网址:http://www.redis.cn/topics/data-types.html
数据类型包括: 字符串,列表,hash ,集合,有序集合,消息队列
一。字符串
字符串是所有编程语言中最常见的和最常用的数据类型,是redis 最基本的数据类型之一
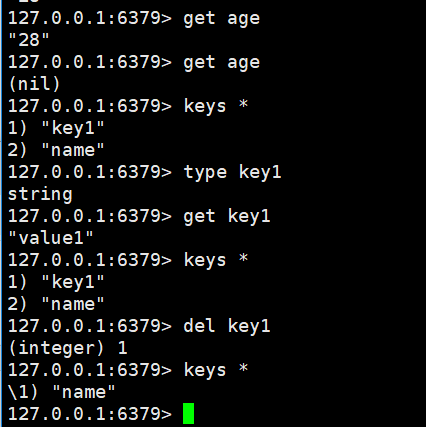
添加一个key :
set key1 value1
获取一个key:
get key1
查看key 值的数据类型
type key1
为key 设置自动过期时间:
set name wxl ex 5 : 5秒后就自动过期了
删除一个key :
del key1
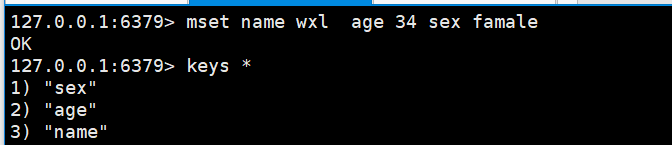
一次性设置多个key :
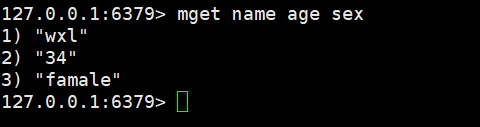
一次性获取多个值:
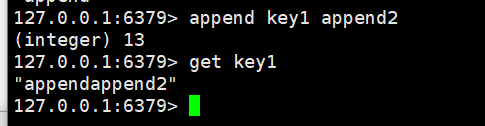
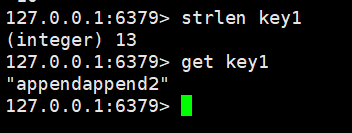
追加数据:
数值递增:
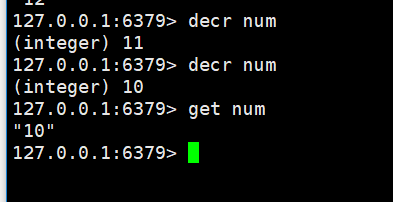
数据递减:
获取字符串key 值的长度:

2 列表
列表是一个双向可读可写的管道,一个列表最多可以包含2^32 -1 个元素即4294967295个元素
1》生成列表并插入数据
127.0.0.1:6379> lpush list1 jack tom john
(integer) 3说明: 从左侧写入数据的,最后数据在列表中是【john ,tom, jack】
127.0.0.1:6379> type list1
list2》获取列表的长度:
127.0.0.1:6379> llen list1
(integer) 33》移除列表中的数据
127.0.0.1:6379> rpop list1
"jack"从右侧移除一个数据
127.0.0.1:6379> lpop list1
"john"从左侧移除一个数据
127.0.0.1:6379>
3.集合
set 是string 类型无序集合,
集合成员是唯一的,也就是集合中不能出现重复的数据
1》生成集合key :
127.0.0.1:6379> sadd set1 v1
(integer) 1
127.0.0.1:6379> sadd set2 v2 v4
(integer) 2
127.0.0.1:6379> type set1
set
127.0.0.1:6379> type set22》追加数值
追加数值的时候不能追加已经存在的数值
127.0.0.1:6379> sadd set1 v2 v3 v4
(integer) 3
127.0.0.1:6379> sadd set1 v2 # 没有追加成功
(integer) 0
127.0.0.1:6379> type set1
set
127.0.0.1:6379> type set23》查看集合的所有数据
127.0.0.1:6379> smembers set1
1) "v2"
2) "v1"
3) "v4"
4) "v3"
127.0.0.1:6379> smembers set2
1) "v2"
2) "v4"
4》集合的差集
差集:属于A 而不属于B
127.0.0.1:6379> sdiff set1 set2
1) "v1"
2) "v3"
127.0.0.1:6379> sdiff set2 set1
(empty array)5》集合的并集
127.0.0.1:6379> sunion set1 set2
1) "v1"
2) "v4"
3) "v3"
4) "v2"6》集合的交集
交集:属于A 也属于B
127.0.0.1:6379> sinter set1 set2
1) "v2"
2) "v4"
127.0.0.1:6379> sinter set2 set2
1) "v2"
2) "v4"
127.0.0.1:6379> sinter set2 set1
1) "v2"
4.有序集合(sorted set )
redis 有序集合也是字符串类型元素的集合,且不容许重复的成员
不同的是每个元素都会关联一个 double(双精度浮点型)类型的分数,redis 正是通过分数来为集合中的成员进行从小到大的排序,有序集合的成员是唯一的,但分数(score)却可以重复,集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是 O(1), 集合中最大的成员数为 2^32 - 1 (4294967295, 每个集合可存储 40 多亿个成员)。
hash 是一个字符串类型的field 和value 的映射表hash 特别适合用于存储对象,redis 中每个hash 可以存储232-1 键值对(40多亿)1》 生成hash key127.0.0.1:6379> hset hset1 name tom age 19
(integer) 2
127.0.0.1:6379> type hset12》获取key 字段值
hash
127.0.0.1:6379> hget hset1 name
"tom"
127.0.0.1:6379> hget hset1 age
"19"
3》删除字段
127.0.0.1:6379> hdel hset1 age
(integer) 1127.0.0.1:6379> hkeys hset1
1) "name"
127.0.0.1:6379>
消息队列主要分为两种: 生产者消费模式和发布订阅者模式1》生产者消费者模式原理: 上层应用接收到外部请求后开始处理其当前步骤的操作,将已经完成的操作发送到指定的频道中,下层的应用监听该频道和处理,然后返回数据到外部请求在生产者消费者模式下,多个消费者同时监听一个队里,但一个消息智能消费一次此模式在分布式业务架构中非常常用,消息一次性读取和处理比较常用的软件有 rabbitMQ ,kafka ,rocketMQ,activeMQ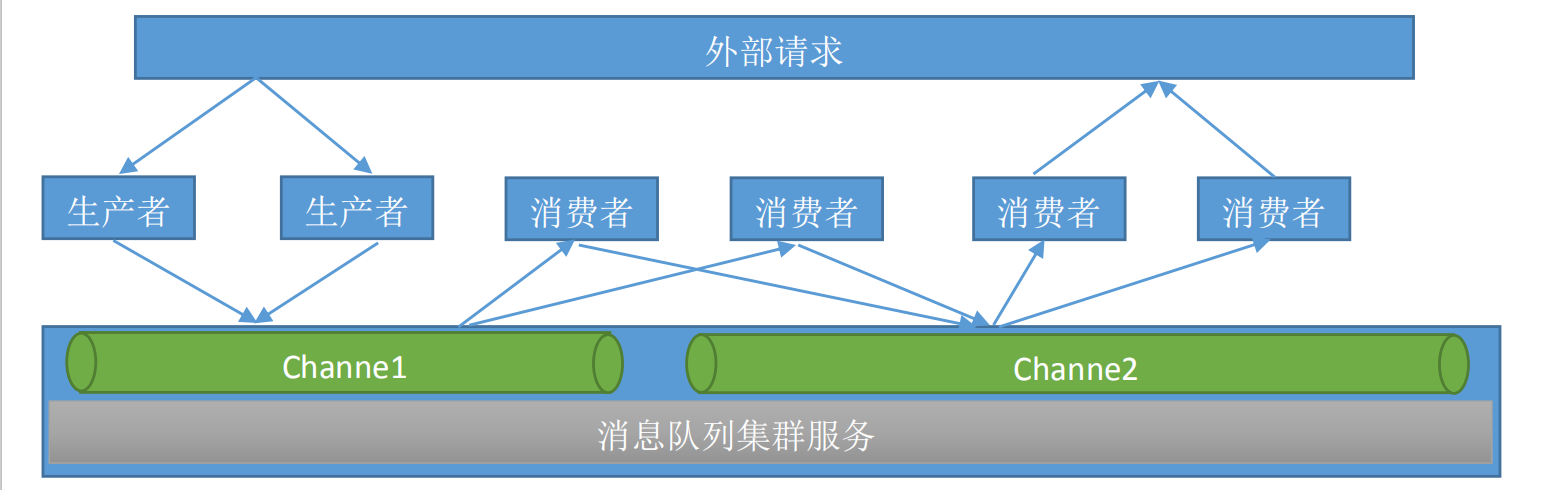
队列的介绍:
队列中消息由不同的生产者写入也会有不同的消费者取出进行消费处理
但是一个消息一定是只能被取出一次 消费一次
例子:
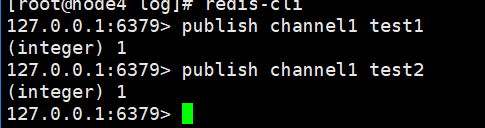
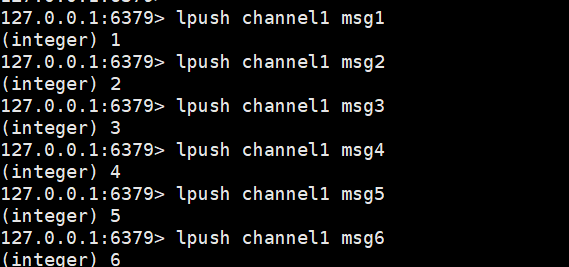
生产者发布消息:
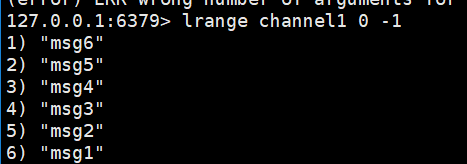
查看队列所有消息:
消费者消费消息:

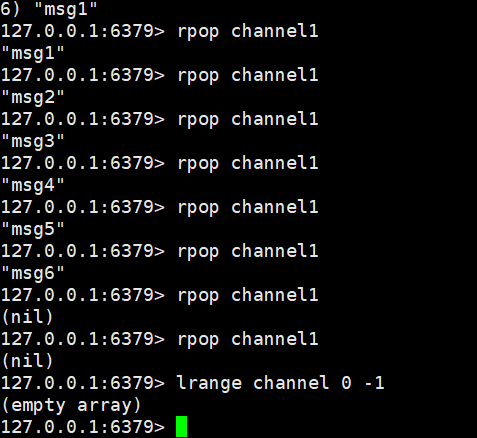
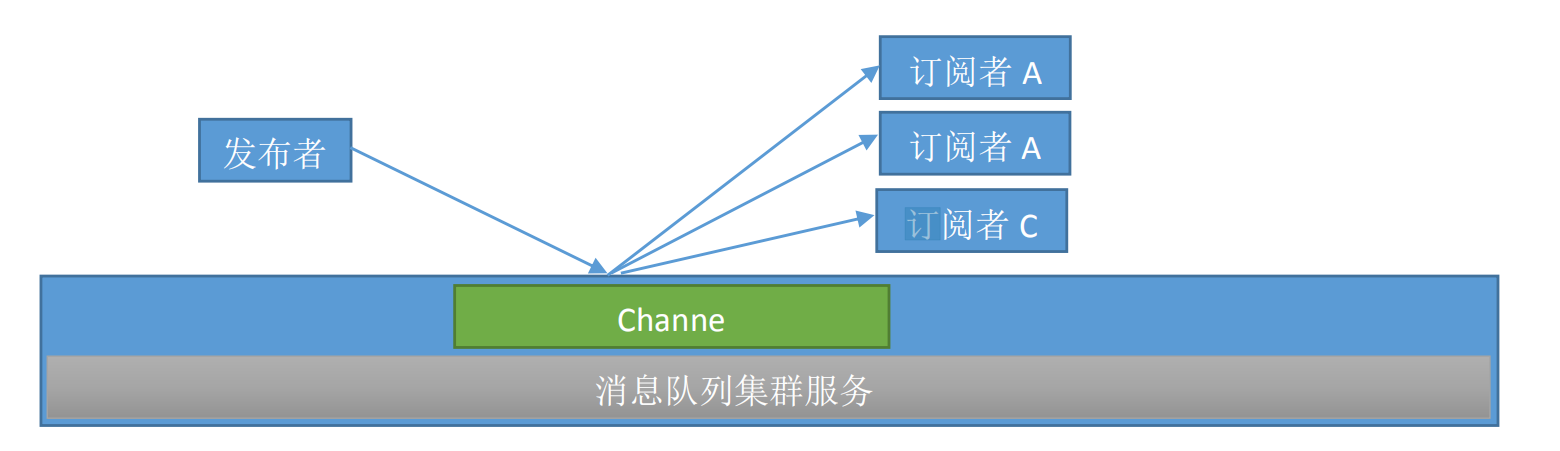
发布者订阅模式:
模式介绍:
发布者将消息发布到指定的channel 里面
凡是监听该channel 的消费者都会收到同样的一份消息
这种模式类似于收音机模式
这种模式常用在群聊天,群通知 ,群公告等场景
subscriber : 订阅者
publisher: 发布者
channel : 频道
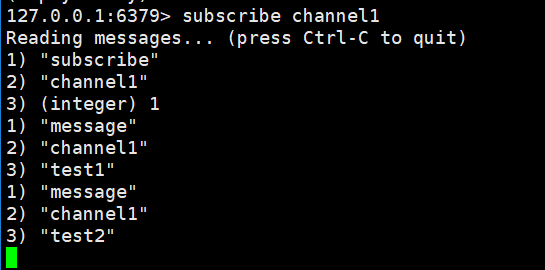
订阅者监听频道案例:
#订阅者订阅指定的频道
# 发布者发布消息
订阅多个频道:
subscribe channel1 channel2
订阅所有频道:
psubscribe *
订阅匹配的频道
psubscribe chann* # 匹配订阅多个频道