1. 出现字节对齐的动机:cpu的效率,内存的节省
话说第一次碰到字节对齐的时候是在今年六月实习的时候,有一次我在调用一个接口,把数据从那个借口复制过来,但是在那个借口的时候参数是正确的,一旦复制出来以后,参数就出错了,找了好久,后来大牛过来找了找,原来是在接口的时候数据是按一个字节对齐,接受的数据是取消指定对齐,所以就出问题了。
一般在内存充裕的时候我们是取消指定对齐的,因为这可以加快CPU的寻找数据的时间,因为 (比如有些平台每次读都是从偶地址开始,如果一个int型(假设为32位系统)如果存放在偶地址开始的地方,那 么一个读周期就可以读出这32bit,而如果存放在奇地址开始的地方,就需要2个读周期)
而在单片机之类的arm芯片,内存是比较小的,这是就会用按指定的字节对齐以节约内存(虽然会牺牲一些时间)。
观察程序:
#include<stdio.h> //#pragma pack(1) struct data{ long long f; int a,b; char s; long long f2; char s2; }; //#pragma pack () int main(){ data temp; temp.f=0x1111111122222222; temp.a=temp.b=0x22221111; temp.s='X'; temp.f2=0x1111111122222222; printf("%d ",sizeof(data)); }
输出的是40
观察内存:
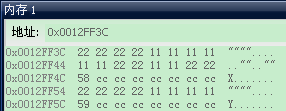
可以看到f 占了八字节的,后面两个int变量占据后面8字节
char占了一个字节,但后面long long型要跟第一个变量首地址偏移8的整数倍位置上,所以变量f2与s中间插入了7个字节的填充量,后面s2变量也是同样,结束时后面插入了7个字节的填充量。
2.按1字节对齐
#include<stdio.h> #pragma pack(1)//开始按一个字节对齐 struct data{ long long f; int a,b; char s; long long f2; char s2; }; #pragma pack ()//取消按指定字节对齐 int main(){ data temp; temp.f=0x1111111122222222; temp.a=temp.b=0x22221111; temp.s='X'; temp.f2=0x1111111122222222; temp.s2='Y'; printf("%d ",sizeof(data)); }
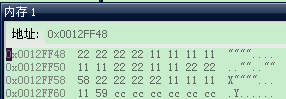
输出26
因为是按1个字节对齐,内存中没有填充,全部利用到了
3.字节对齐的意义:在系统自动对齐的时候改变结构体的数据的顺序,可以在不影响CPU效率的情况下减少内存占用
#include<stdio.h> struct data{ long long f; int a,b; char s; long long f2; char s2; }; struct data2{ long long f; int a,b; char s,s2; long long f2; }; int main(){ printf("%d ",sizeof(data)); printf("%d ",sizeof(data2)); }
40
30
两者数据没有区别,但后者内存空间占用更少