Dosovitskiy, Alexey, and Vladlen Koltun. "Learning to act by predicting the future." arXiv preprint arXiv:1611.01779 (2016).
vizdoom比赛track2的冠军。
要点:
1.使用了监督学习,而不是增强学习。
2.克服sparse reward的问题。
3.在test时不同目标的泛化能力强。更加长远的作用就是减少了人为reward的制定。
实验分析:
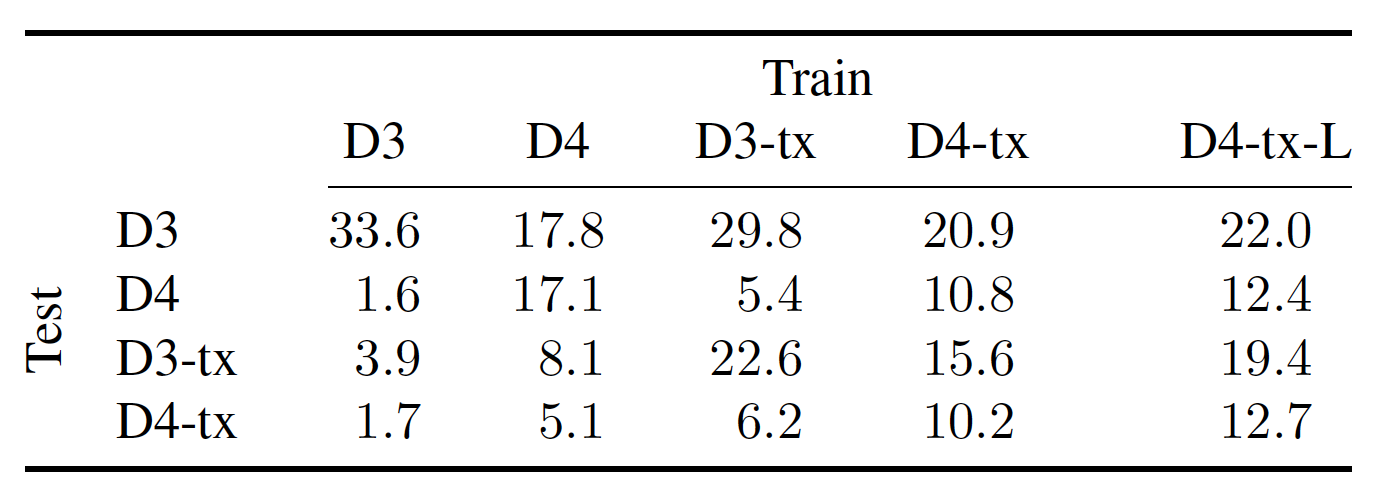
1.通过下面这个在D4上训练,D3-tx和D4-tx上测试的结果可以看出,其在不同地图上的泛化能力弱。要想在不同地图上提高泛化能力,一个是要数据量大,二个是要加强perception部分的处理。
未来展望:
1.把RL统一到supervised learning框架下。