转作者:SMTNinja
来源:知乎
来源:知乎
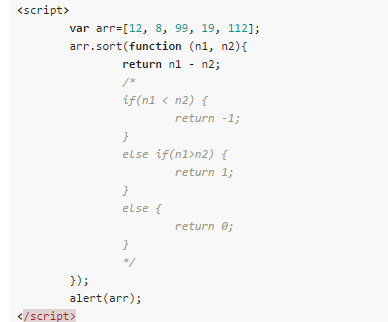
下面这个排序函数展示了任何基于比较的排序算法 (comparison-based sorting algorithm) 都有的一段代码:
也就是说你在用这个排序算法的时候, 除了需要传入一列东西以外, 还需要传入一个比较函数. 为什么呢? 注意这个排序函数在利用比较函数干什么: 函数执行到这里, 它需要判断两个东西的大小. 整数/浮点数的大小比较倒是好说, 但是任意类型的两个对象怎么比较大小, 就需要程序员自定义了. 我们来考察一个比较函数的输入输出: 输入是同一类型的两个对象; 输出是三个状态 {大, 小, 相等}, 通常用 {大于零的值, 小于零的值, 零} 来分别代表. 也就是说, 比较函数是留给其他程序员自己定义任意类型的对象间大小关系的. 一个算法接收一个比较函数, 就能把具体两个对象怎么比较这件事从算法中分离 (抽象) 出来, 丢给别人做, 自己只关系高层的实现. 排序算法并不关心它手上的元素的序关系到底是怎么定义的, 它只需要知道比较结果.
一般来说, 如果你那一列东西是普通的数 (比如整数), 那么一般来说, 你所使用的程序语言的标准库早就帮你实现了几个用于数的默认比较函数, 不用你手传. 所以如果你一直只在代码中排一些整数或者浮点数, 而且总是直接用默认升降序来排, 那就没可能遇到要提供比较函数的情况.
你的代码定义了下面这个比较函数:
这样, 你在调用排序函数的时候
返回值为 [4, 3, 2, 1].
如果定义
再执行
其返回值就是 [1, 2, 3, 4]. 因为此时排序函数认为 1 比 2 "大".
为什么这么多数你只需要写两个?
答案: 你提供的比较函数会在排序函数中被不停地调用. 每当排序算法遇到需要知道两个数哪个大哪个小, 就会调用你的比较函数来看结果大小 (即执行答案一开始我展示出来的那段代码).
从大到小排序(一列东西, 一个比较函数) {
...
比较结果 = 比较函数(东西1, 东西2)
讨论 比较结果 {
大于零 说明 东西1 比 东西2 大
小于零 说明 东西1 比 东西2 小
等于零 说明 东西1 和 东西2 相等
}
...
}
一般来说, 如果你那一列东西是普通的数 (比如整数), 那么一般来说, 你所使用的程序语言的标准库早就帮你实现了几个用于数的默认比较函数, 不用你手传. 所以如果你一直只在代码中排一些整数或者浮点数, 而且总是直接用默认升降序来排, 那就没可能遇到要提供比较函数的情况.
你的代码定义了下面这个比较函数:
数值比较(数1, 数2) { 返回 数1 - 数2 }
从大到小排序([4, 2, 1, 3], 数值比较)
如果定义
数值逆比较(数1, 数2) { 返回 数2 - 数1 }
从大到小排序([4, 2, 1, 3], 数值逆比较)
为什么这么多数你只需要写两个?
答案: 你提供的比较函数会在排序函数中被不停地调用. 每当排序算法遇到需要知道两个数哪个大哪个小, 就会调用你的比较函数来看结果大小 (即执行答案一开始我展示出来的那段代码).