协程
昨日内容回顾
GIL
1.GIL
全局解释器锁 只在Cpython解释器中
由于Cpython内存管理不是线程安全的!
2.内存管理中的垃圾回收机制分为三种:
2.1.引用计数
2.2.标记清除
2.3.分代回收
3.线程是直接能够被cpu执行吗?
线程就是我们写的代码,只是我们能识别,也就是高级语言中的解释型,计算机识别不了,所以线程并不是直接被cpu直接执行,而是通过解释器, 所以必须先抢解释器才能被cpu执行
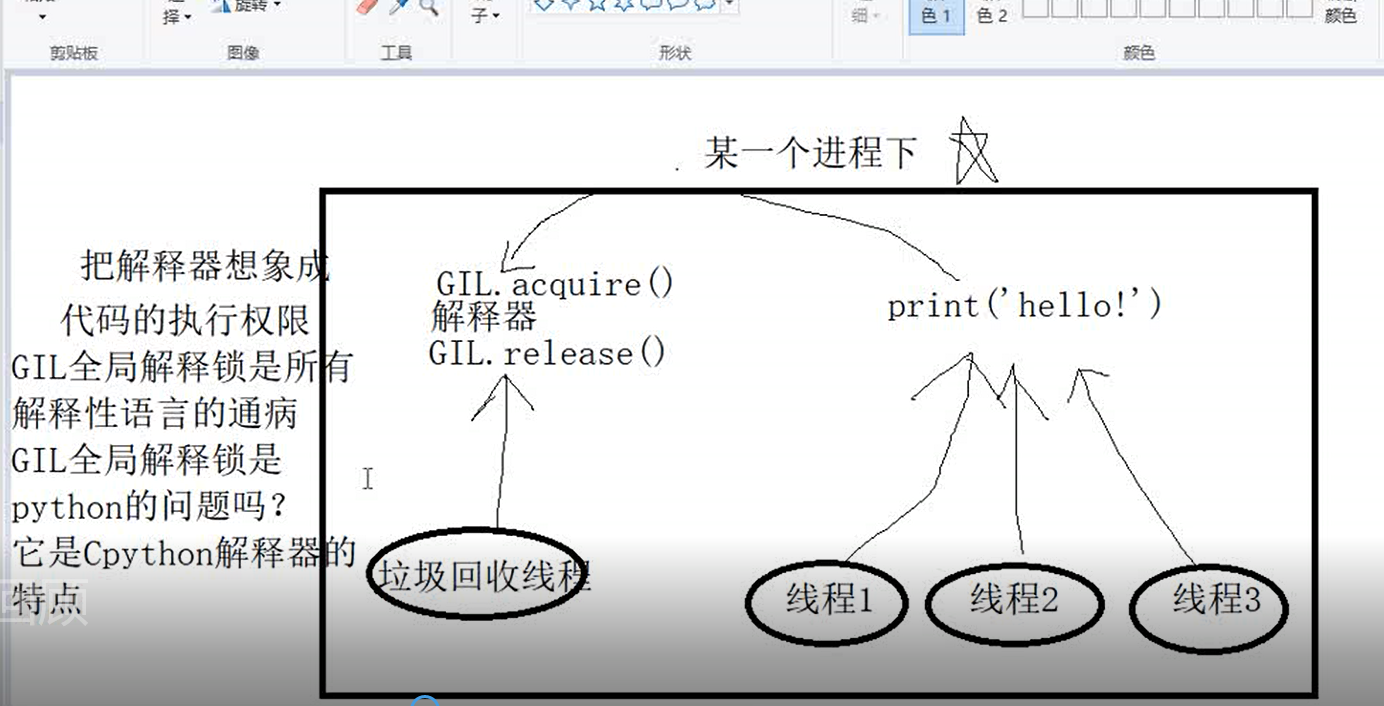
解释器是被GIL锁住,同一个进程下的多个线程在同一时刻只能有一个线程被执行,也就是说同一个进程下的多个线程要想运行就必须先抢到解释器,抢到解释器的线程中如果存在互斥锁阻塞(acquire,release)也会先停下来等,等的时间是cpu自己已经存在好的,如果线程中存在(input,accept等其他io阻塞,是不会等,直接切换到其他线程的运行。
GIL锁住解释器,不管是单核还是多核下都不能实现并行,但是可以实现并发。微观下是串行,宏观下是并发。线程在双核下也可以实现并行。
死锁与递归锁
死锁与递归锁
即便你记住了没acquire一次就release一次的操作,也会产生死锁现象
递归锁:可以连续的acquire(),每acquire()一次计数加一
线程q
线程q
消息队列
普通的q 队列 先进先出
LIFO 堆栈 先进后出
优先级q q.put((数字,数据)) 数字越小优先级越高
socket服务端实现并发
(无论是开线程还是开进程其实都消耗资源,开线程消耗的资源比开进程的小)
服务端
import socket
from threading import Thread
"""
服务端:
1.固定的ip和port
2.24小时不间断提供服务
3.支持高并发
"""
server = socket.socket()
server.bind(('127.0.0.1',8080))
server.listen(5) # 半连接池
def communicate(conn):
while True:
try:
data = conn.recv(1024) # 阻塞
if len(data) == 0:break
print(data)
conn.send(data.upper())
except ConnectionResetError:
break
conn.close()
while True:
conn,addr = server.accept() # 阻塞
print(addr)
t = Thread(target=communicate, args=(conn,))
t.start()
客户端
import socket
client = socket.socket()
client.connect(('127.0.0.1',8080))
while True:
info = input('>>>:').encode('utf-8')
if len(info) == 0:continue
client.send(info)
data = client.recv(1024)
print(data)
进程池线程池
池:
为了减缓计算机硬件的压力,避免计算机硬件设备崩溃
虽然减轻了计算机硬件的压力,但是一定程度上降低了持续的效率
进程池线程池:
线程不可能无限制的开下去,总要消耗和占用资源
为了限制开设的进程数和线程数,从而保证计算机硬件的安全
'''
- concurrent.futures模块导入
- 线程池创建(线程数=cpu核数*5左右)
- submit提交任务(提交任务的两种方式)
- 异步提交的submit返回值对象
- shutdown关闭池并等待所有任务运行结束
- 对象获取任务返回值
- 进程池的使用,验证进程池在创建的时候里面固定有指定的进程数
- 异步提交回调函数的使用
'''
from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutor
import time
pool = ThreadPoolExecutor(55)
def task(n):
print(n)
time.sleep(2)
return n**2
for i in range(20):
future = pool.submit(task, 1) #异步 submit()是函数直接就运行,返回一个对象
print(future.result()) #异步提交任务的结果,这也是阻塞,在原定等着你给我结果,
#以上两句说明,本来submit是异步,提交完任务之后就走人,不需要等待拿到返回值,而
# future.result()是要取结果,阻塞,把submit硬生生的由异步变成同步
print('主')
# 以上代码在异步中得到结果的方式非常不合理,请看以下代码
from concurrent.futures import ThreadPoolExecutor
import time
pool = ThreadPoolExecutor(5)
def task(n):
print(n)
time.sleep(2)
return n**2
t_list = []
for i in range(20):
future = pool.submit(task, i)
t_list.append(future)
for p in t_list:
print('>>', p.result())
print('主')
#等待所有的线程执行完毕之后,才获取值(join方法,event方法,shutdown)
from concurrent.futures import ThreadPoolExecutor
import time
pool = ThreadPoolExecutor(5)
def task(n):
print(n)
time.sleep(2)
return n**2
t_list = []
for i in range(20):
future = pool.submit(task, i)
t_list.append(future)
pool.shutdown()# 关闭池子并且等待池子中所有的任务运行完毕
for p in t_list:
print('>>', p.result())
print('主')
# 以上方法太麻烦
from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutor
import time
import os
# 最终答案
# 不知道参数的情况,默认是当前计算机cpu个数乘以5,也可以指定线程个数,但是参数也不能超过cpu*5的个数,因为
pool = ProcessPoolExecutor(5) # 创建了一个池子,池子里面有20个线程
def task(n):
print(n, os.getpid())
time.sleep(2)
return n**2
def call_back(n):
print('我拿到了结果:%s' % n.result())
"""
提交任务的方式
同步:提交任务之后,原地等待任务的返回结果,再继续执行下一步代码
异步:提交任务之后,不等待任务的返回结果(通过回调函数拿到返回结果并处理),直接执行下一步操作
"""
# 回调函数:异步提交之后一旦任务有返回结果,自动交给另外一个去执行
if __name__ == '__main__':
# pool.submit(task,1)
t_list = []
for i in range(20):
future = pool.submit(task, i).add_done_callback(call_back) # 异步提交任务
t_list.append(future)
# pool.shutdown() # 关闭池子并且等待池子中所有的任务运行完毕
# for p in t_list:
# print('>>>:',p.result())
print('主')
协程理论
- 进程:资源单位
- 线程:执行单位
- 协程:单线程下实现并发(能够在多个任务之间切换和保存状态来节省IO),这里注意区分操作系统的切换+保存状态是针对多个线程而言,而我们现在是想在单个线程下自己手动实现操作系统的切换+保存状态的功能
注意协程这个概念完全是程序员自己想出来的东西,它对于操作系统来说根本不存在。操作系统只知道进程和线程。并且需要注意的是并不是单个线程下实现切换+保存状态就能提升效率,因为你可能是没有遇到io也切,那反而会降低效率
再回过头来想上面的socket服务端实现并发的例子,单个线程服务端在建立连接的时候无法去干通信的活,在干通信的时候也无法去干连接的活。这两者肯定都会有IO,如果能够实现通信io了我就去干建连接,建连接io了我就去干通信,那其实我们就可以实现单线程下实现并发
将单个线程的效率提升到最高,多进程下开多线程,多线程下用协程>>> 实现高并发!!!
'''
协程:
进程:资源单位(车间)
线程:最小执行单位(流水线)
协程:单线程下实现并发
并发:看上去像同时执行就可以称之为并发
多道技术:
空间上的复用
时间上的复用
核心:切换+保存状态
协程:完全是我们高技术的人自己编出来的名词
通过代码层面自己监测io自己实现切换,让操作系统误认为
你这个线程没有io
切换+保存状态就一定能够提升你程序的效率吗?
不一定
当你的任务是计算密集型,反而会降低效率
如果你的任务是IO密集型,会提升效率
yield
协程:单线程下实现并发
如果你能够自己通过代码层面监测你自己的io行为
并且通过代码实现切换+保存状态
单线程实现高并发
开多进程
多个进程下面再开多线程
多个线程下开协程
实现高并发
'''
三者都是实现并发的手段
# yield能够实现保存上次运行状态,但是无法识别遇到io才切换
#串行执行
import time
def func1():
for i in range(10000000):
i+1
def func2():
for i in range(10000000):
i+1
start = time.time()
func1()
func2()
stop = time.time()
print(stop - start)
#基于yield并发执行
import time
def func1():
while True:
10000000+1
yield
def func2():
g=func1()
for i in range(10000000):
# time.sleep(100) # 模拟IO,yield并不会捕捉到并自动切换
i+1
next(g)
start=time.time()
func2()
stop=time.time()
print(stop-start)
yield并不能帮我们自动捕获到io行为才切换,那什么模块可以呢?
3.gevent模块
一个spawn就是一个帮你管理任务的对象
gevent模块不能识别它本身以外的所有的IO行为,但是它内部封装了一个模块,能够帮助我们识别所有的IO行为
from gevent import monkey;monkey.patch_all() # 检测所有的IO行为
from gevent import spawn,joinall # joinall列表里面放多个对象,实现join效果
import time
def play(name):
print('%s play 1' %name)
time.sleep(5)
print('%s play 2' %name)
def eat(name):
print('%s eat 1' %name)
time.sleep(3)
print('%s eat 2' %name)
start=time.time()
g1=spawn(play,'刘清正')
g2=spawn(eat,'刘清正')
# g1.join()
# g2.join()
joinall([g1,g2])
print('主',time.time()-start) # 单线程下实现并发,提升效率
4.协程实现服务端客户端通信
链接和通信都是io密集型操作,我们只需要在这两者之间来回切换其实就能实现并发的效果
服务端监测链接和通信任务,客户端起多线程同时链接服务端
# 服务端
from gevent import monkey;monkey.patch_all()
from socket import *
from gevent import spawn
def communicate(conn):
while True:
try:
data = conn.recv(1024)
if len(data) == 0: break
conn.send(data.upper())
except ConnectionResetError:
break
conn.close()
def server(ip, port, backlog=5):
server = socket(AF_INET, SOCK_STREAM)
server.bind((ip, port))
server.listen(backlog)
while True: # 链接循环
conn, client_addr = server.accept()
print(client_addr)
# 通信
spawn(comunicate,conn)
if __name__ == '__main__':
g1=spawn(server,'127.0.0.1',8080)
g1.join()
# 客户端
from threading import Thread, current_thread
from socket import *
def client():
client = socket(AF_INET, SOCK_STREAM)
client.connect(('127.0.0.1', 8080))
n = 0
while True:
msg = '%s say hello %s' % (current_thread().name, n)
n += 1
client.send(msg.encode('utf-8'))
data = client.recv(1024)
print(data.decode('utf-8'))
if __name__ == '__main__':
for i in range(500):
t = Thread(target=client)
t.start()
# 原本服务端需要开启500个线程才能跟500个客户端通信,现在只需要一个线程就可以扛住500客户端
# 进程下面开多个线程,线程下面再开多个协程,最大化提升软件运行效率
IO模型
-
阻塞IO
-
非阻塞IO(服务端通信针对accept用s.setblocking(False)加异常捕获,cpu占用率过高)
-
IO多路复用
在只检测一个套接字的情况下,他的效率连阻塞IO都比不上。因为select这个中间人增加了环节。
但是在检测多个套接字的情况下,就能省去wait for data过程
-
异步IO