首先注意版本兼容问题!!!本文采用的是Scala 2.11.8 + Hadoop 2.7.5 + Spark 2.2.0
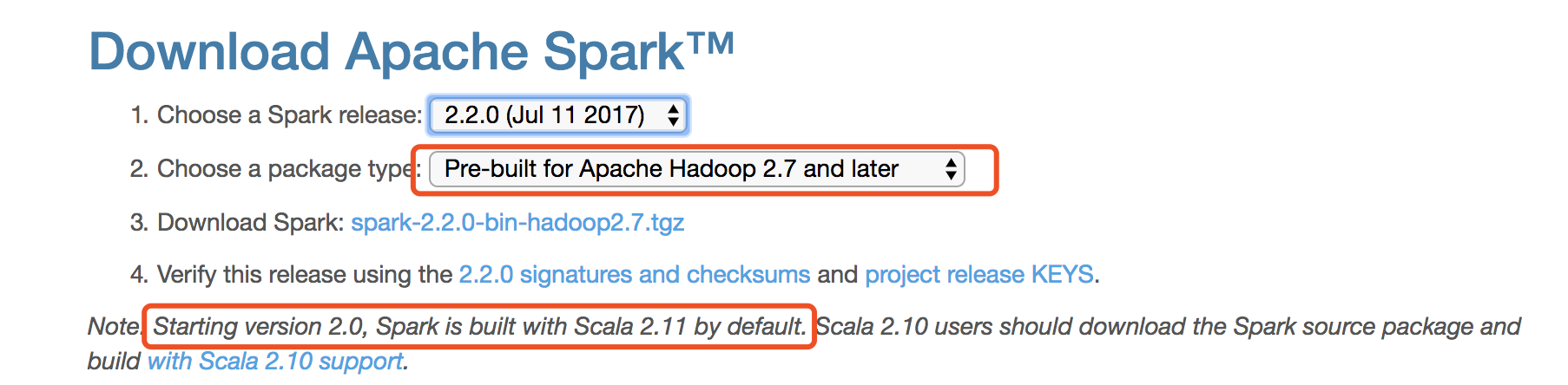
请在下载Spark时务必看清对应的Scala和Hadoop版本!
一、配置JDK
1. 下载jdk
http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
2. 配置环境变量
(1)在终端使用 sudo su 命令进入root用户模式;
(2)使用 vim /etc/profile 命令打开profile文件,按下大写“I”进入编辑模式,在文件中添加以下信息:
JAVA_HOME对应的是你的JDK安装路径
JAVA_HOME="/Library/Java/JavaVirtualMachines/jdk1.8.0_151.jdk/Contents/Home" CLASS_PATH="$JAVA_HOME/lib" PATH=".;$PATH:$JAVA_HOME/bin" export JAVA_HOME
(3)使用“esc”键推出编辑模式,按下“:”,输入wq并回车,保存且退出。
(4)退出终端并重新打开,输入 java -version 命令查看JDK配置情况。也可以直接输入命令 source /etc/profile 使修改信息立即生效。配置成功信息如下图所示。
![]()
二、配置Scala
1. 下载Scala
Scala 2.11.8下载链接:http://www.scala-lang.org/download/2.11.8.html
2. 将下载的scala压缩文件解压后复制到/usr/local/Cellar文件夹下(位置无具体要求,按个人习惯,最好将scala、hadoop和spark放在同一位置)

3. 配置Scala环境
(1)与配置JDK一样的步骤,使用 vim /etc/profile 命令进入编辑模式,添加以下信息(对应你的解压路径):
export PATH="$PATH:/usr/local/Cellar/scala-2.11.8/bin"
(2)使用 source /etc/profile 命令使修改生效,输入 scala 检查配置是否成功。配置成功信息如下所示。

三、配置SSH无密码登陆
配置ssh就是为了能够实现免密登录,这样方便远程管理Hadoop并无需登录密码在Hadoop集群上共享文件资源。
1. 输入 ssh-keygen -t rsa 命令,然后一直回车即可,输出以下信息便设置成功。
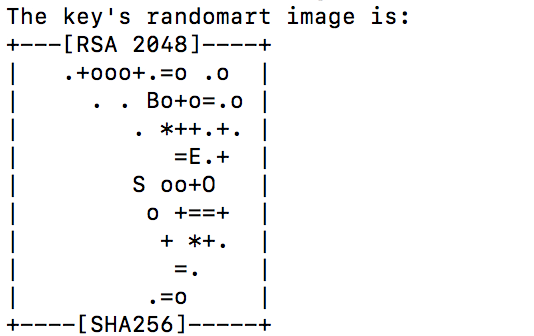
2. 输入 cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys 授权你的公钥到本地可以无需密码实现登录;
3. 进入root模式,使用 chmod 700 .ssh 命令对.ssh赋予权限;
4. 然后使用 cd .ssh 命令进入该目录,使用 chmod 600 authorized_keys 对authorized_keys赋予权限;
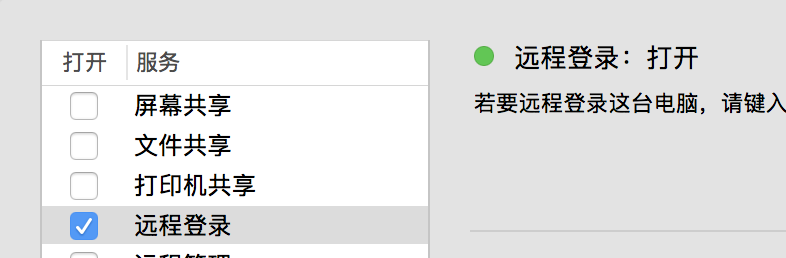
5. 打开系统偏好设置->共享->打开远程登录
6. 在root模式下输入 ssh localhost 命令进行测试,测试成功结果如下所示。
![]()
四、下载并配置Hadoop
1. 下载Hadoop
Hadoop 2.7.5镜像下载链接:http://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-2.7.5/hadoop-2.7.5.tar.gz
2. 将下载后的压缩文件复制到/usr/local/Cellar目录下并解压
3. 配置Hadoop
(1)使用 cd /usr/local/Cellar/hadoop-2.7.5/etc/hadoop/ 进入Hadoop配置目录,找到“hadoop-env.sh”文件
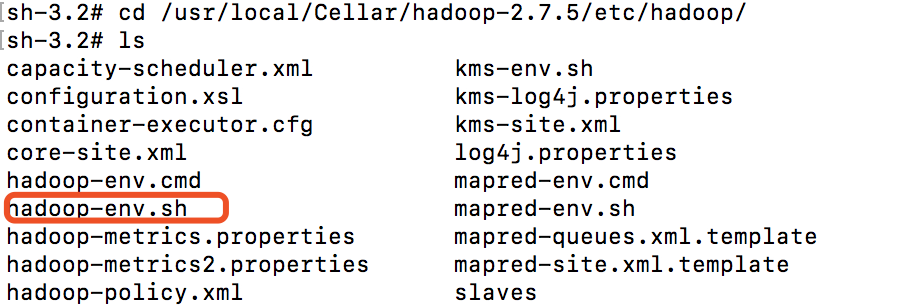
(2)配置Hadoop环境
使用 vim hadoop-env.sh 命令进行编辑,找到并修改以下信息:(注意:JAVA_HOME是你自己之前配置的)
export HADOOP_OPTS="$HADOOP_OPTS -Djava.net.preferIPv4Stack=true -Djava.security.krb5.realm= -Djava.security.krb5.kdc="
export JAVA_HOME="/Library/Java/JavaVirtualMachines/jdk1.8.0_151.jdk/Contents/Home"
(3) 配置hdfs地址和端口
使用 vim core-site.xml 命令进行编辑,将“<configuration></configuration>”替换为以下信息:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop-2.7.5/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration><configuration>
fs.defaultFS用于设置Hadoop的默认文件系统,设置为“hdfs://localhost:9000”。HDFS的守护程序通过该属性项来确定HDFS namenode的主机和端口。
(4)配置HDFS的默认参数副本数
使用 vim hdfs-site.xml 命令进行编辑,将“<configuration></configuration>”替换为以下信息:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop-2.7.5/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop-2.7.5/tmp/dfs/data</value>
</property>
</configuration>
dfs.replication的value设置为“1”,这样HDFS就不会按默认设置将文件系统块复本设置为3。否则在单独一个datanode上运行时,HDFS无法将块复制到3个datanode上,所以会持续给出块复本不足的警告。
(5)配置mapreduce中jobtracker的地址和端口
使用 vim mapred-site.xml.template 命令进行编辑,将“<configuration></configuration>”替换为以下信息:
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>localhost:9001</value>
</property>
</configuration>
(6)接着修改配置文件 yarn-site.xml
添加以下信息:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
(7)文件系统初始化
进入到Hadoop安装路径的bin目录下,使用命令 ./hadoop namenode -format 进行初始化,初始化成功会输出以下信息,注意红框标记处。

(8)配置Hadoop环境变量
目的是方便在任意目录下全局开启关闭hadoop相关服务,而不需要到/usr/local/Cellar/hadoop/2.7.5/sbin下去执行启动或关闭命令。使用命令 vim ~/.zshrac 进行编辑,添加以下内容:(注意:zshrac是自己创建的,不要纠结自己找不到这个文件)
export HADOOP_HOME=/usr/local/Cellar/hadoop-2.7.5
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
然后使用 source ~/.zshrac 命令使修改生效,以上关于Hadoop的配置全部结束。
4. 启动Hadoop
(1)启动/关闭Hadoop服务
使用命令 start-dfs.sh 启动,然后使用 jps 命令查看启动结果,启动成功如下图所示:

我们在浏览器中输入http://localhost:50070打开以下网页,可以查看 NameNode 和 Datanode 信息,还可以在线查看 HDFS 中的文件。
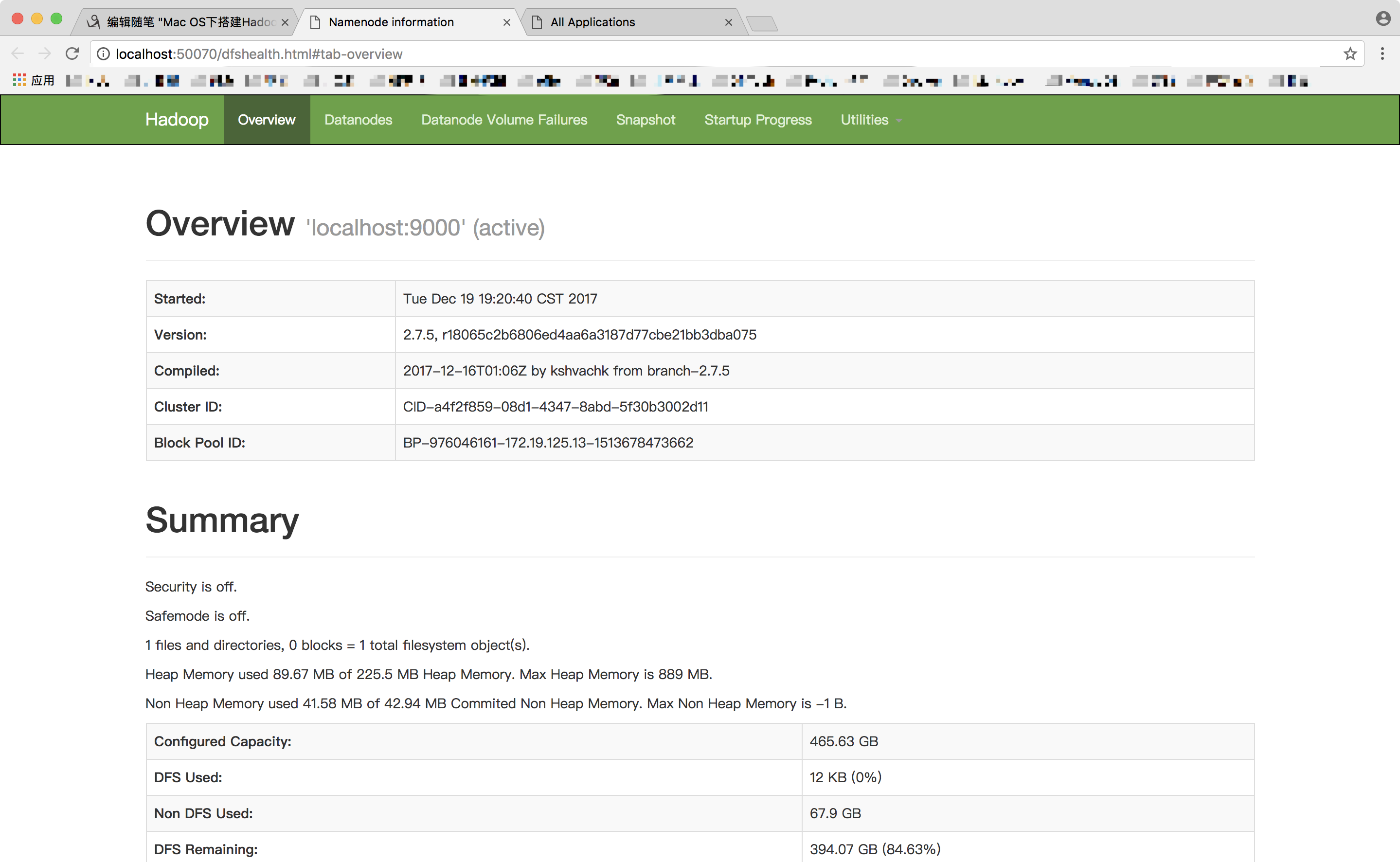
使用 stop-dfs.sh 关闭Hadoop服务。
(2)启动/关闭yarn服务
使用 start-yarn.sh 命令启动yarn服务,让 yarn来负责资源管理与任务调度。启动成功后,使用 jps 命令可以输出以下信息:
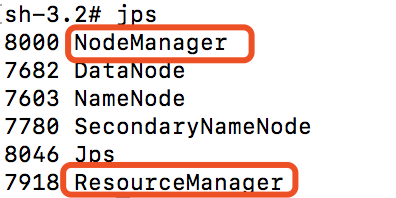
比之前只启动Hadoop服务时多了一个NodeManager和ResourceManager,然后在浏览器中打开http://localhost:8088,可以通过 Web 界面查看任务的运行情况。
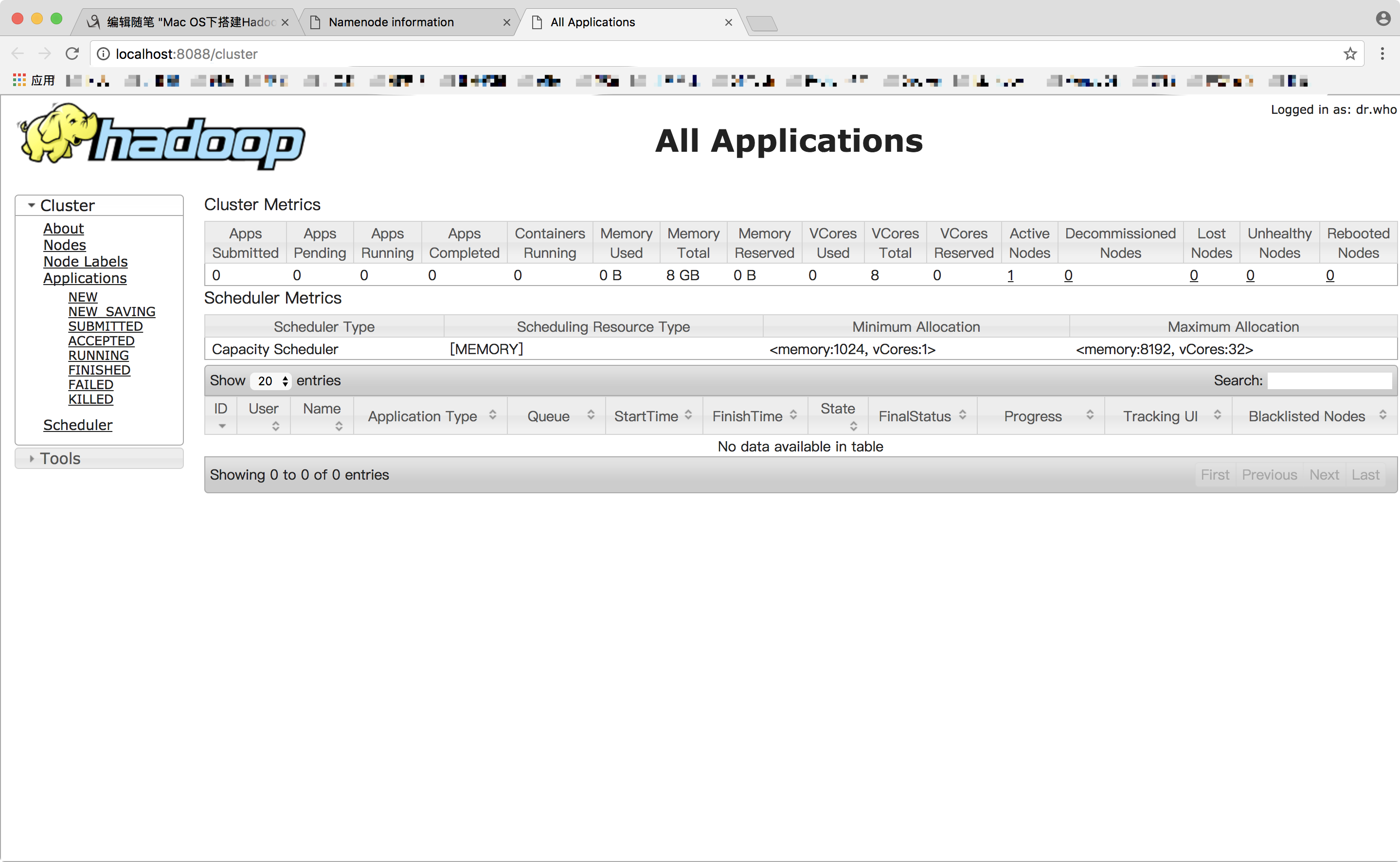
关闭yarn服务时,输入以下命令 stop-yarn.sh
(3) 快速启动和关闭
直接使用命令 start-all.sh 和 stop-all.sh 可以同时启动Hadoop服务和yarn服务,比依次启动和关闭方便很多。
2017-12-19 19:49:47