代码:
1 import requests 2 from bs4 import BeautifulSoup 3 4 def html_save(s): 5 with open('哔哩哔哩.csv','a')as f: 6 f.write(s+' ') 7 8 def parse_html(url): 9 docx=requests.get(url) 10 soup=BeautifulSoup(docx.text,'html.parser') 11 c_txt=soup.find('ul',{'class':'nav-menu'}).find_all('li') 12 for i in c_txt: 13 if i.string!=None: 14 print(i.string) 15 html_save(i.string) 16 17 parse_html('https://www.bilibili.com/')
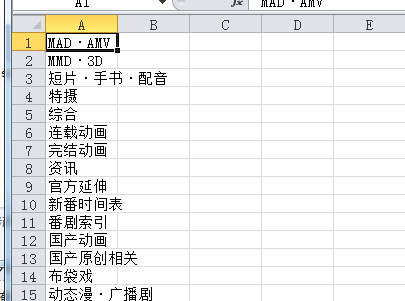
运行截图:

保存的文件: