有的时候需要对数据库的某个字段要求不能重复,所以要设置这个字段的唯一性
1. 把这个字段设置成主键
把phonumber设置为主键
CREATE TABLE `userinformation` ( `username` varchar(50) DEFAULT NULL, `phonenumber` varchar(30) NOT NULL, `classify` varchar(20) DEFAULT NULL, `start_date` varchar(50) DEFAULT NULL, `end_date` datetime DEFAULT CURRENT_TIMESTAMP, PRIMARY KEY (`phonumber`) )
2. 要是不想设置为主键,那可以为它增加UNIQUE属性,在创建表的时候设置,要是设置某个字段的唯一性,那么这个字段也要设置NOT NULL,因为唯一索引不允许有两个NULL及以上。
设置phonumber字段的唯一性
CREATE TABLE `userinformation` ( `id` int(11) NOT NULL AUTO_INCREMENT, `username` varchar(50) CHARACTER SET utf8mb4 DEFAULT NULL, `phonenumber` varchar(30) NOT NULL UNIQUE `classify` varchar(20) DEFAULT NULL, `start_date` varchar(50) DEFAULT NULL, `end_date` datetime DEFAULT CURRENT_TIMESTAMP, PRIMARY KEY (`id`) )
表已经创建了,想要后期加上
ALTER TABLE `userinformation` ADD unique(`字段名称`)
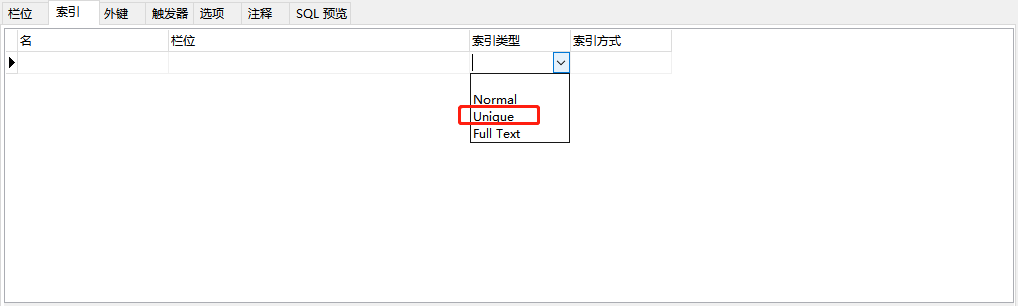
3.我们还可以在navicat里设置
选中表后,点击设计表:

点击索引那一栏,选择索引类型。名字自己随意取。
注意:
1. 若是字段已存在重复的数据,那么在navicat里更改或者sql语句更改都会报错的,那就需要先删除重复的数据。navicat的删除就不说了,我们说一下sql语句怎么删除,假设我的表只有id和phonunumber这俩字段。
需要先创建一个临时表new_table,临时表的数据可以对原表userinformation进行分组查询获取,新生成的new_table中数据没有重复的,也没有id字段。
CREATE TABLE new_table SELECT phonenumber FROM userinformation GROUP BY phonenumber
拷贝原表的表结构为新表userinformation1,把new_table表的数据插入到userinformation1,然后删原表,把新表改成原表的名字
DROP TABLE userinformation
INSERT INTO userinformation1 SELECT null,phonenumber FROM new_table
ALTER TABLE uaerinformation1 rename to userinformation
2. 我们对字段设置了唯一性后,插入的数据若是重复就会报错,可以在INSERT的时候设置成数据重复就跳过。通过INSERT IGNORE 来跳过:
INSERT IGNORE INTO userinformation (phonumber) VALUES(111111)