摘要:农历新年将至,听说华为云 AI 又将开启智能对对联迎接牛气冲天,让我们拭目以待!作为资深 Copy 攻城狮,想要自己实现一个对对联的模型,是不能可能完成的任务,因此我搜罗了不少前人的实践案例,今天想和大家分享的是 和鲸社区的 rua年糕 贡献的项目-AI 对联,基于 ModelArts 的 「我的笔记本」实现。
华为云EI专家胡琦
一、环境准备
准备环境前,先唠叨几句:ModelArts 是面向开发者的一站式AI开发平台,ModelArts 在人工智能三要素中都有非常出色的表现,数据方面提供海量数据预处理及半自动化标注,算法方面除了开发者自己开发还=提供大量的预置算法和订阅算法可供选择,算力方面目前开发环境提供免费算力以及即点即用的「我的笔记本」。目前个人比较中意的功能就是「我的笔记本」,如果您体验过 MindSpore 教程的 「Run in ModelArts」,您会发现其实教程中链接的就是 ModelArts 的 「我的笔记本」模块,具体体验可阅读我的历史文章5分钟在线体验MindSpore的图层IR--MindIR。
相比常规的开发先要装一堆的环境和软件,基于 ModelArts 的 AI 开发似乎变得更简单,理论上有能上网的设备就够了,比如 pad,然后仅仅需要注册一个华为云账号并实名认证。当然,ModelArts准备工作并不仅仅是这些,比如如需用到 OBS 还需生成访问密钥并完成 ModelArts 全局配置。具体操作请参考ModelArts-Lab:https://gitee.com/ModelArts/ModelArts-Lab。
Free 的「我的笔记本」就在 ModelArts 总览页底部的开发工具卡片中,点击「立即体验」即可开启一个默认的 CPU 环境的 JupyterLab,我们可以在右边的「切换规格」栏进行环境或者规格的切换。需要注意的是:切换资源后,将影响实例下所有Notebook与Terminal。Notebook中执行的所有变量将失效,Terminal需要重新打开,手动安装包不再生效,需要重新执行。 目前, CPU 和 GPU 环境支持 Conda-python3 、Pytorch-1.0.0、TensorFlow-1.13.1等8种Notebook环境,不过使用 GPU 需要注意:1、免费规格用于使用体验,会在1小时后自动停止;2、免费算力不包含对象存储服务(OBS)存储资源费用。 如果想使用 MindSpore 框架,可以从 MindSpore 官方文档教程中的 「Run in ModelArts」进行跳转到带有 MindSpore 框架的 JupyterLab。
二、Seq2Seq 简介
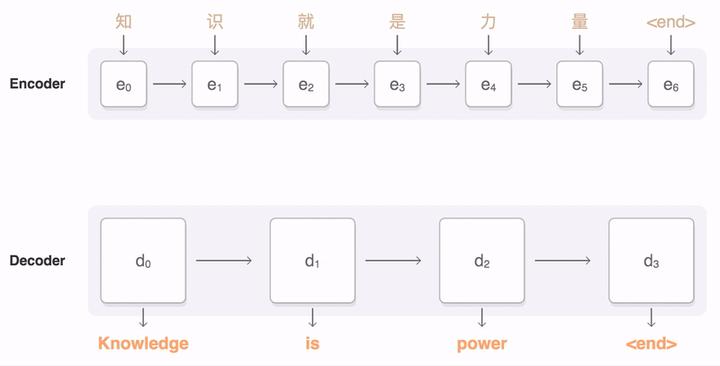
Seq2Seq是 Google 在 2017年开源的一款用于 TensorFlow 的通用编码器&解码器框架(encoder-decoder framework),可用于机器翻译、文本摘要、会话建模、图像描述等。
论文地址: https://arxiv.org/abs/1703.03906
三、Copy 实践
新建 TensorFlow 1.13.1 环境的 notebook 文件,开始代码编(kao)写(bei)。
-
数据集下载
couplet-dataset 尽管比较陈旧,但拥有 70 万条数据,应该够实现一个简单的对对联模型。
!wget https://github.com/wb14123/couplet-dataset/releases/download/1.0/couplet.tar.gz !tar -xzvf couplet.tar.gz !mkdir couplet/model
-
依赖安装及引用
!pip install klab-autotime !pip install backcall import codecs import numpy as np from keras.models import Model from keras.layers import * from keras.callbacks import Callback # 显示cell运行时长 %load_ext klab-autotime # 使用GPU import os os.environ["CUDA_DEVICE_ORDER"]="PCI_BUS_ID" # The GPU id to use, usually either "0" or "1" os.environ["CUDA_VISIBLE_DEVICES"]="0"
-
数据处理
# 定义参数 min_count = 2 maxlen = 16 batch_size = 64 char_size = 128 train_input_path = 'couplet/train/in.txt' train_output_path = 'couplet/train/out.txt' test_input_path = 'couplet/test/in.txt' test_output_path = 'couplet/test/out.txt' # 数据读取与切分 def read_data(txtname): txt = codecs.open(txtname, encoding='utf-8').readlines() txt = [line.strip().split(' ') for line in txt] # 每行按空格切分 txt = [line for line in txt if len(line) <= maxlen] # 过滤掉字数超过maxlen的对联 return txt
-
模型定义
def gated_resnet(x, ksize=3): # 门卷积 + 残差 x_dim = K.int_shape(x)[-1] xo = Conv1D(x_dim*2, ksize, padding='same')(x) return Lambda(lambda x: x[0] * K.sigmoid(x[1][..., :x_dim]) + x[1][..., x_dim:] * K.sigmoid(-x[1][..., :x_dim]))([x, xo]) x_in = Input(shape=(None,)) x = x_in x = Embedding(len(chars)+1, char_size)(x) x = Dropout(0.25)(x) x = gated_resnet(x) x = gated_resnet(x) x = gated_resnet(x) x = gated_resnet(x) x = gated_resnet(x) x = gated_resnet(x) x = Dense(len(chars)+1, activation='softmax')(x)
其他代码此处就不再贴了,建议直接参考源码出处,或者访问https://github.com/hu-qi/modelarts-couplet。此处我选择 200 个 Epoch,训练过程如下图:
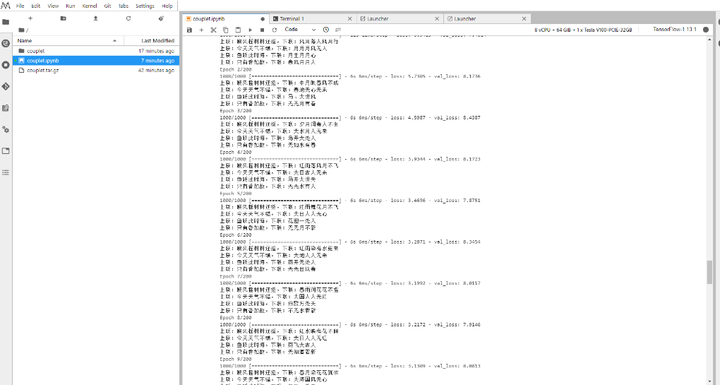
从图中明显可以看出评估函数输出的下联不断地在调整。当训练完成之后我们便炼的了简单能使用的丹--AI 对对联模型,紧接着测试一下:
上联:天增岁月人增寿
下联:国满春秋我成春
上联:鼠去牛来闻虎啸
下联:羊来马去看龙吟
上联:流光溢彩气冲斗牛
下联:春色流辉风震春虫
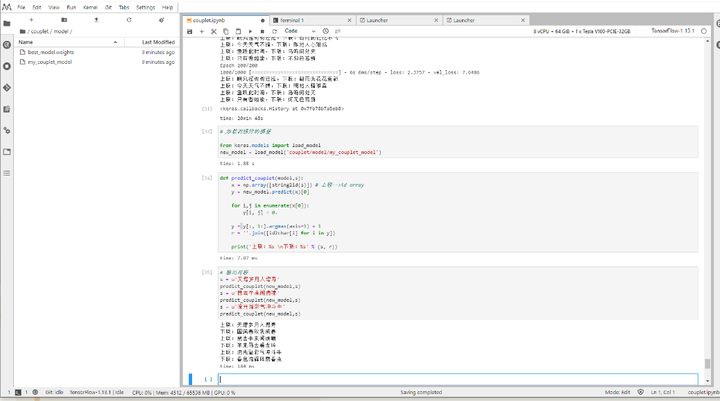
不错不错,还是挺工整通顺的!
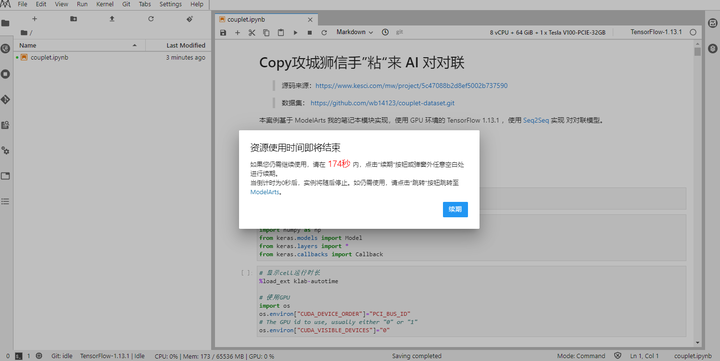
当然实践中也并不是一帆风顺,训练过程中如果遇到续期提示,请务必要手动点击,不然又得重启 Notebook 。续期就对了,尽管我不太清除能续几次,但续期就不会导致训练中断。
四、总结
此次实践的数据集和 notebook 已上传到 github :https://github.com/hu-qi/modelarts-couplet, 另外对联数据也共享到 ModelArts AI Gallery:couplet-dataset:70万对联数据集,欢迎取阅!