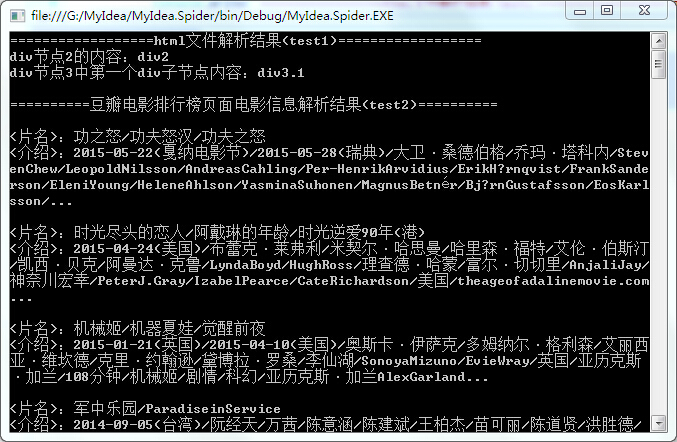
主要介绍基于XPATH的文本分析方式的实现,代码如下:
using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.Threading.Tasks; using HtmlAgilityPack; namespace MyIdea.Spider { class Program { static void Main(string[] args) { GetDataFromFile(); GetDataFromUrl(); Console.ReadKey(); } static void GetDataFromFile() { HtmlDocument doc = new HtmlDocument(); doc.Load(AppDomain.CurrentDomain.BaseDirectory.Replace(@"binDebug","") + "/test.html"); Console.Write("==================html文件解析结果(test1)================== "); Console.Write(string.Format("div节点2的内容:{0} ", doc.DocumentNode.SelectNodes("/html/body/div/div")[1].InnerText)); Console.Write(string.Format("div节点3中第一个div子节点内容:{0} ", doc.DocumentNode.SelectNodes("/html/body/div/div/div")[0].InnerText)); } static void GetDataFromUrl() { string url = "http://movie.douban.com/chart"; string movieXpath = "/html/body/div[3]/div[1]/div/div[1]/div/div/table/tr/td[2]/div"; HtmlWeb request = new HtmlWeb(); HtmlDocument doc = request.Load(url); HtmlNodeCollection movieItems = doc.DocumentNode.SelectNodes(movieXpath); Console.Write("==========豆瓣电影排行榜页面电影信息解析结果(test2)========== "); foreach (HtmlNode item in movieItems) { string title = item.Descendants("a").First().InnerText.Replace(" ","").Replace(" ",""); string introduce = item.Descendants("p").First().InnerText.Replace(" ", "").Replace(" ", ""); Console.WriteLine(" <片名>:"+title); Console.WriteLine("<介绍>:" + introduce); } } } }
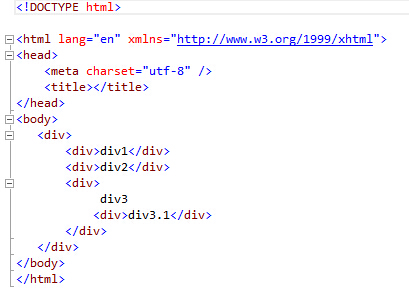
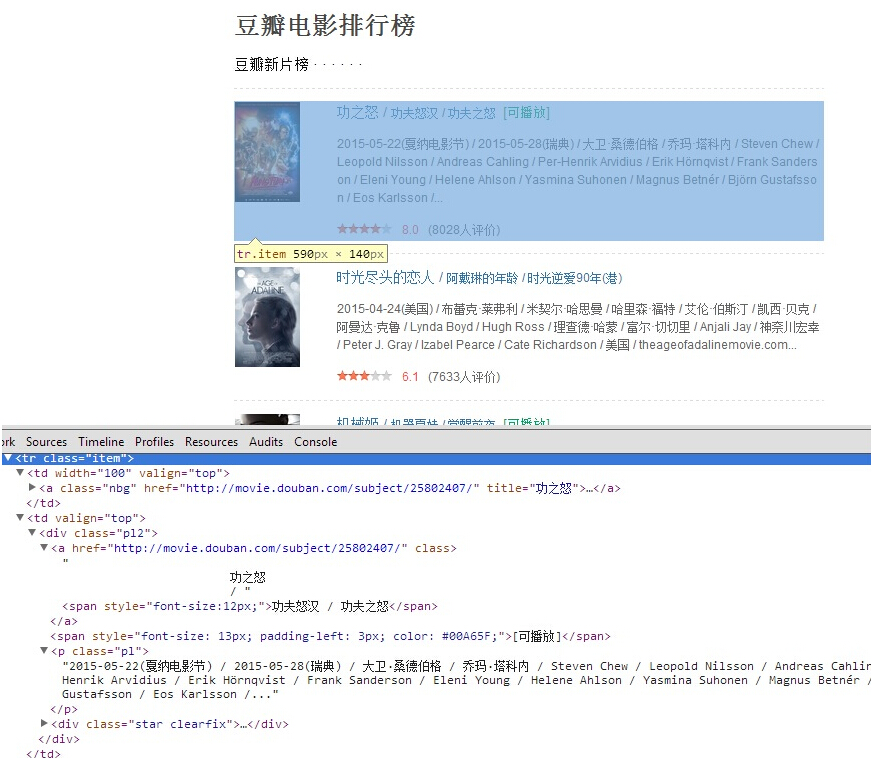
解析结果