1、依赖
<properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <flink.version>1.7.2</flink.version> <slf4j.version>1.7.7</slf4j.version> <log4j.version>1.2.17</log4j.version> <scala.version>2.11.8</scala.version> </properties> <dependencies> <!-- https://mvnrepository.com/artifact/org.apache.flink/flink-java --> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-java</artifactId> <version>${flink.version}</version> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.flink/flink-streaming-java --> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-streaming-java_2.11</artifactId> <version>${flink.version}</version> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.flink/flink-scala --> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-scala_2.11</artifactId> <version>${flink.version}</version> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.flink/flink-streaming-scala --> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-streaming-scala_2.11</artifactId> <version>${flink.version}</version> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.bahir/flink-connector-redis --> <dependency> <groupId>org.apache.bahir</groupId> <artifactId>flink-connector-redis_2.11</artifactId> <version>1.0</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-connector-kafka-0.11_2.11</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-connector-filesystem_2.11</artifactId> <version>1.7.2</version> </dependency> <!--alibaba fastjson--> <dependency> <groupId>com.alibaba</groupId> <artifactId>fastjson</artifactId> <version>1.2.51</version> </dependency> <!--******************* 日志 *******************--> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId> <version>${slf4j.version}</version> <scope>runtime</scope> </dependency> <dependency> <groupId>log4j</groupId> <artifactId>log4j</artifactId> <version>${log4j.version}</version> <scope>runtime</scope> </dependency> <!--******************* kafka *******************--> <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> <version>0.11.0.2</version> </dependency> </dependencies>
2、代码实现一:
//1.创建StreamExecutionEnvironment val env=StreamExecutionEnvironment.getExecutionEnvironment val props=new Properties() props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"CentOS:9092") props.put(ConsumerConfig.GROUP_ID_CONFIG,"g1") val kafkaConsumer=new FlinkKafkaConsumer("topic01",new SimpleStringSchema(),props) val redisConfig=new FlinkJedisPoolConfig.Builder() .setHost("CentOS") .setPort(6379) .build() val redisSink= new RedisSink(redisConfig,new WordPairRedisMapper) //2.设置Source val lines:DataStream[String]=env.addSource[String](kafkaConsumer) lines.flatMap(_.split("\s+")) .map((_,1)) .keyBy(0) .sum(1) .addSink(redisSink) //4.执行任务 env.execute("wordcount")
package com.baizhi.demo03 import org.apache.flink.streaming.connectors.redis.common.mapper.{RedisCommand, RedisCommandDescription, RedisMapper} class WordPairRedisMapper extends RedisMapper[(String,Int)]{ override def getCommandDescription: RedisCommandDescription = { new RedisCommandDescription(RedisCommand.HSET,"clicks") } override def getKeyFromData(t: (String, Int)): String = { t._1 } override def getValueFromData(t: (String, Int)): String = { t._2.toString } }
3、代码实现二:
package ryx; import com.alibaba.fastjson.JSONArray; import com.alibaba.fastjson.JSONObject; import org.apache.flink.api.common.serialization.SimpleStringSchema; import org.apache.flink.streaming.api.CheckpointingMode; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.CheckpointConfig; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.co.CoFlatMapFunction; import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer011; import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer011; import org.apache.flink.streaming.util.serialization.KeyedSerializationSchemaWrapper; import org.apache.flink.util.Collector; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import ryx.source.MyRedisSource; import java.util.HashMap; import java.util.Properties; public class DataClean { private static Logger logger= LoggerFactory.getLogger(DataClean.class); public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); //checkpoint配置 env.enableCheckpointing(60000); env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE); env.getCheckpointConfig().setMinPauseBetweenCheckpoints(30000); env.getCheckpointConfig().setCheckpointTimeout(10000); env.getCheckpointConfig().setMaxConcurrentCheckpoints(1); env.getCheckpointConfig().enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION); //设置statebackend //env.setStateBackend(new RocksDBStateBackend("hdfs://hadoop100:9000/flink/checkpoints",true)); String topicS="allData"; Properties prop = new Properties(); prop.setProperty("group.id", "cleanData"); prop.setProperty("bootstrap.servers","hadoop01:9092,hadoop02:9092,hadoop03:9092"); FlinkKafkaConsumer011<String> myConsumer = new FlinkKafkaConsumer011<String>(topicS, new SimpleStringSchema(), prop); //读取kafka中的数据 /** *{"dt":"2019-10-10 16:45:32","countryCode":"US","data":[{"type":"s5","score":0.5,"level":"B"},{"type":"s1","score":0.8,"level":"B"}]} *{"dt":"2019-10-10 16:45:34","countryCode":"HK","data":[{"type":"s5","score":0.5,"level":"A"},{"type":"s3","score":0.3,"level":"D"}]} *{"dt":"2019-10-10 16:45:36","countryCode":"KW","data":[{"type":"s1","score":0.1,"level":"B"},{"type":"s4","score":0.2,"level":"A"}]} *{"dt":"2019-10-10 16:45:38","countryCode":"HK","data":[{"type":"s2","score":0.2,"level":"A+"},{"type":"s3","score":0.1,"level":"C"}]} */ DataStreamSource<String> data = env.addSource(myConsumer); //这里是前面的博客的----flink从redis中获取数据作为source源 DataStreamSource<HashMap<String, String>> mapData = env.addSource(new MyRedisSource()); DataStream<String> resData = data.connect(mapData).flatMap(new CoFlatMapFunction<String, HashMap<String, String>, String>() { //存储国家和大区的映射关系 private HashMap<String, String> allMap = new HashMap<String, String>(); //flatMap1处理获取kafka中的数据 public void flatMap1(String value, Collector<String> out) throws Exception { JSONObject jsonObject = JSONObject.parseObject(value); String dt = jsonObject.getString("dt"); String area = jsonObject.getString("countryCode"); logger.info("获取的时间戳为:" + dt + "---获取的国家为: " + area); System.out.println("获取的时间戳为:" + dt + "---获取的国家为: " + area); //获取大区的 String ar = allMap.get(area); JSONArray jsonArr = jsonObject.getJSONArray("data"); logger.info("获取的json字符串的data大小为:" + jsonArr.size()+"ar:"+ar); for (int i = 0; i < jsonArr.size(); i++) { JSONObject jsonOb = jsonArr.getJSONObject(i); logger.info("获取的data的json数组的数据为" + jsonOb); jsonOb.put("area", ar); jsonOb.put("dt", dt); out.collect(jsonOb.toJSONString()); System.out.println("获取的Json字符串为:" + jsonOb.toJSONString()); } } //flatMap2处理获取redis中的数据 public void flatMap2(HashMap<String, String> value, Collector<String> out) throws Exception { this.allMap=value; } }); String outTopic="allDataClean"; Properties outProp = new Properties(); outProp.setProperty("bootstrap.servers","hadoop01:9092,hadoop02:9092,hadoop03:9092"); //设置事务超市时间 outProp.setProperty("transaction.timeout.ms",60000*15+""); FlinkKafkaProducer011<String> writeKafka = new FlinkKafkaProducer011<String>(outTopic, new KeyedSerializationSchemaWrapper<String>(new SimpleStringSchema()), outProp, FlinkKafkaProducer011.Semantic.EXACTLY_ONCE); resData.addSink(writeKafka); env.execute("DataCLean"); } }
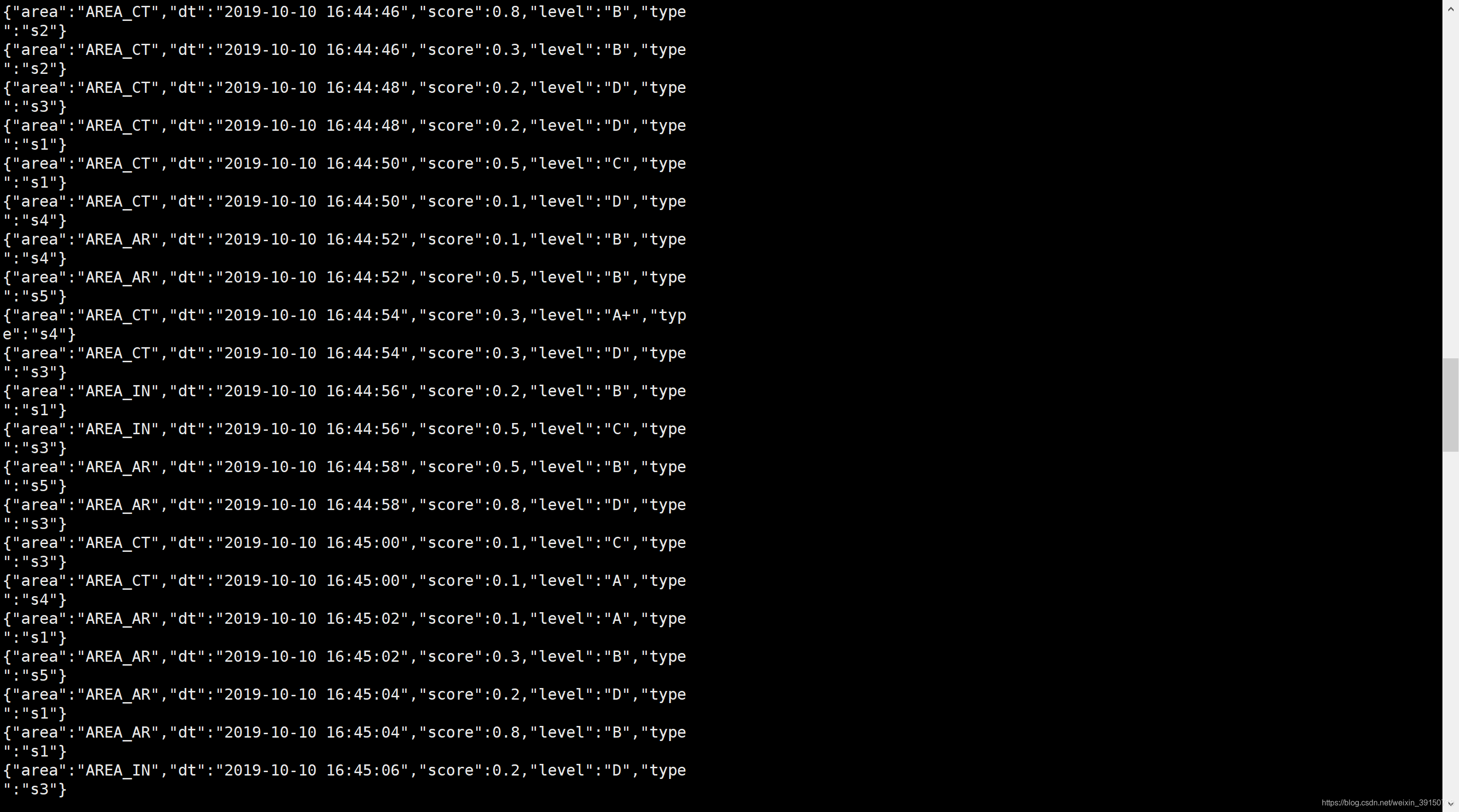
结果:
key:AREA_USvalueUS
key:AREA_CTvalueTW,HK
key:AREA_ARvaluePK,KW,SA
key:AREA_INvalueIN
获取的时间戳为:2019-10-10 16:45:38—获取的国家为: HK
获取的Json字符串为:{“area”:“AREA_CT”,“dt”:“2019-10-10 16:45:38”,“score”:0.2,“level”:“A+”,“type”:“s2”}
获取的Json字符串为:{“area”:“AREA_CT”,“dt”:“2019-10-10 16:45:38”,“score”:0.1,“level”:“C”,“type”:“s3”}
获取的时间戳为:2019-10-10 16:45:40—获取的国家为: KW
获取的Json字符串为:{“area”:“AREA_AR”,“dt”:“2019-10-10 16:45:40”,“score”:0.2,“level”:“A+”,“type”:“s3”}
获取的Json字符串为:{“area”:“AREA_AR”,“dt”:“2019-10-10 16:45:40”,“score”:0.2,“level”:“A+”,“type”:“s5”}
获取的时间戳为:2019-10-10 16:45:42—获取的国家为: US
获取的Json字符串为:{“area”:“AREA_US”,“dt”:“2019-10-10 16:45:42”,“score”:0.2,“level”:“D”,“type”:“s3”}
获取的Json字符串为:{“area”:“AREA_US”,“dt”:“2019-10-10 16:45:42”,“score”:0.2,“level”:“C”,“type”:“s4”}
key:AREA_USvalueUS
key:AREA_CTvalueTW,HK
key:AREA_ARvaluePK,KW,SA
key:AREA_INvalueIN
获取的时间戳为:2019-10-10 16:45:44—获取的国家为: IN
获取的Json字符串为:{“area”:“AREA_IN”,“dt”:“2019-10-10 16:45:44”,“score”:0.2,“level”:“A”,“type”:“s1”}
获取的Json字符串为:{“area”:“AREA_IN”,“dt”:“2019-10-10 16:45:44”,“score”:0.2,“level”:“B”,“type”:“s1”}
获取的时间戳为:2019-10-10 16:45:46—获取的国家为: US
获取的Json字符串为:{“area”:“AREA_US”,“dt”:“2019-10-10 16:45:46”,“score”:0.5,“level”:“A”,“type”:“s5”}
获取的Json字符串为:{“area”:“AREA_US”,“dt”:“2019-10-10 16:45:46”,“score”:0.8,“level”:“C”,“type”:“s3”}
图片: