摘要:本文提出了一种基于Transformer的端到端的线段检测模型。采用多尺度的Encoder/Decoder算法,可以得到比较准确的线端点坐标。作者直接用预测的线段端点和Ground truth的端点的距离作为目标函数,可以更好的对线段端点坐标进行回归。
本文分享自华为云社区《论文解读系列十七:基于Transformer的直线段检测》,作者:cver。

1 文章摘要
传统的形态学线段检测首先要对图像进行边缘检测,然后进行后处理得到线段的检测结果。一般的深度学习方法,首先要得到线段端点和线的热力图特征,然后进行融合处理得到线的检测结果。作者提出了一种新的基于Transformer的方法,无需进行边缘检测、也无需端点和线的热力图特征,端到端的直接得到线段的检测结果,也即线段的端点坐标。
线段检测属于目标检测的范畴,本文提出的线段检测模型LETR是在DETR(End-to-End Object Detection with Transformers)的基础上的扩展,区别就是Decoder在最后预测和回归的时候,一个是回归的box的中心点、宽、高值,一个是回归的线的端点坐标。
因此,接下来首先介绍一下DETR是如何利用Transformer进行目标检测的。之后重点介绍一下LETR独有的一些内容。
2、如何利用Transformer进行目标检测(DETR)
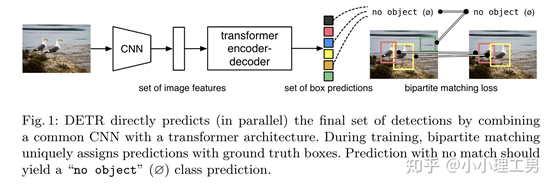
图1. DETR模型结构
上图是DETR的模型结构。DETR首先利用一个CNN 的backbone提取图像的features,编码之后输入Transformer模型得到N个预测的box,然后利用FFN进行分类和坐标回归,这一部分和传统的目标检测类似,之后把N个预测的box和M个真实的box进行二分匹配(N>M,多出的为空类,即没有物体,坐标值直接设置为0)。利用匹配结果和匹配的loss更新权重参数,得到最终的box的检测结果和类别。这里有几个关键点:
首先是图像特征的序列化和编码。
CNN-backbone输出的特征的维度为C*H*W,首先用1*1的conv进行降维,将channel从C压缩到d, 得到d*H*W的特征图。之后合并H、W两个维度,特征图的维度变为d*HW。序列化的特征图丢失了原图的位置信息,因此需要再加上position encoding特征,得到最终序列化编码的特征。
然后是Transformer的Decoder
目标检测的Transformer的Decoder是一次处理全部的Decoder输入,也即 object queries,和原始的Transformer从左到右一个一个输出略有不同。
另外一点Decoder的输入是随机初始化的,并且是可以训练更新的。
二分匹配
Transformer的Decoder输出了N个object proposal ,我们并不知道它和真实的Ground truth的对应关系,因此需要经二分图匹配,采用的是匈牙利算法,得到一个使的匹配loss最小的匹配。匹配loss如下:

得到最终匹配后,利用这个loss和分类loss更新参数。
3、LETR模型结构

图2. LETR模型结构
Transformer的结构主要包括Encoder、Decoder 和 FFN。每个Encoder包含一个self-attention和feed-forward两个子层。Decoder 除了self-attention和feed-forward还包含cross-attention。注意力机制:注意力机制和原始的Transformer类似,唯一的不同就是Decoder的cross-attention,上文已经做了介绍,就不再赘述。
Coarse-to-Fine 策略
从上图中可以看出LETR包含了两个Transformer。作者称此为a multi-scale Encoder/Decoder strategy,两个Transformer分别称之为Coarse Encoder/Decoder,Fine Encoder/Decoder。也就是先用CNN backbone深层的小尺度的feature map(ResNet的conv5,feature map的尺寸为原图尺寸的1/32,通道数为2048) 训练一个Transformer,即Coarse Encoder/Decoder,得到粗粒度的线段的特征(训练的时候固定Fine Encoder/Decoder,只更新Coarse Encoder/Decoder的参数)。然后把Coarse Decoder的输出作为Fine Decoder的输入,再训练一个Transformer,即Fine Encoder/Decoder。Fine Encoder的输入是CNN backbone浅层的feature map(ResNet的conv4,feature map的尺寸为原图尺寸的1/16,通道数为1024),比深层的feature map具有更大的维度,可以更好的利用图像的高分辨率信息。
注:CNN的backbone深层和浅层的feature map特征都需要先通过1*1的卷积把通道数都降到256维,再作为Transformer的输入
二分匹配
和DETR一样, 利用fine Decoder的N个输出进行分类和回归,得到N个线段的预测结果。但是我们并不知道N个预测结果和M个真实的线段的对应关系,并且N还要大于M。这个时候我们就要进行二分匹配。所谓的二分匹配就是找到一个对应关系,使得匹配loss最小,因此我们需要给出匹配的loss,和上面DERT的表达式一样,只不过这一项略有不同,一个是GIou一个是线段的端点距离。
4、模型测试结果
模型在Wireframe和YorkUrban数据集上达到了state-of–the-arts。

图3. 线段检测方法效果对比

图4、线段检测方法在两种数据集上的性能指标对比(Table 1);线段检测方法的PR曲线(Figure 6)