一、LRU产生的原因
1.首先,你要知道什么是缺页中断
百度:
缺页中断就是要访问的页不在主存,需要操作系统将其调入主存后再进行访问。在这个时候,被内存映射的文件实际上成了一个分页交换文件。
简书:
缺页本身是一种中断,与一般的中断一样,需要经过4个处理步骤:
- 保护CPU现场
- 分析中断原因
- 转入缺页中断处理程序进行处理
- 恢复CPU现场,继续执行
但是缺页中断时由于所要访问的页面不存在与内存时,有硬件所产生的一种特殊的中断,因此,与一般的中断存在区别:
- 在指令执行期间产生和处理缺页中断信号
- 一条指令在执行期间,可能产生多次缺页中断
- 缺页中断返回时,执行产生中断的那一条指令,而一般的中断返回时,执行下一条指令
程序执行需要许多的资源,当申请使用电脑的内存的时候,会分配一定的内存额度(单位:页)给程序使用,如果这些页面是空的,就需要为这个页写入数据,这就产生一次中断,但由于多个程序的同时运行,可能之前申请的页由于某种原因,比如该页在内存中已被某程序使用,导致内容可能发生变化,这就需要重新申请分配(这个页数据发生变化导致重新写入,引起的原因很啰嗦,不好描述)。
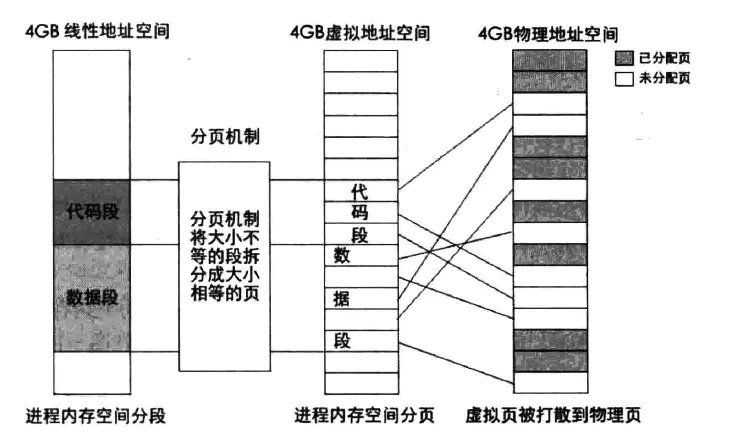
此时需要重新将这一页加载进内存(重新分配),而分配在内存哪里,如何分配能保证某些常用页(已缓存数据)不被踢出内存,这就产生了算法,LRU就是其中一种。
页面分配如图:
二、LRU使用场景
Redis,目的在于快速命中程序本身需要的页,加快程序执行流程,减少因为中断次数引起的等待写入时间。(其实就是说,常用的数据缓存所在的页,尽量不做清除处理,下次访问直接使用就对了,减少写入内存的时间,减少中断次数引起的各种等待时间)
三、LRU算法介绍
在固定的分配页数下(A,B,C,D,E,F),将每个页的使用次数做一个记录,认为使用次数多的页(起个别名A),默认最近也有可能被使用,使用次数少的页(起个别名B),默认最近不可能被使用,别的页使用次数一样.
那么,产生产生新序列(A,C,D,E,F,B),当需要新的数据(起个别名G)写入,就把G替换掉B,。
此时,新序列(A,C,D,E,F,G)
然后疯狂使用G,导致G的使用记录狂升,直至超过A,序列变化为(G,A,C,D,E,F)
然后不断乱序循环以上,这就是LRU的概念。
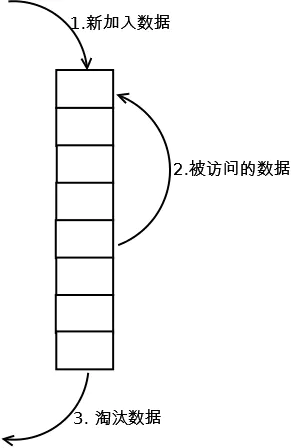
给个数组逻辑图片:
四、LRU优缺点
1.命中率,当存在热点数据时,LRU的效率很好,但偶发性的,周期性的批量操作会导致LRU命中率急剧下降,缓存污染情况比较严重
2,实现相对简单(数组,链表都可以)
3,命中时需要遍历链表,找到命中的数据块索引,然后需要将数据移到头部(每次命中都会导致使用次数的值引起变化,而页面的淘汰基于该数值大小)
五、如何实现:
1.用一个数组来存储数据,给每一个数据项标记一个访问时间戳,每次插入新数据项的时候,先把数组中存在的数据项的时间戳自增,并将新数据项的时间戳置为0并插入到数组中。每次访问数组中的数据项的时候,将被访问的数据项的时间戳置为0。当数组空间已满时,将时间戳最大的数据项淘汰。
2.利用一个链表来实现,每次新插入数据的时候将新数据插到链表的头部;每次缓存命中(即数据被访问),则将数据移到链表头部;那么当链表满的时候,就将链表尾部的数据丢弃。
3.利用链表和hashmap。当需要插入新的数据项的时候,如果新数据项在链表中存在(一般称为命中),则把该节点移到链表头部,如果不存在,则新建一个节点,放到链表头部,若缓存满了,则把链表最后一个节点删除即可。在访问数据的时候,如果数据项在链表中存在,则把该节点移到链表头部,否则返回-1。这样一来在链表尾部的节点就是最近最久未访问的数据项。
对于第一种方法,需要不停地维护数据项的访问时间戳,另外,在插入数据、删除数据以及访问数据时,时间复杂度都是O(n)。对于第二种方法,链表在定位数据的时候时间复杂度为O(n)。所以在一般使用第三种方式来是实现LRU算法。
ps:个人能力有限,只做个人学习参考使用,如有错误请指教,盼共同进步