一、re的match与search方法
1.re.match方法
re.match 尝试从字符串的起始位置匹配一个模式,匹配成功re.match方法返回一个匹配的对象,如果不是起始位置匹配成功的话,match()就返回none。函数语法:
re.match(pattern, string[, flags])
函数参数说明:
pattern:匹配的正则表达式
string:要匹配的字符
flags:标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等
2.match对象
可以使用group() 、 groups()、groupdict() 匹配对象函数来获取匹配表达式。
group([group1, …]): 获得一个或多个分组截获的字符串;指定多个参数时将以元组形式返回。group1可以使用编号也可以使用别名;编号0代表整个匹配的子串;不填写参数时,返回group(0);没有截获字符串的组返回None;截获了多次的组返回最后一次截获的子串
groups([default]): 以元组形式返回全部分组截获的字符串。相当于调用group(1,2,…last)。default表示没有截获字符串的组以这个值替代,默认为None。
groupdict([default]): 返回以有别名的组的别名为键、以该组截获的子串为值的字典,没有别名的组不包含在内。default含义同上。
3.re.search方法
re.search 扫描整个字符串并返回第一个成功的匹配。匹配成功re.search方法返回一个匹配的对象,否则返回None。函数语法:
re.search(pattern, string, flags=0)
参数说明:
pattern:匹配的正则表达式
string:要匹配的字符
flags:标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等
程序例子:
match与search方法的区别:
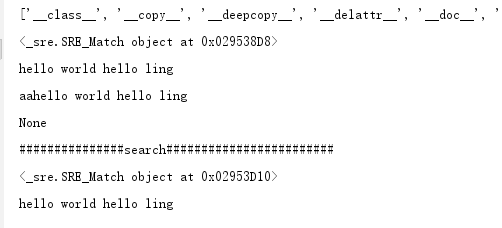
import re reg = re.compile(r'(hello w.*)(hello l.*)') print (dir(reg)) a = 'hello world hello ling' result = reg.match(a) print (result) print (result.group()) b='aa'+a print (b) result2 = reg.match(b) print (result2) #正则对象的search print ('###############search########################') result3 = reg.search(b) print (result3) print (result3.group())
结果:
group() 、 groups()、groupdict()三种获取方式的区别:
import re prog = re.compile(r'(?P<tagname>abc)(.*)(?P=tagname)') result = prog.match('abclfjlad234sjldabc') print(dir(result)) print ('##########groups()##############') print (result.groups()) print ('##########group()##############') print (result.group(2)) print (result.group(1)) print (result.group('tagname')) print ('##########groupdict()##############') print (result.groupdict())
结果:

二、re的split、findall、finditer方法
split(string[, maxsplit]):按照能够匹配的子串将string分割后返回列表。maxsplit用于指定最大分割次数,不指定将全部分割。
findall(string[, pos[, endpos]]) :搜索string,以列表形式返回全部能匹配的子串.
finditer(string[, pos[, endpos]]):搜索string,返回一个顺序访问每一个匹配结果(Match对象)的迭代器。
程序例子如下:
import re p1 = re.compile(r'd+') a_str = 'one1two2three3four4' #正则对象的split方法,使用正则匹配进行分割字符串 #以列表的形式返回 print(p1.split(a_str)) #正则对象的findall方法,来查找符合对象的字符串 #最后是以列表的形式返回 print (p1.findall(a_str)) for i in p1.finditer(a_str): print (i.group())
结果:
