关于Hive
Hive简介
Hive:由 Facebook 开源用于解决海量结构化日志的数据统计工具。
Hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并
提供类 SQL 查询功能。
Hive 本质:将 HQL 转化成 MapReduce 程序
(1)Hive 处理的数据存储在 HDFS
(2)Hive 分析数据底层的实现是 MapReduce
(3)执行程序运行在 Yarn 上
创建仓库
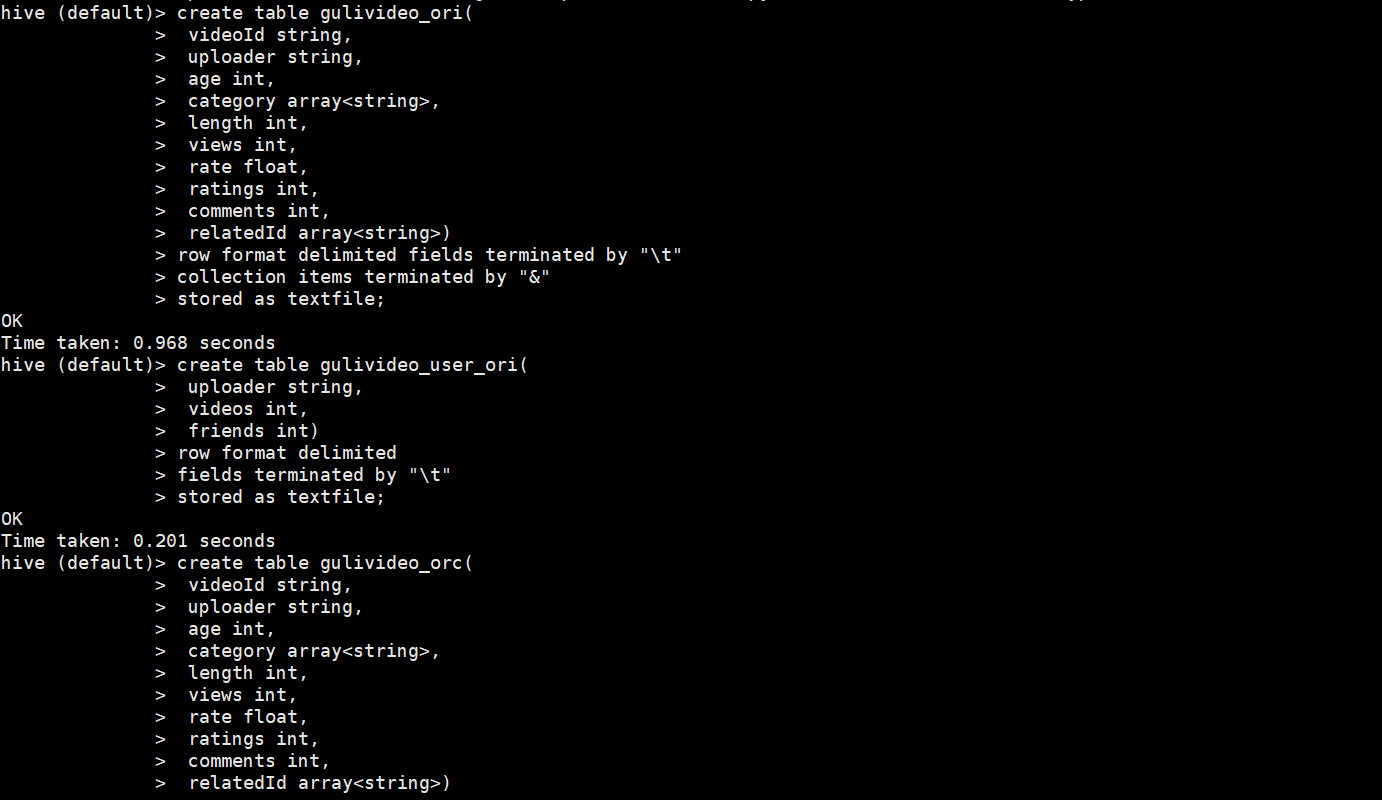
需要准备的表
创建原始数据表:gulivideo_ori,gulivideo_user_ori,
创建最终表:gulivideo_orc,gulivideo_user_orc
准备数据

上传数据
导入视频数据
load data local inpath "/opt/hive/video" into table gulivideo_ori;
导入用户数据
load data local inpath "/opt/hive/user" into table gulivideo_user_ori;
把原始表数据导入最终表
insert into table gulivideo_orc select * from gulivideo_ori;
insert into table gulivideo_user_orc select * from gulivideo_user_ori;
上传成功

分析数据
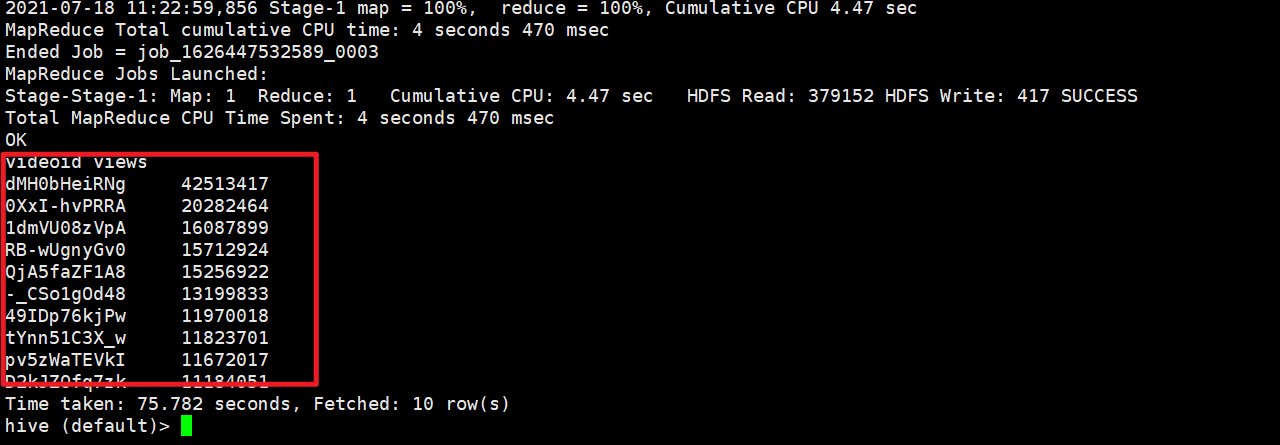
统计视频观看数 Top10
SELECT
videoId,
views
FROM
gulivideo_orc
ORDER BY
views DESC
LIMIT 10;