对于高考,你还在每天数着还有多少天吗?对于天气,你还每天去看天气预报吗?你每天需要看一些励志话语来督促自己前进吗?
python可以合上述三者为一体帮你轻松实现你的日常!
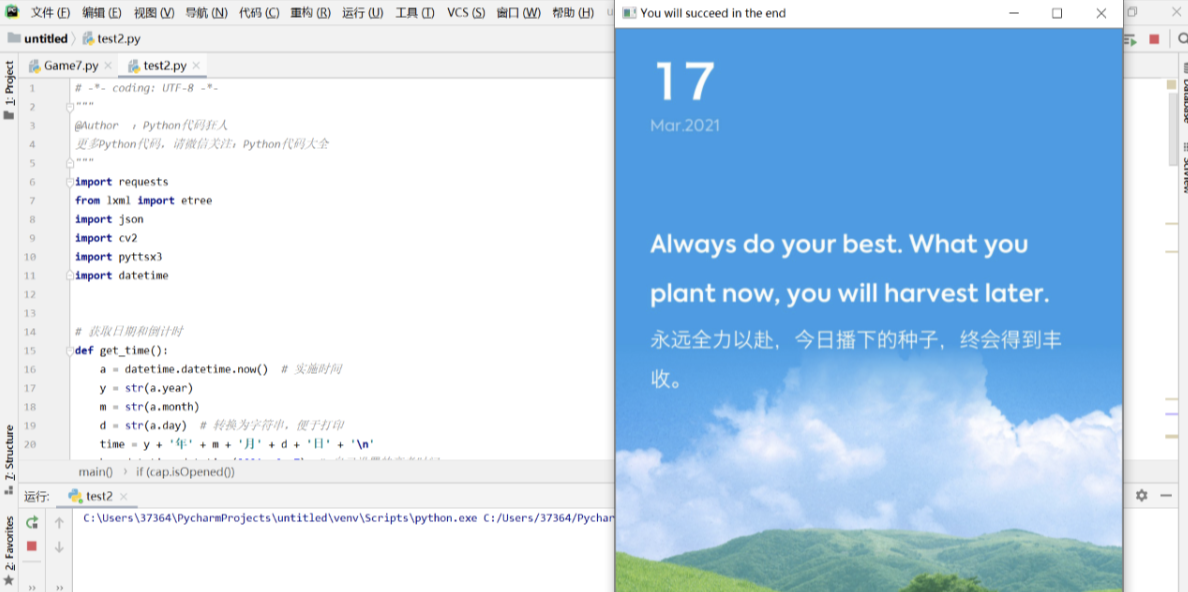
运行截图
一、需要导入的库
import requests from lxml import etree import json import cv2 import pyttsx3 import datetime
二、各模块实现 1、高考倒计时 对于倒计时,我使用了datetime库,得到实时时间,并拆分出年份、月份和日期,自己设置研究生考试时间,然后进行两者相减。函数代码如下:
# 获取日期和倒计时 def get_time(): a = datetime.datetime.now() # 实施时间 y = str(a.year) m = str(a.month) d = str(a.day) # 转换为字符串,便于打印 time = y + '年' + m + '月' + d + '日' + ' ' b = datetime.datetime(2021, 12, 25) # 自己设置的研究生考试时间 count_down = (b - a).days # 考研倒计时 return time, count_down
2、获取天气情况 以昆明为例,爬取网页的链接为:http://www.weather.com.cn/weather/101290101.shtml (如果需要切换成其它的城市,把上述链接的101290101,改为需要切换的城市的id即可。)
def get_weather(): url = 'http://www.weather.com.cn/weather/101290101.shtml' response = requests.get(url) response.encoding = 'utf-8' response = response.text # 获取页面 html = etree.HTML(response) day_weather = '天气状况:' + html.xpath('//*[@id="7d"]/ul/li[1]/p[1]/text()')[0] + ' ' # 获取天气,白天的天气 high = html.xpath('//*[@id="7d"]/ul/li[1]/p[2]/span/text()') low = html.xpath('//*[@id="7d"]/ul/li[1]/p[2]/i/text()') # 获取对应的两个温度 # 因为页面在晚上会有小变化,所以使用条件语句,来排除因变化引起的bug if high == []: day_temperature = '室外温度:' + low[0] + ' ' else: day_temperature = '室外温度:' + low[0].replace('℃', '') + '~' + high[0] + '℃ ' # 获取温度 # 获取两个风向 wind_1 = html.xpath('//*[@id="7d"]/ul/li[1]/p[3]/em/span[1]/@title') wind_2 = html.xpath('//*[@id="7d"]/ul/li[1]/p[3]/em/span[2]/@title') # 因为有时候,会出现两个风向是同一个风向的情况,所以使用条件语句排除 if wind_2 == []: wind = wind_1[0] + ' ' elif wind_1[0] == wind_2[0]: wind = wind_1[0] + ' ' else: wind = wind_1[0] + '转' + wind_2[0] + ' ' # 因为风级有时候会出现“<",语音的时候会认为是爱心符号,所以使用替换,改为文字”低于“ wind_3 = html.xpath('//*[@id="7d"]/ul/li[1]/p[3]/i/text()')[0].replace('<', '低于').replace('>', '高于') day_wind = '风向情况:' + wind + wind_3 + ' ' # 获取风向及风级 return day_weather, day_temperature, day_wind
3、营养鸡汤 为了趣味性,并且顺便练习听力,我爬取了《爱词霸》的中英文每日一句,并且将图片链接爬取,进行展示(图片不会保存,随着代码运行结束,图片也会消失)因为网上有接口,所以直接借助接口之间爬取。
def get_content(): url = 'http://open.iciba.com/dsapi/' # 网上找的API response = requests.get(url=url) json_s = json.loads(response.text) jitang = json_s.get("content") + ' ' # 每日鸡汤 translation = json_s.get("note") + ' ' # 中文翻译 image_url = json_s.get("fenxiang_img") # 图片链接 return jitang, translation, image_url
三、完整代码 在主函数中,使用pyttsx3库实现语音播报功能,使用cv2实现图片的展示功能。 代码如下:
# -*- coding: UTF-8 -*- """ @Author :Python代码狂人 更多Python代码,请微信关注:Python代码大全 """ import requests from lxml import etree import json import cv2 import pyttsx3 import datetime # 获取日期和倒计时 def get_time(): a = datetime.datetime.now() # 实施时间 y = str(a.year) m = str(a.month) d = str(a.day) # 转换为字符串,便于打印 time = y + '年' + m + '月' + d + '日' + ' ' b = datetime.datetime(2021, 6, 7) # 自己设置的高考时间 count_down = (b - a).days # 高考倒计时 return time, count_down # 获取昆明当日天气情况 def get_weather(): url = 'http://www.weather.com.cn/weather/101290101.shtml' response = requests.get(url) response.encoding = 'utf-8' response = response.text # 获取页面 html = etree.HTML(response) day_weather = '天气状况:' + html.xpath('//*[@id="7d"]/ul/li[1]/p[1]/text()')[0] + ' ' # 获取天气,白天的天气 high = html.xpath('//*[@id="7d"]/ul/li[1]/p[2]/span/text()') low = html.xpath('//*[@id="7d"]/ul/li[1]/p[2]/i/text()') # 获取对应的两个温度 # 因为页面在晚上会有小变化,所以使用条件语句,来排除因变化引起的bug if high == []: day_temperature = '室外温度:' + low[0] + ' ' else: day_temperature = '室外温度:' + low[0].replace('℃', '') + '~' + high[0] + '℃ ' # 获取温度 # 获取两个风向 wind_1 = html.xpath('//*[@id="7d"]/ul/li[1]/p[3]/em/span[1]/@title') wind_2 = html.xpath('//*[@id="7d"]/ul/li[1]/p[3]/em/span[2]/@title') # 因为有时候,会出现两个风向是同一个风向的情况,所以使用条件语句排除 if wind_2 == []: wind = wind_1[0] + ' ' elif wind_1[0] == wind_2[0]: wind = wind_1[0] + ' ' else: wind = wind_1[0] + '转' + wind_2[0] + ' ' # 因为风级有时候会出现“<",语音的时候会认为是爱心符号,所以使用替换,改为文字”低于“ wind_3 = html.xpath('//*[@id="7d"]/ul/li[1]/p[3]/i/text()')[0].replace('<', '低于').replace('>', '高于') day_wind = '风向情况:' + wind + wind_3 + ' ' # 获取风向及风级 return day_weather, day_temperature, day_wind # 获取每日鸡汤 def get_content(): url = 'http://open.iciba.com/dsapi/' # 网上找的API response = requests.get(url=url) json_s = json.loads(response.text) jitang = json_s.get("content") + ' ' # 每日鸡汤 translation = json_s.get("note") + ' ' # 中文翻译 image_url = json_s.get("fenxiang_img") # 图片链接 return jitang, translation, image_url def main(): time, count_down = get_time() day_weather, day_temperature, day_wind = get_weather() jitang, translation, image_url = get_content() count_down = '距离高考还有{}天,你准备好了吗?'.format(count_down) + ' ' a = '下面为您播报今日天气状况 ' b = '每日一句 ' time = '今天是' + time weather = day_weather + day_temperature + day_wind content = jitang + translation text = time + count_down + a + weather + b + content # 语音内容 voice = pyttsx3.init() # 初始化 # rate = voice.getProperty('rate') voice.setProperty('rate', 150) # 语速,范围在0-200之间 voice.setProperty('volume', 1.0) # 范围在0.0-1.0之间 voice.say(text) # 语音内容 voice.runAndWait() cap = cv2.VideoCapture(image_url) # 展示图片 if(cap.isOpened()): ret, img = cap.read() my_image = cv2.resize(img, dsize=None, fx=0.5, fy=0.5) cv2.imshow("You will succeed in the end", my_image) cv2.waitKey() print(time, weather, content) if __name__ == "__main__": main()
欢迎关注公众号:
