TCP三次握手
三次握手的过程:
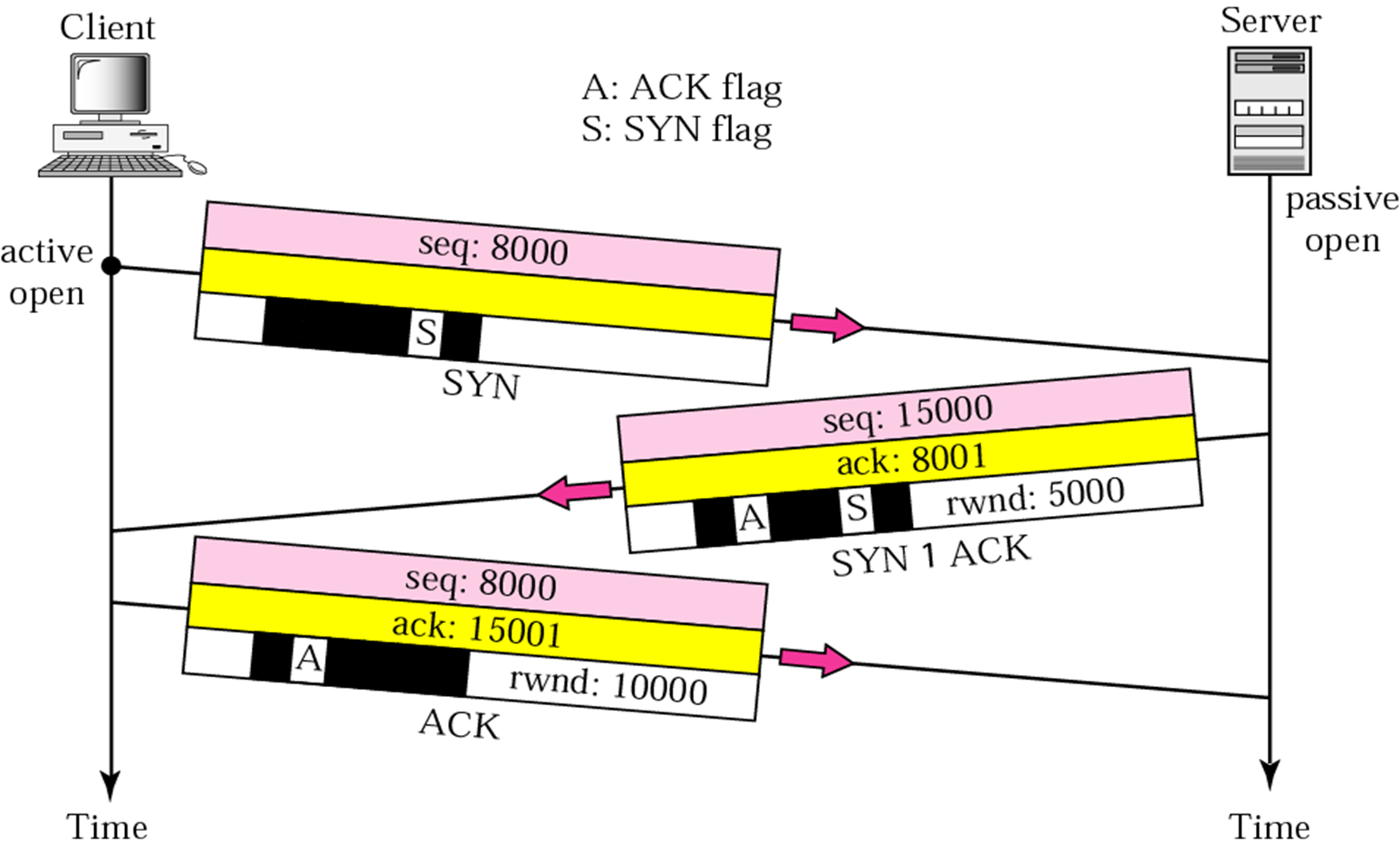
1. 第一次握手:建立连接。客户端发送连接请求报文段,并将SYN位置为1,seqence number为8000,然后,客户端进入SYN_SEND状态,等待服务器的确认。
2. 第二次握手:服务器收到SYN报文段。服务器收到客户端的SYN报文段,需要对这个SYN报文段进行确认,设置acknowledg number为8001(对序号为8000的报文段进行确认,期望接受序号为8001的报文段);同时,自己还要发送SYN请求信息,将SYN位置为1,sequence number为15000;服务器端将上述所有信息放到一个报文段(即SYN+ACK报文段)中,一并发送给客户端,此时服务器进入SYN_RECV状态;
3. 第三次握手:客户端收到服务器的SYN+ACK报文段。然后将acknowledgment number设置为15001,向服务器发送ACK报文段,这个报文段发送完毕以后,客户端和服务器端都进入ESTABLISHED状态,完成TCP三次握手,客户端和服务器端就可以开始传送数据。
为什么需要三次握手呢?
408考研指定教材谢希仁著《计算机网络》中有说:“三次握手”的目的是为了防止已失效的连接请求报文段突然又传送到了服务端,因而产生错误。
“已失效的连接请求报文段”的产生在这样一种情况下:client发出的第一个连接请求报文段并没有丢失,而是在某个网络结点长时间的滞留了,以致延误到连接释放以后的某个时间才到达server。本来这是一个早已失效的报文段。但server收到此失效的连接请求报文段后,就误认为是client再次发出的一个新的连接请求。于是就向client发出确认报文段,同意建立连接。假设不采用“三次握手”,那么只要server发出确认,新的连接就建立了。由于现在client并没有发出建立连接的请求,因此不会理睬server的确认,也不会向server发送数据。但server却以为新的运输连接已经建立,并一直等待client发来数据。这样,server的很多资源就白白浪费掉了。采用“三次握手”的办法可以防止上述现象发生。例如刚才那种情况,client不会向server的确认发出确认。server由于收不到确认,就知道client并没有要求建立连接。就是为了防止服务端的一直等待而浪费资源。
TCP三次握手的源代码分析:
三次握手发生在socket编程的哪一步呢?
对用户编程来说,TCP三次握手发生在客户端connect和服务器端accept时,根据上一次实验我们知道:connect函数对应的内核处理函数为__sys_connect,accept函数对应__sys_accept4内核处理函数。
我们将断点设置在__sys_connect和__sys_accept4,阅读这两个内核函数的源码:
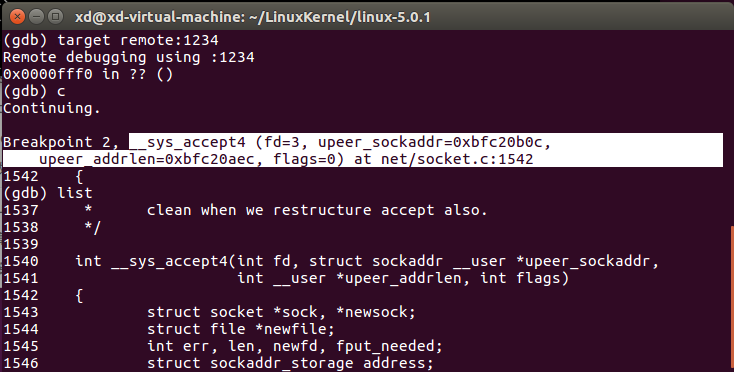
//https://github.com/mengning/linux/blob/1c163f4c7b3f621efff9b28a47abb36f7378d783/net/socket.c#L1540
int __sys_accept4(int fd, struct sockaddr __user *upeer_sockaddr, int __user *upeer_addrlen, int flags) { struct socket *sock, *newsock; struct file *newfile; int err, len, newfd, fput_needed; struct sockaddr_storage address;
... //省略了无关代码 err = sock->ops->accept(sock, newsock, sock->file->f_flags, false); ... }
//https://github.com/mengning/linux/blob/1c163f4c7b3f621efff9b28a47abb36f7378d783/net/socket.c#L1645
int __sys_connect(int fd, struct sockaddr __user *uservaddr, int addrlen) { struct socket *sock; struct sockaddr_storage address; int err, fput_needed; ...//省略了无关代码 err = sock->ops->connect(sock, (struct sockaddr *)&address, addrlen, sock->file->f_flags); ... }
可以看到这两个内核处理函数调用了sock->ops->accept和sock->ops->connect这两个函数指针指向的函数。那这两个指针到底指向哪两个函数呢?这一步是在TCP协议的初始化过程中绑定的,我们在linux/net/ipv4/tcp_ipv4.c中找到如下定义:
//https://github.com/mengning/linux/blob/ee5e001196d1345b8fee25925ff5f1d67936081e/net/ipv4/tcp_ipv4.c#L2536 struct proto tcp_prot = { .name = "TCP", .owner = THIS_MODULE, .close = tcp_close, .pre_connect = tcp_v4_pre_connect, .connect = tcp_v4_connect, .disconnect = tcp_disconnect, .accept = inet_csk_accept, .ioctl = tcp_ioctl, .init = tcp_v4_init_sock, .destroy = tcp_v4_destroy_sock, .shutdown = tcp_shutdown, .setsockopt = tcp_setsockopt, .getsockopt = tcp_getsockopt, .keepalive = tcp_set_keepalive, .recvmsg = tcp_recvmsg, .sendmsg = tcp_sendmsg, ... };
最终发现这两个函数指针对应着tcp_v4_connect函数和inet_csk_accept函数。
我们将断点打在tcp_v4_connect函数和inet_csk_accept函数处来进一步验证三次握手的过程:

1. tcp_v4_connect函数:
//https://github.com/mengning/linux/blob/ee5e001196d1345b8fee25925ff5f1d67936081e/net/ipv4/tcp_ipv4.c#L202
int tcp_v4_connect(struct sock *sk, struct sockaddr *uaddr, int addr_len) { ... rt = ip_route_connect(fl4, nexthop, inet->inet_saddr, RT_CONN_FLAGS(sk), sk->sk_bound_dev_if, IPPROTO_TCP, orig_sport, orig_dport, sk); .../* Socket identity is still unknown (sport may be zero). * However we set state to SYN-SENT and not releasing socket * lock select source port, enter ourselves into the hash tables and * complete initialization after this. */
//更新状态 tcp_set_state(sk, TCP_SYN_SENT); ... //为套接字绑定一个新的端口 rt = ip_route_newports(fl4, rt, orig_sport, orig_dport, inet->inet_sport, inet->inet_dport, sk); ... //构造SYN并发送出去 err = tcp_connect(sk); ... }

tcp_v4_connect函数用于客户端,其主要作用就是发起一个TCP连接,它调用了IP层提供的一些服务,如ip_route_connect等,生成一个包含SYN标志位和序号的连接请求TCP报文段,并发送给服务器,这一步对应三次握手中的第一步。其中tcp_connect函数具体负责构造一个携带SYN标志位的TCP头并发送出去,同时还设置了计时器超时重发。
2. inet_csk_accept函数
//https://github.com/mengning/linux/blob/ee5e001196d1345b8fee25925ff5f1d67936081e/net/ipv4/inet_connection_sock.c#L441
struct sock *inet_csk_accept(struct sock *sk, int flags, int *err, bool kern) { struct inet_connection_sock *icsk = inet_csk(sk); struct request_sock_queue *queue = &icsk->icsk_accept_queue; struct request_sock *req; struct sock *newsk; int error; lock_sock(sk); /* We need to make sure that this socket is listening, * and that it has something pending. */ error = -EINVAL; if (sk->sk_state != TCP_LISTEN) goto out_err; /* Find already established connection */ if (reqsk_queue_empty(queue)) { long timeo = sock_rcvtimeo(sk, flags & O_NONBLOCK); /* If this is a non blocking socket don't sleep */ error = -EAGAIN; if (!timeo) goto out_err; error = inet_csk_wait_for_connect(sk, timeo); if (error) goto out_err; } req = reqsk_queue_remove(queue, sk); newsk = req->sk; if (sk->sk_protocol == IPPROTO_TCP && tcp_rsk(req)->tfo_listener) { spin_lock_bh(&queue->fastopenq.lock); if (tcp_rsk(req)->tfo_listener) { /* We are still waiting for the final ACK from 3WHS * so can't free req now. Instead, we set req->sk to * NULL to signify that the child socket is taken * so reqsk_fastopen_remove() will free the req * when 3WHS finishes (or is aborted). */ req->sk = NULL; req = NULL; } spin_unlock_bh(&queue->fastopenq.lock); } out: release_sock(sk); if (req) reqsk_put(req); return newsk; out_err: newsk = NULL; req = NULL; *err = error; goto out; }
当request_sock_queue为非空时服务器端调用inet_csk_accept函数从请求队列中取出一个连接请求。
当request_sock_queue为空时则通过inet_csk_wait_for_connect阻塞住,等待客户端的连接。我们再来看函数inet_csk_wait_for_connect的实现:
//https://github.com/mengning/linux/blob/ee5e001196d1345b8fee25925ff5f1d67936081e/net/ipv4/inet_connection_sock.c#L393
static int inet_csk_wait_for_connect(struct sock *sk, long timeo) { struct inet_connection_sock *icsk = inet_csk(sk); DEFINE_WAIT(wait); int err; /* * True wake-one mechanism for incoming connections: only * one process gets woken up, not the 'whole herd'. * Since we do not 'race & poll' for established sockets * anymore, the common case will execute the loop only once. * * Subtle issue: "add_wait_queue_exclusive()" will be added * after any current non-exclusive waiters, and we know that * it will always _stay_ after any new non-exclusive waiters * because all non-exclusive waiters are added at the * beginning of the wait-queue. As such, it's ok to "drop" * our exclusiveness temporarily when we get woken up without * having to remove and re-insert us on the wait queue. */ for (;;) { prepare_to_wait_exclusive(sk_sleep(sk), &wait, TASK_INTERRUPTIBLE); release_sock(sk); if (reqsk_queue_empty(&icsk->icsk_accept_queue)) timeo = schedule_timeout(timeo); sched_annotate_sleep(); lock_sock(sk); err = 0; if (!reqsk_queue_empty(&icsk->icsk_accept_queue)) break; err = -EINVAL; if (sk->sk_state != TCP_LISTEN) break; err = sock_intr_errno(timeo); if (signal_pending(current)) break; err = -EAGAIN; if (!timeo) break; } finish_wait(sk_sleep(sk), &wait); return err; }
可以看到inet_csk_wait_for_connect函数就是一个无限for循环,一旦收到连接请求就跳出循环。
gdb调试:
我们将断点打在tcp_v4_connect函数和inet_csk_accept函数处,在qemu中键入replyhi命令,启动服务端
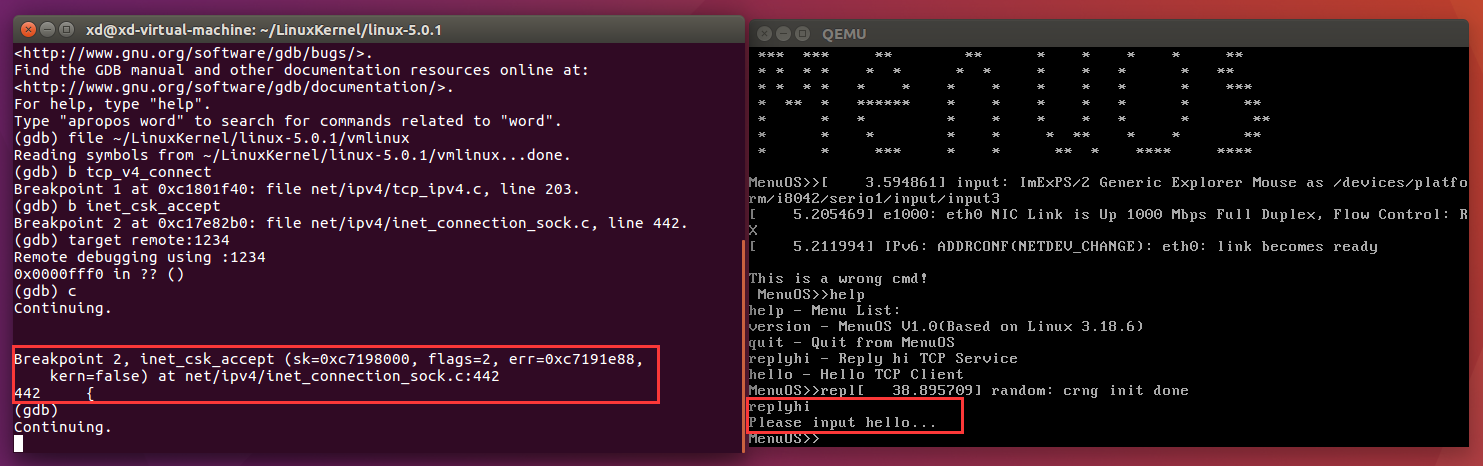
可以看到服务端执行inet_csk_accept函数,因为队列为空,所以执行inet_csk_wait_for_connect函数进入死循环,等待客户端的连接。
接下来我们在qemu中键入hello命令,启动客户端:

可以看到当我们启动客户端时,客户端执行了tcp_v4_connect函数向服务器发出连接请求,服务器收到连接请求后执行inet_csk_accept函数完成三次握手并发送数据,一次通信结束。
为了进一步验证我们将inet_csk_wait_for_connect函数也设为断点:
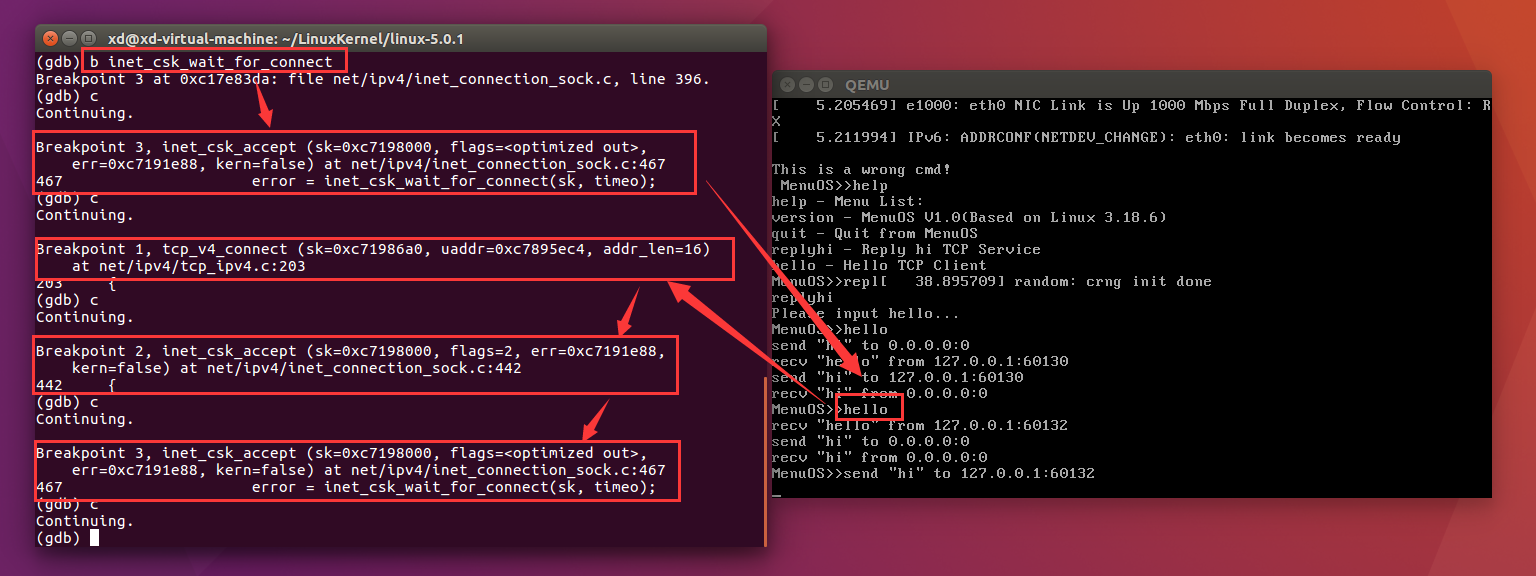
在上一次通信结束后,服务端执行inet_csk_wait_for_connect函数,进入无限循环,accept阻塞。
当我们再一次在MenuOS中输入hello时,新客户端首先发出连接请求,执行了tcp_v4_connect函数;服务端接受连接请求,执行了inet_csk_accept函数,没有进入inet_csk_accept函数里的inet_csk_wait_for_connect函数,完成一次通信。然后服务端进入到inet_csk_accept函数里的inet_csk_wait_for_connect函数,处于accept阻塞态,不断等待新的连接请求。