer-Encoding:chunked用于http传送过程的分块传输技术,原因是http服务器响应的报文长度经常是不可预测的,使用Content-length的实体搜捕并不是总是管用。
分块技术的意思是说,实体被分成许多的块(Data
chunk),也就是应用层的数据,TCP在传送的过程中,不对它们做任何的解释,而是把应用层产生数据全部理解成二进制流,然后按照一定的长度切成一段的,然后一次性给TCP协议去传输,而具体这些二进制的数据如何做解释,需要应用层来完成,所以在这之前,一快整体应用层的数据需要等它分成的所有TCP
segment到达对方,重新组装后,应用程序才使用自己的解码方法还原它们。
分块传输时,我们设置的CharacterEncoding无效了,其实当Transfer-Encoding时,编码格式就是它的值——chunked,采用chunked编码方式来进行报文体的传输,基本方法是将大块数据分解成多块小数据,每块都可以自指定长度。chunked编码是HTTP/1.1 RFC里定义的一种编码方式,因此所有的HTTP/1.1应用都应当支持此方式。
chunked编码格式在RFC中定义如下:

chunked编码为了分块传输数据,将一个数据信息分成多个有自己长度的块,这样就允许在不知道长度的情况下动态的去传输数据信息,Chunked-Body分块由CRLF(回车换行符)进行分隔,包含有一个16进制的长度size信息和一个数据为“0”的chunk块来表示数据传输完毕。
写了这么多,如果我们回头看就会发现一些对应的HTTP报文,以及问题的根源!
好吧…对于最后,记得在返回JSON时中加入代码段取代简单的设置字符集:
这是我失误的地方,字符集的指定最后还是被chunk给打败了,也许是优先级不够吧,但是也学到了很多东西。