
/* 时间:2018/08/22 功能:get请求 目录: 一: 安装request 1 安装软件 2 pip常用命令 3 登录官网 二: get请求 1 无参 2 有参 - 存放url 3 有参 - 存放params 4 cookie 5 解码 三: 其他 1 详解request 2 错误提示 - SSL 3 警告提示 */
一: 安装pip
1 安装软件
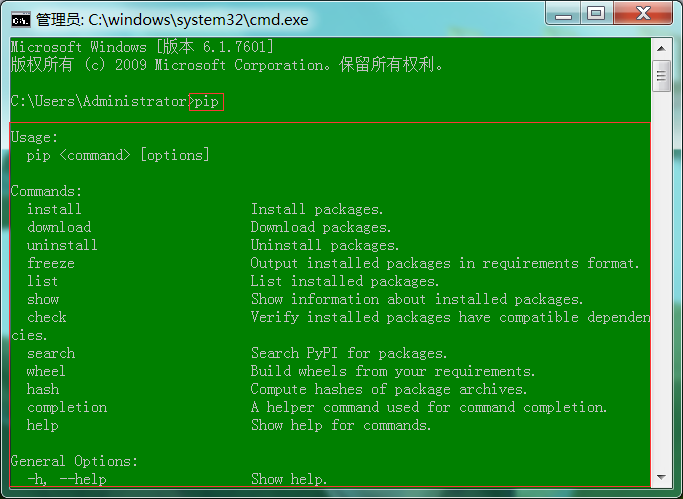
1 : 运行输入"cmd",进入Dos窗口。
2 : 输入"pip",出现如图说明python自带工具pip没问题。
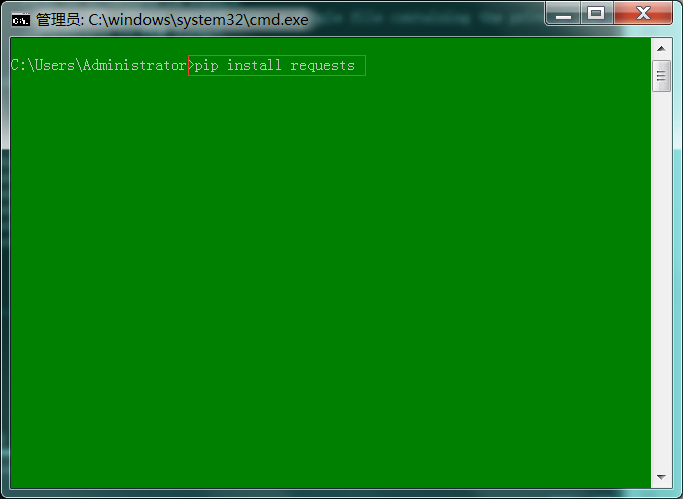
1 : 输入"pip install requests"(安装requests模块)。
2 : 不要打开fiddler或其他代理工具,否则会报SSL错误,https请求没有证书。
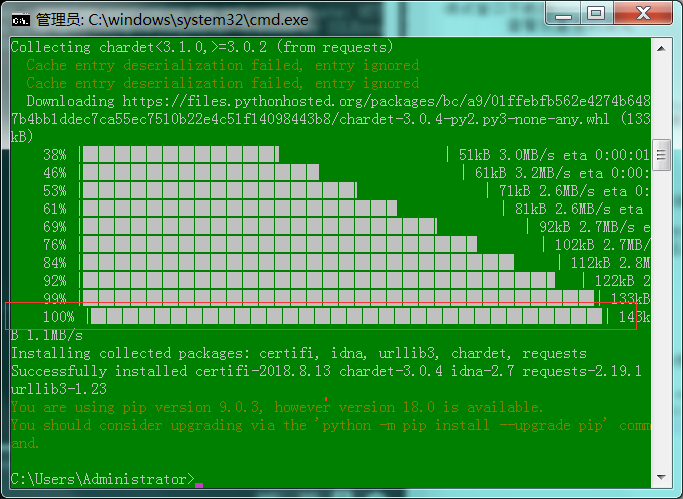
1 : 如图安装进度到100%。
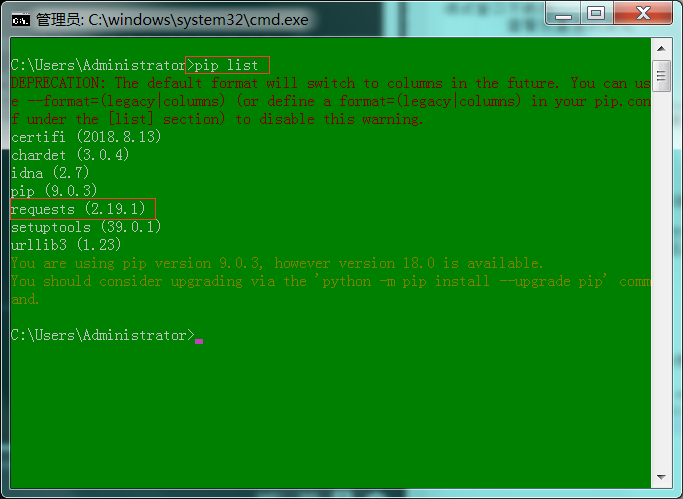
1 : 验证安装,输入"pip list"(查看安装模块)。
2 : 出现红框内request模块,说明安装成功。
2 pip常用命令
1 : pip install 模块名称 - 安装模块。
2 : pip uninstall 模块名称 - 卸载模块。
3 : pip list - 查看已安装模块。
3 登录官网
1 : 访问官网: http://cn.python-requests.org/zh_CN/latest/。
2 : 最好资料: 官方文档、书籍、博客
二: get请求
1 无参
1 : 访问网站: https://www.juhe.cn/。
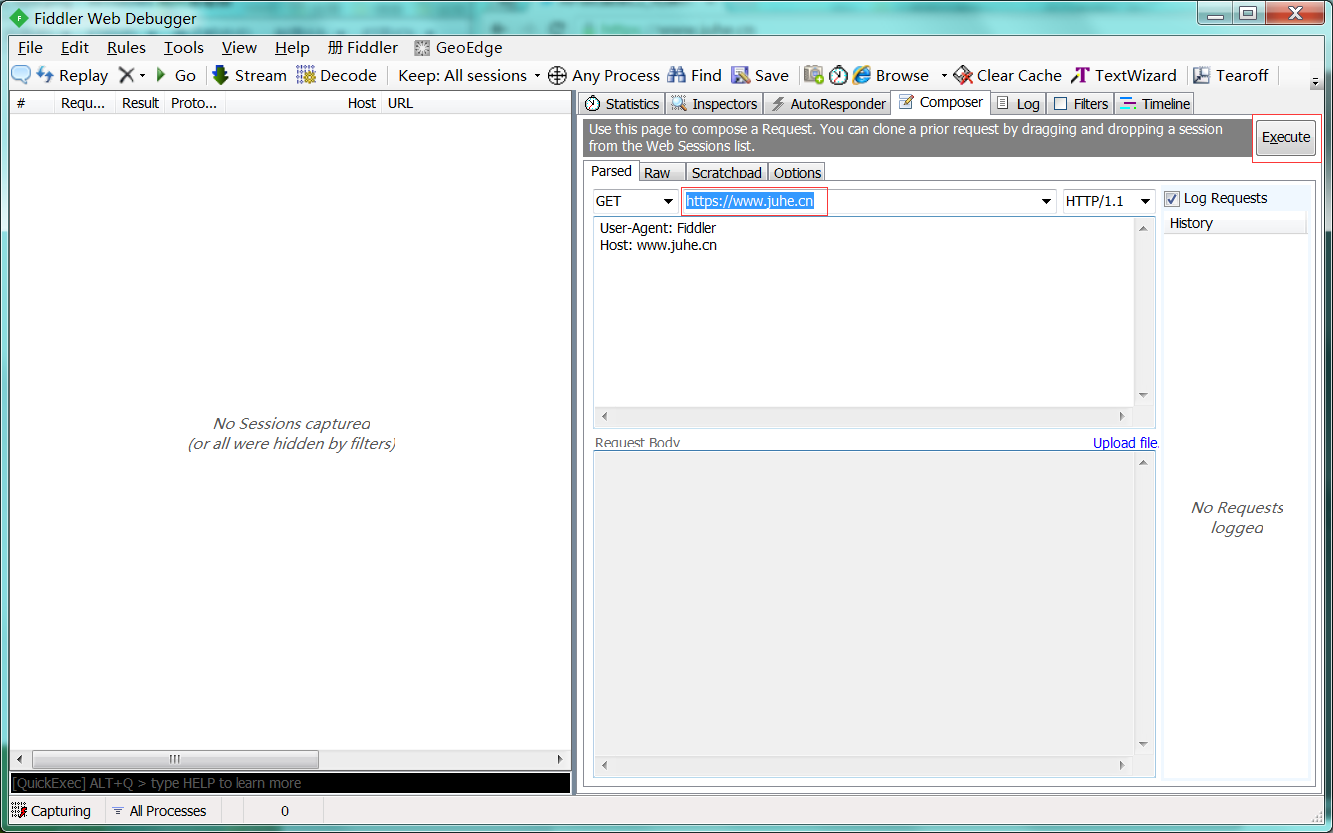
1 : 先使用fiddler测试。
2 : 请求方式 - get; url - http:https://www.juhe.cn/。
3 : 点击"Execute"。
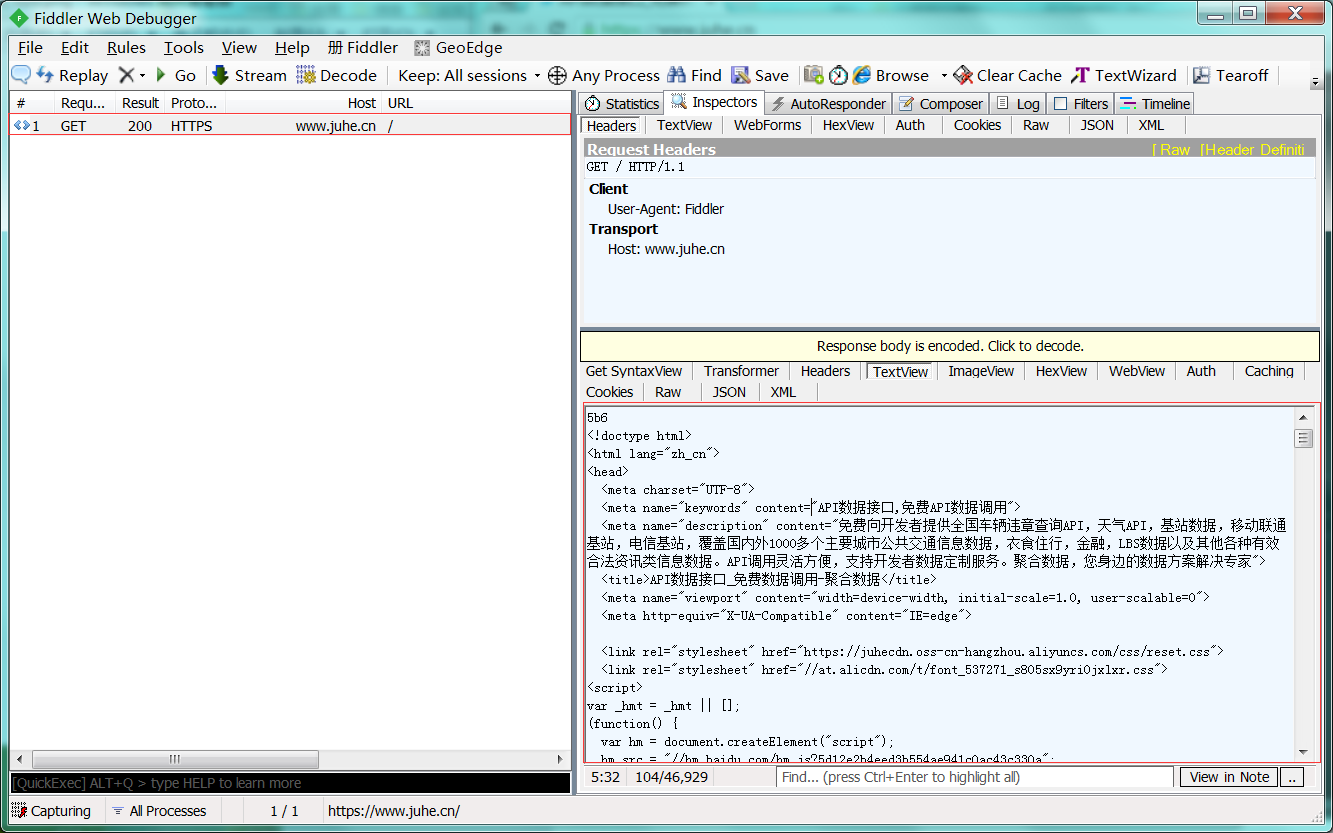
1 : 查看刚才请求,查看返回数据没有问题。
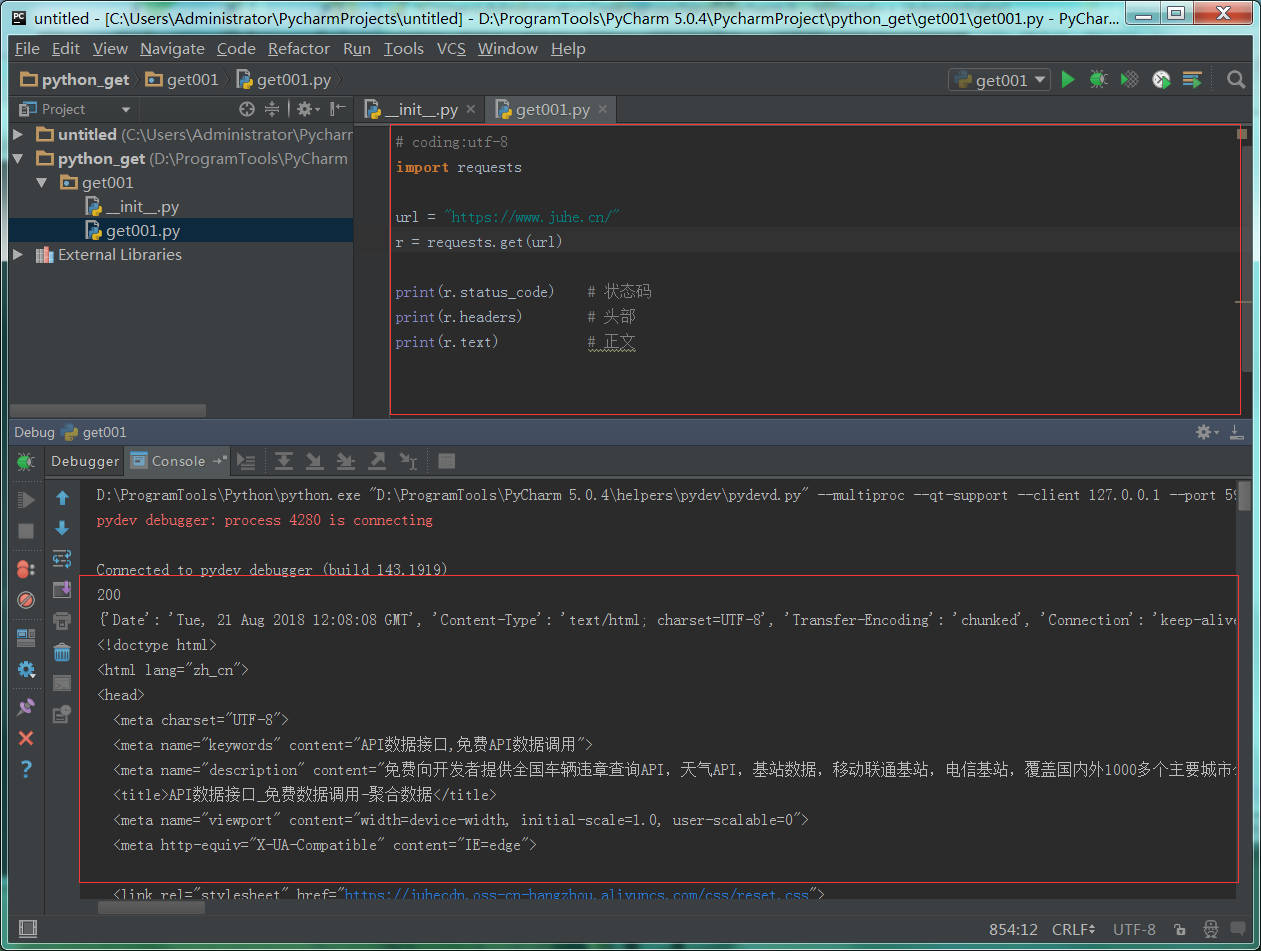
1 : python代码请求。
# coding:utf-8
import requests
url = "https://www.juhe.cn/"
r = requests.get(url)
print(r.status_code) # 状态码
print(r.headers) # 头部
print(r.text) # 正文
2 : 查看返回结果,和Fiddler一样。
2 有参 - 存放url
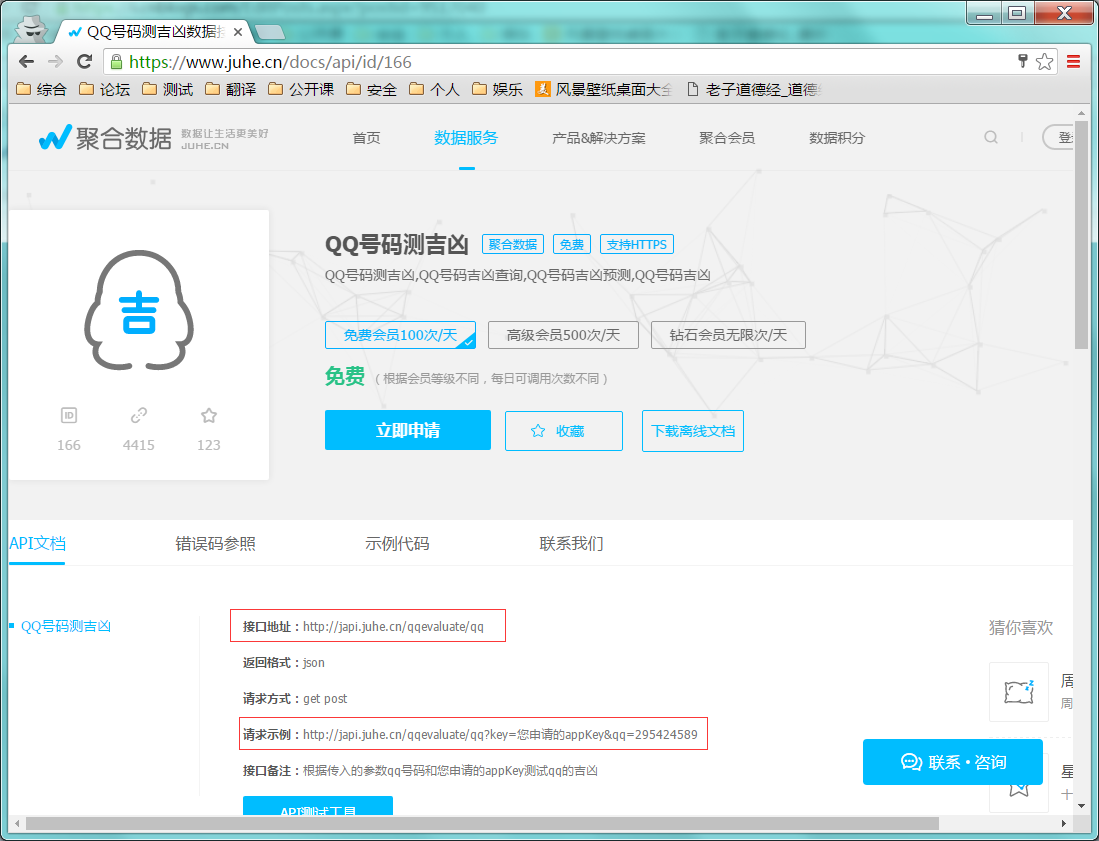
1 : 访问网址:https://www.juhe.cn/docs/api/id/166 ,使用第三方提供的接口。
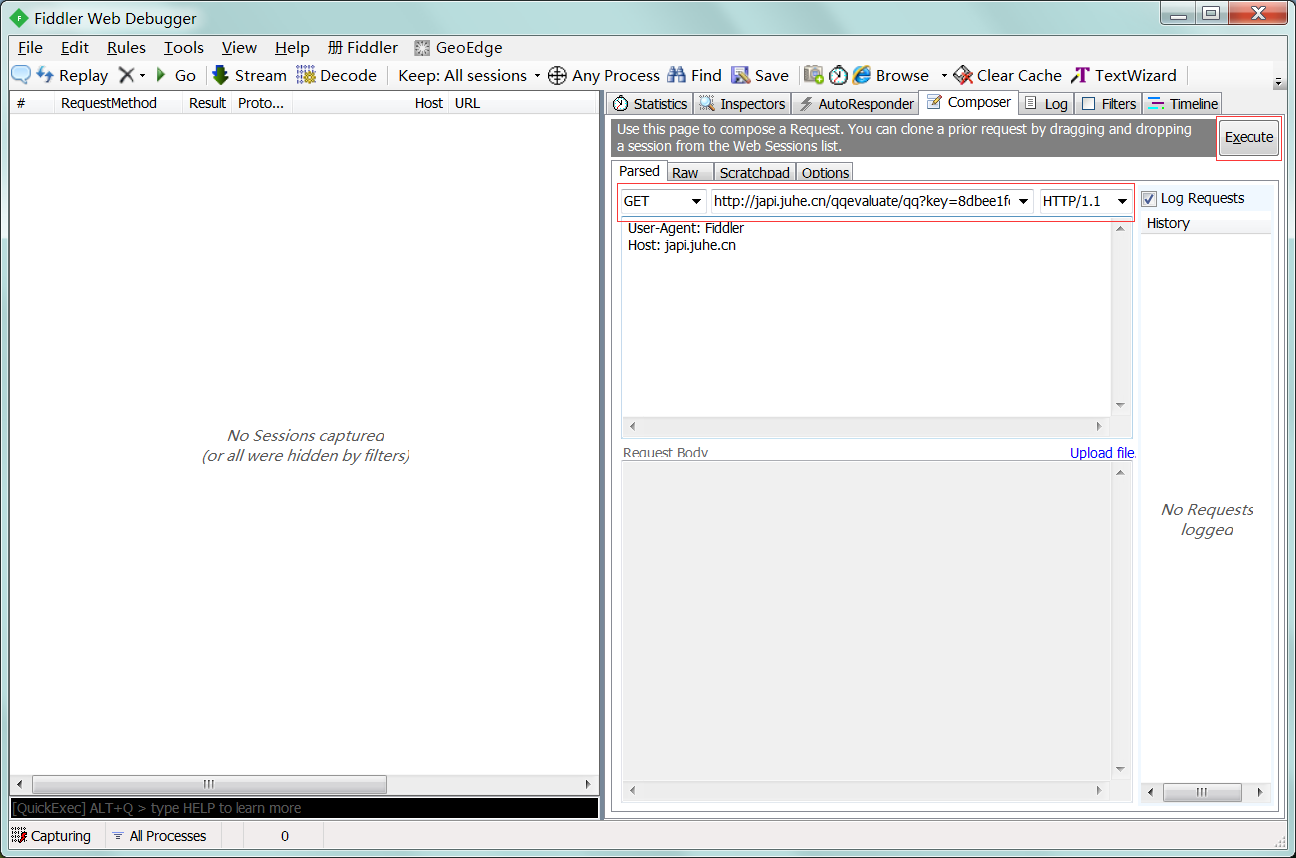
1 : 先使用fiddler请求。
2 : 请求方式 - get; url - http://japi.juhe.cn/qqevaluate/qq?key=appKey&qq=qq
3 : 点击"Execute"。
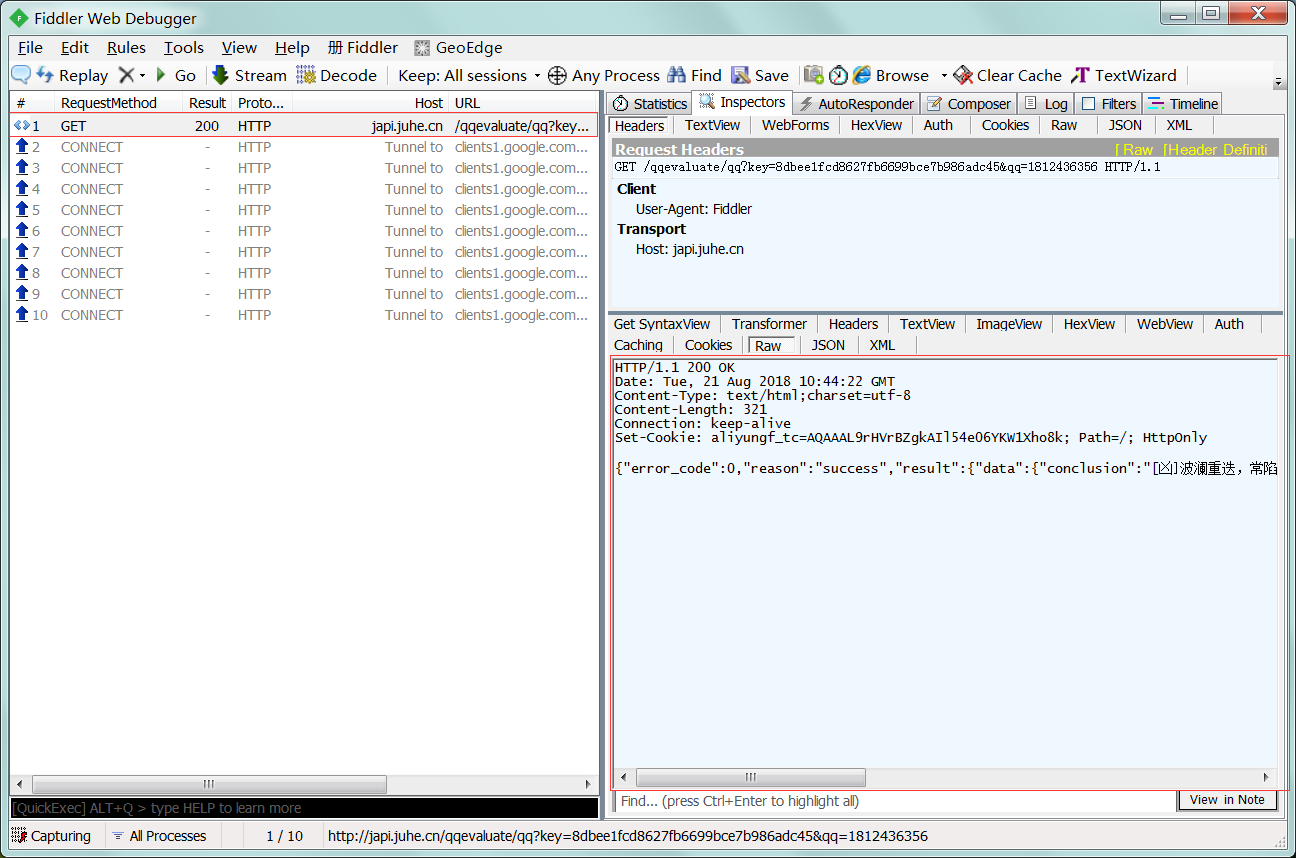
1 : 查看刚才请求,查看返回数据没有问题。
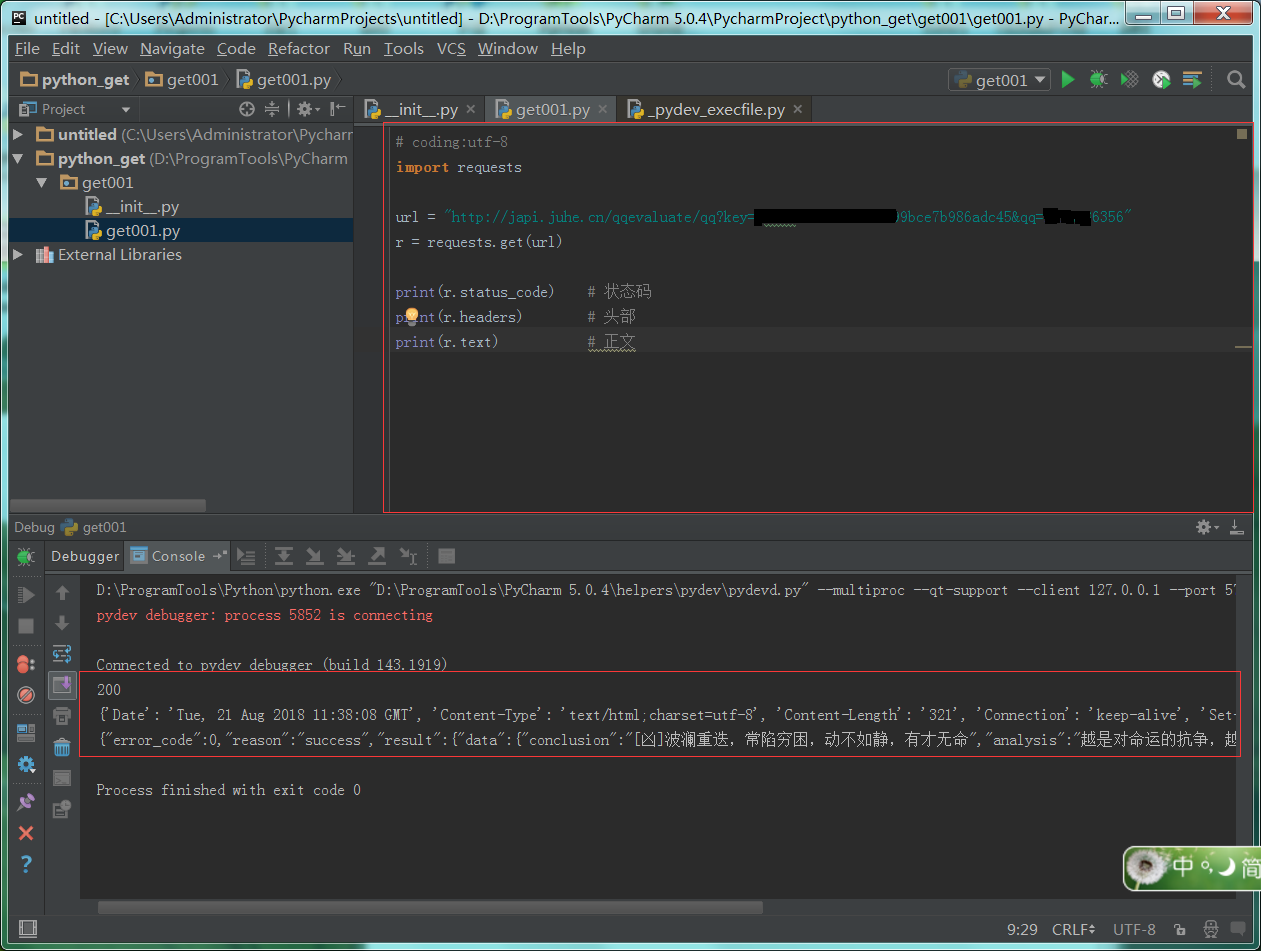
1 : python代码请求。
2 : 查看返回结果,和Fiddler一样。
3 有参 - 存放params
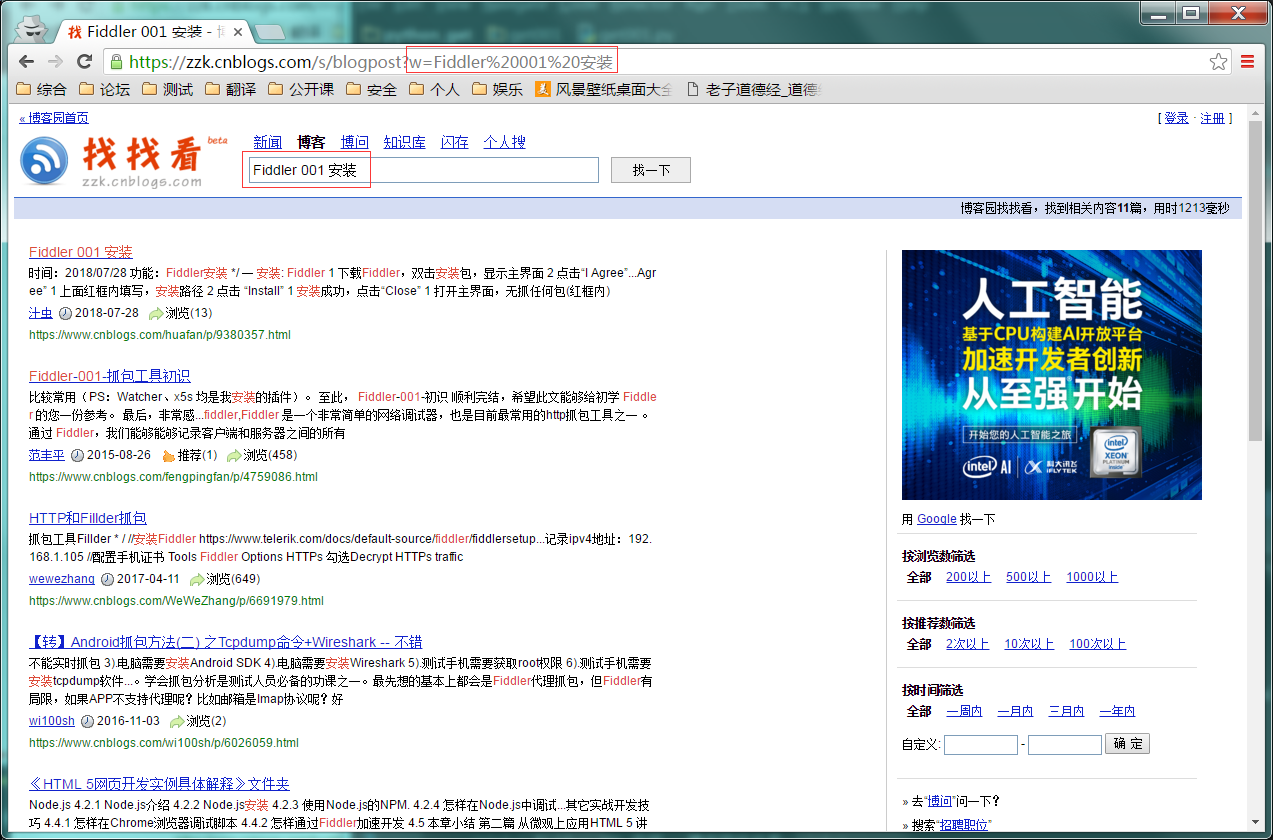
1 : 访问网址: https://zzk.cnblogs.com/s/blogpost。
2 : 搜索框内输入: Fiddler 001 安装。
3 : 点击查找一下。
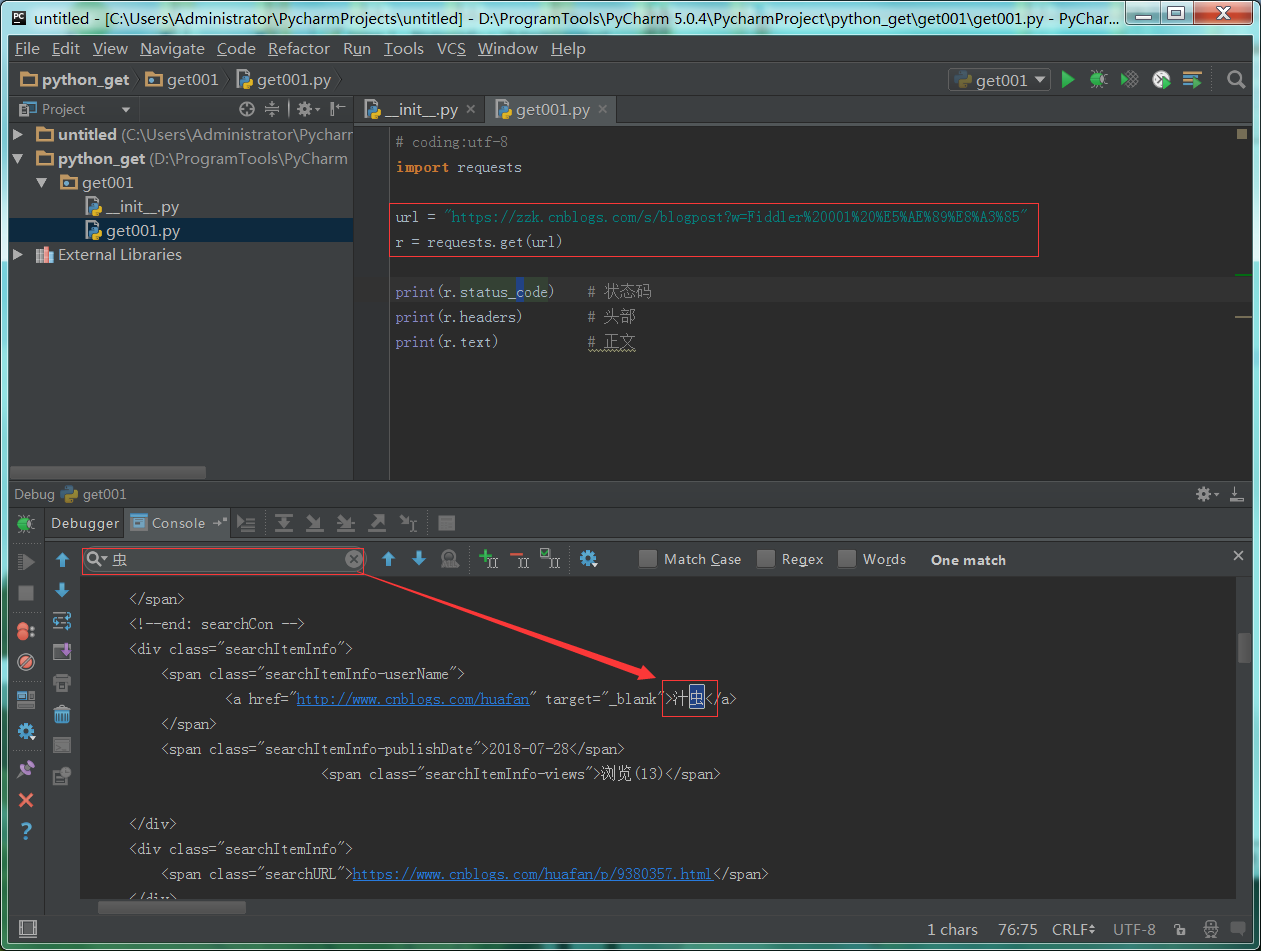
1 : python代码实现。
# coding:utf-8
import requests
url = "https://zzk.cnblogs.com/s/blogpost?w=Fiddler 001 安装"
r = requests.get(url)
print(r.status_code) # 状态码
print(r.headers) # 头部
print(r.text) # 正文
2 : 查看搜索结果和浏览器一样。
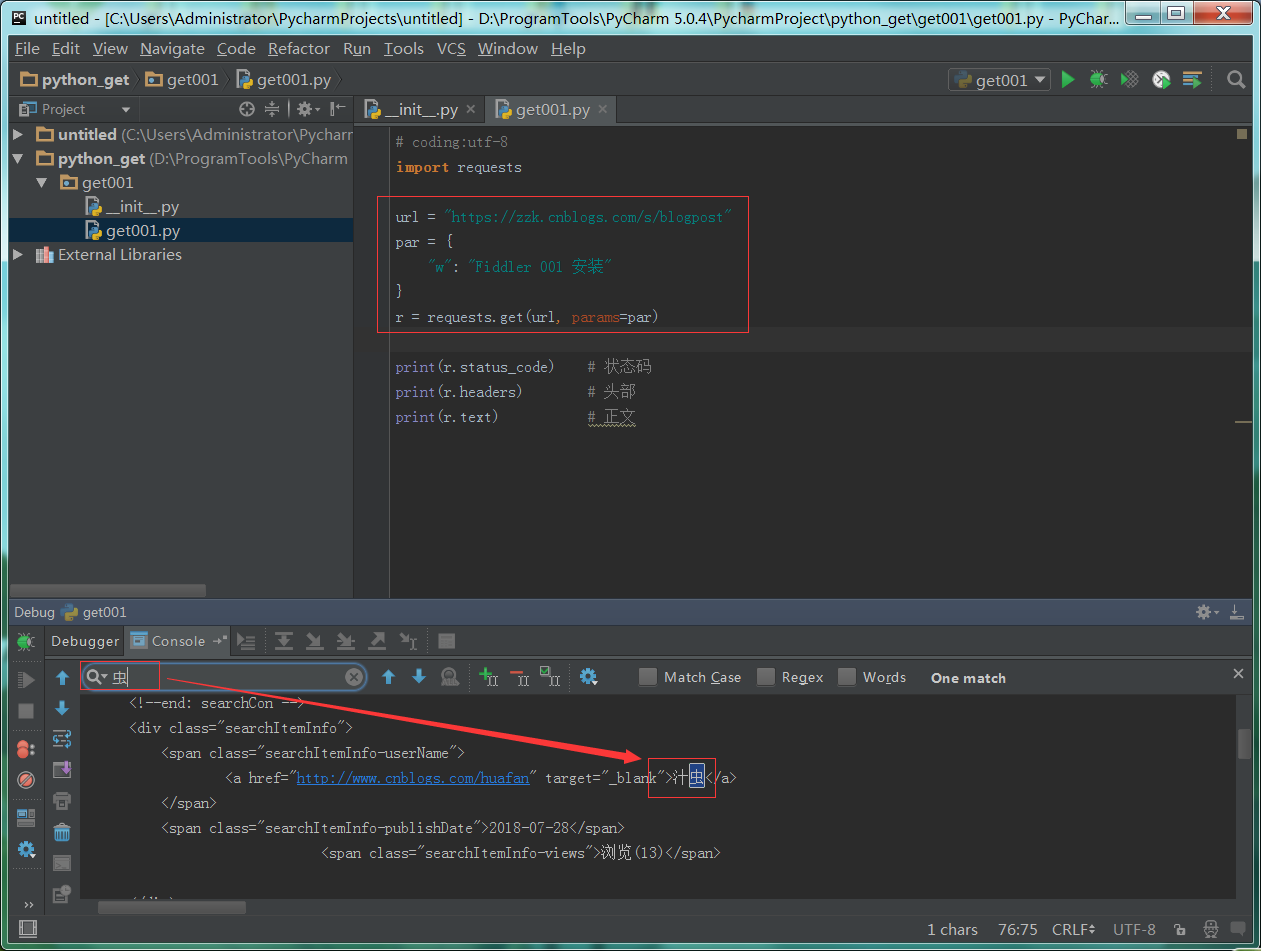
1 : python代码实现。
# coding:utf-8
import requests
url = "https://zzk.cnblogs.com/s/blogpost"
par = {
"w" : "Fiddler 001 安装"
}
r = requests.get(url, params = par)
print(r.status_code) # 状态码
print(r.headers) # 头部
print(r.text) # 正文
2 : 查看搜索结果和浏览器一样。
4 cookie
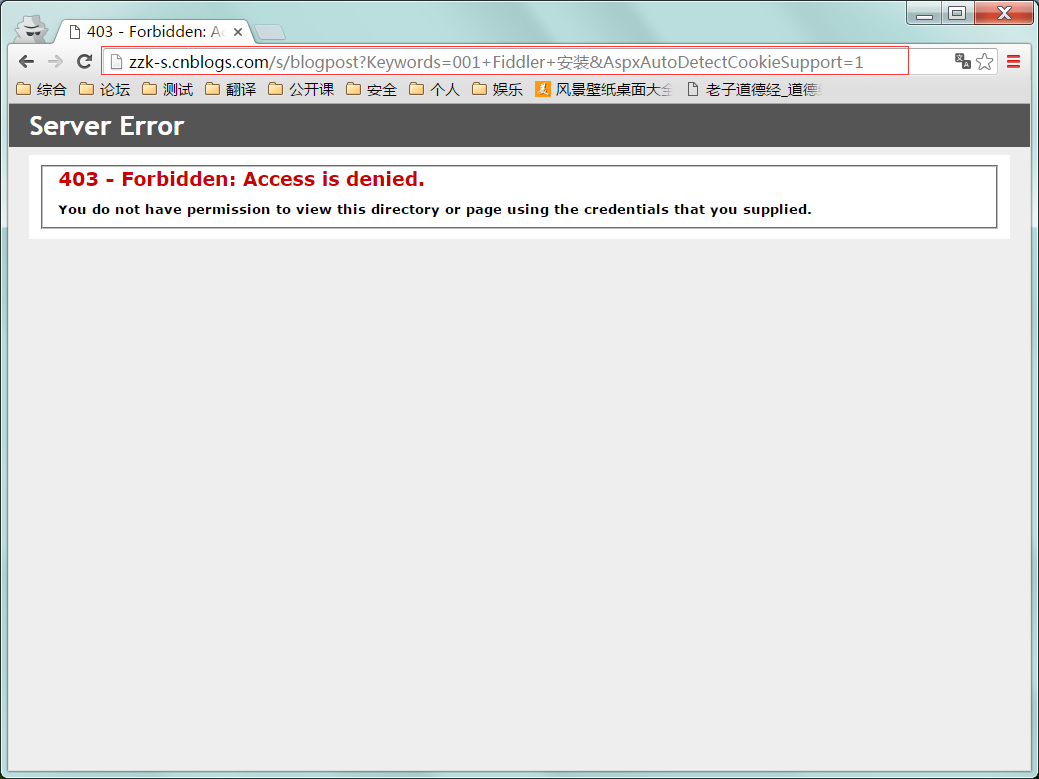
1 : 访问网址: http://zzk-s.cnblogs.com/s/blogpost?Keywords=001+Fiddler+安装。
2 : 报错403没有权限,原因是缺少cookie。
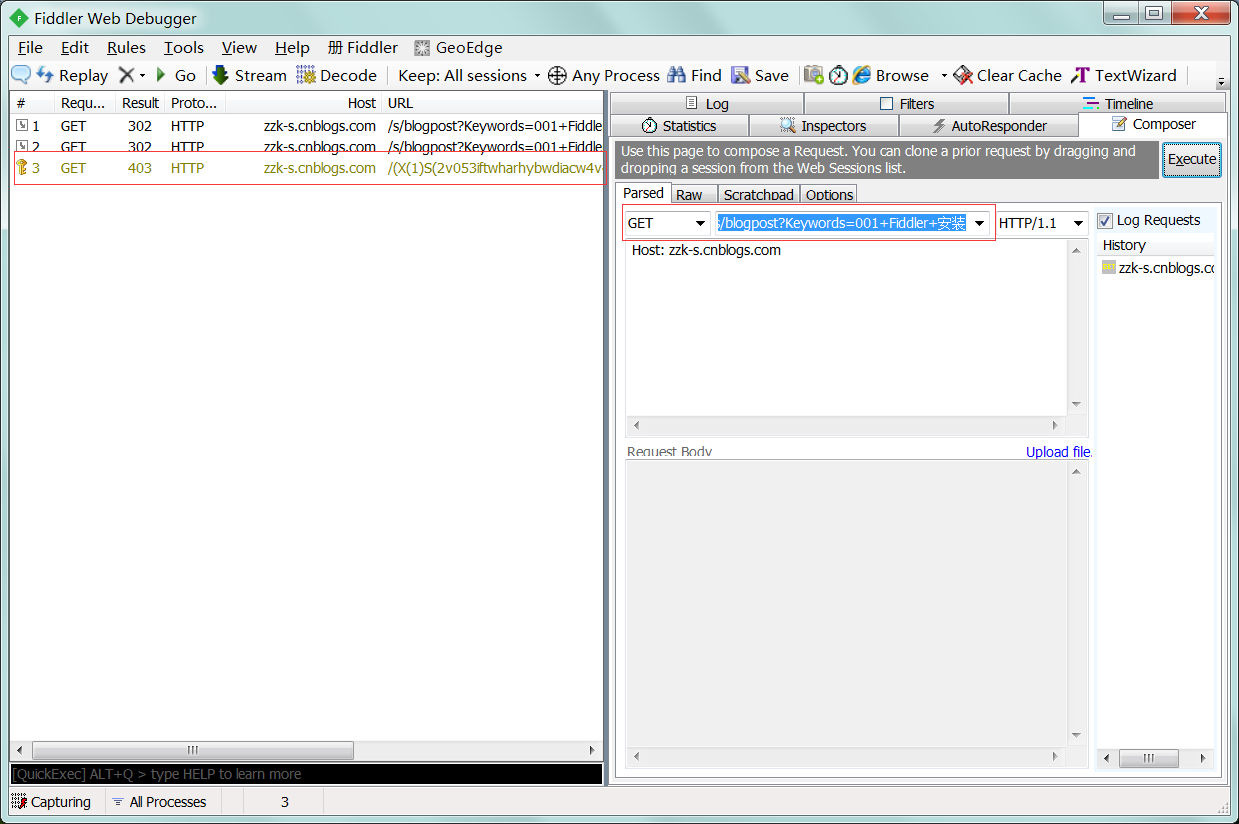
1 : 先使用fiddler请求。
2 : 请求方式 - get; url - http://zzk-s.cnblogs.com/s/blogpost?Keywords=001+Fiddler+安装
3 : 点击"Execute",发现执行结果也是403。
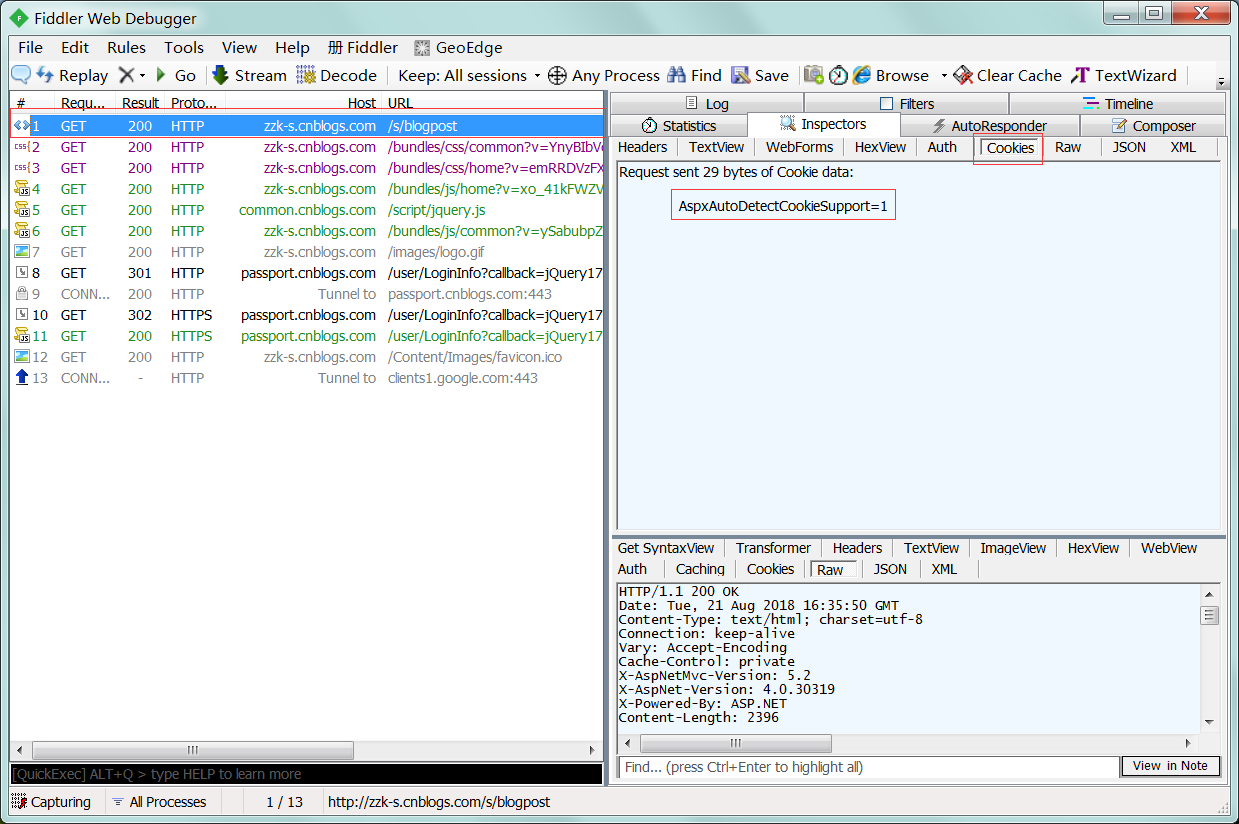
1 : 浏览器访问,http://zzk-s.cnblogs.com/s/blogpost (去掉参数的url)。
2 : 抓取该请求,查看cookie。
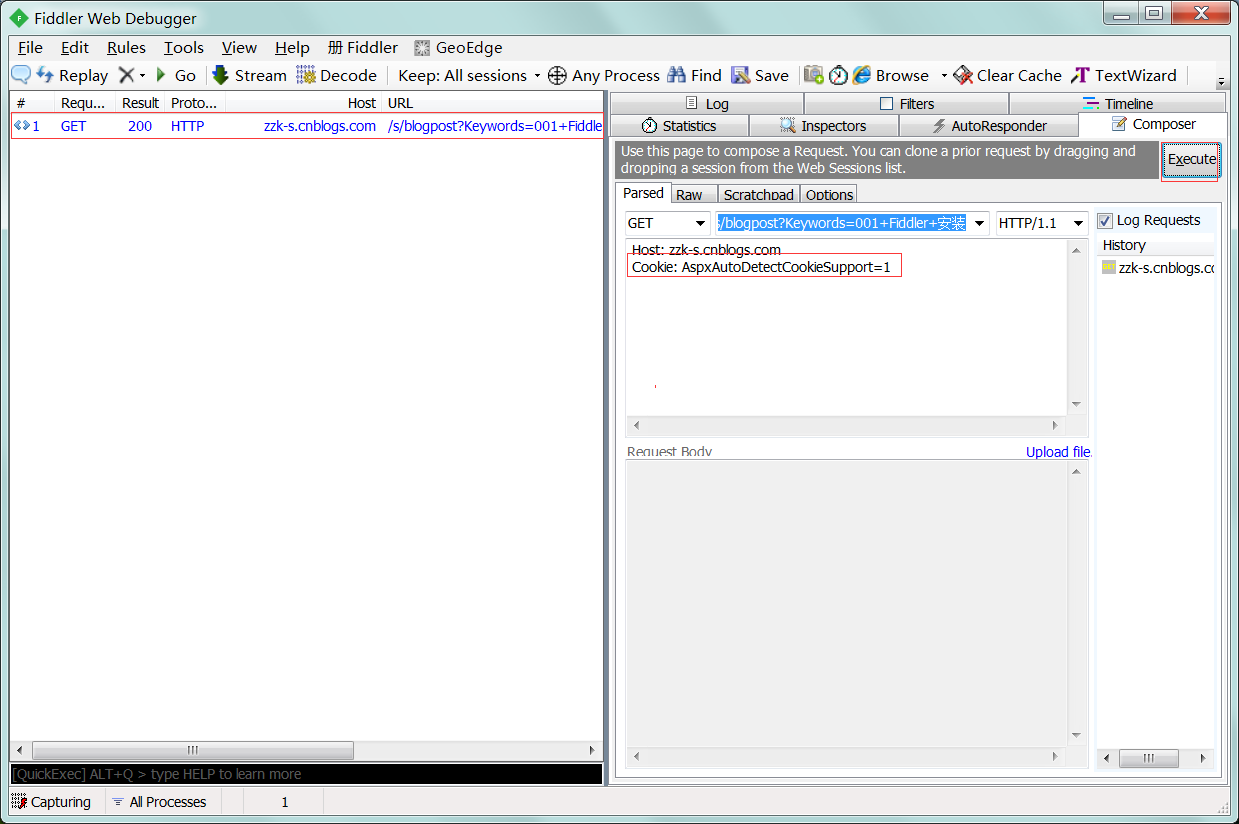
1 : 先使用fiddler请求。
2 : 请求方式 - get; url - http://zzk-s.cnblogs.com/s/blogpost?Keywords=001+Fiddler+安装
3 : 头部添加cookie信息,"Cookie": "AspxAutoDetectCookieSupport=1"。
4 : 点击"Execute",执行成功。
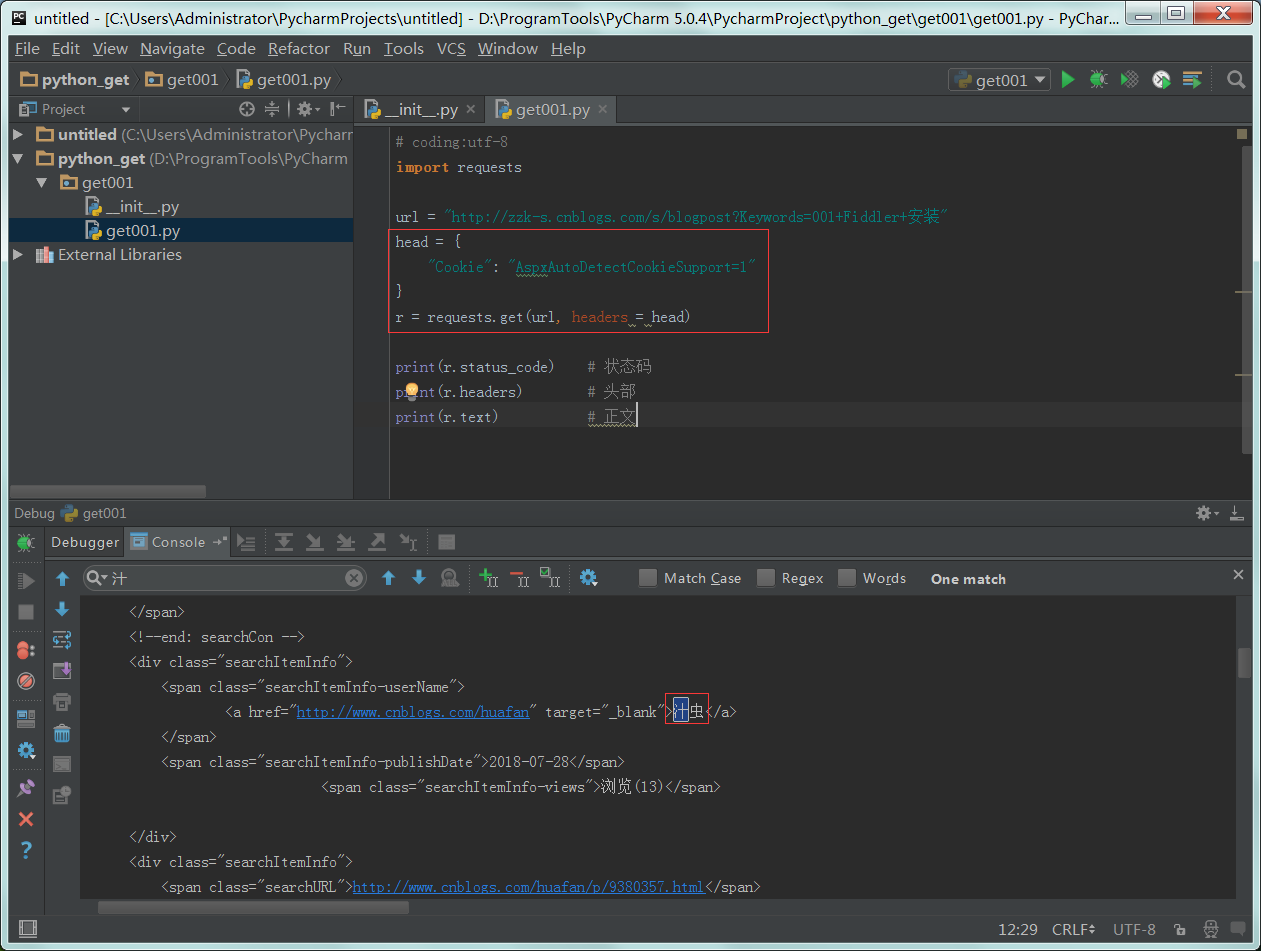
1 : python代码实现。
 View Code
View Code2 : 查看搜索结果和浏览器一样。
5 解码
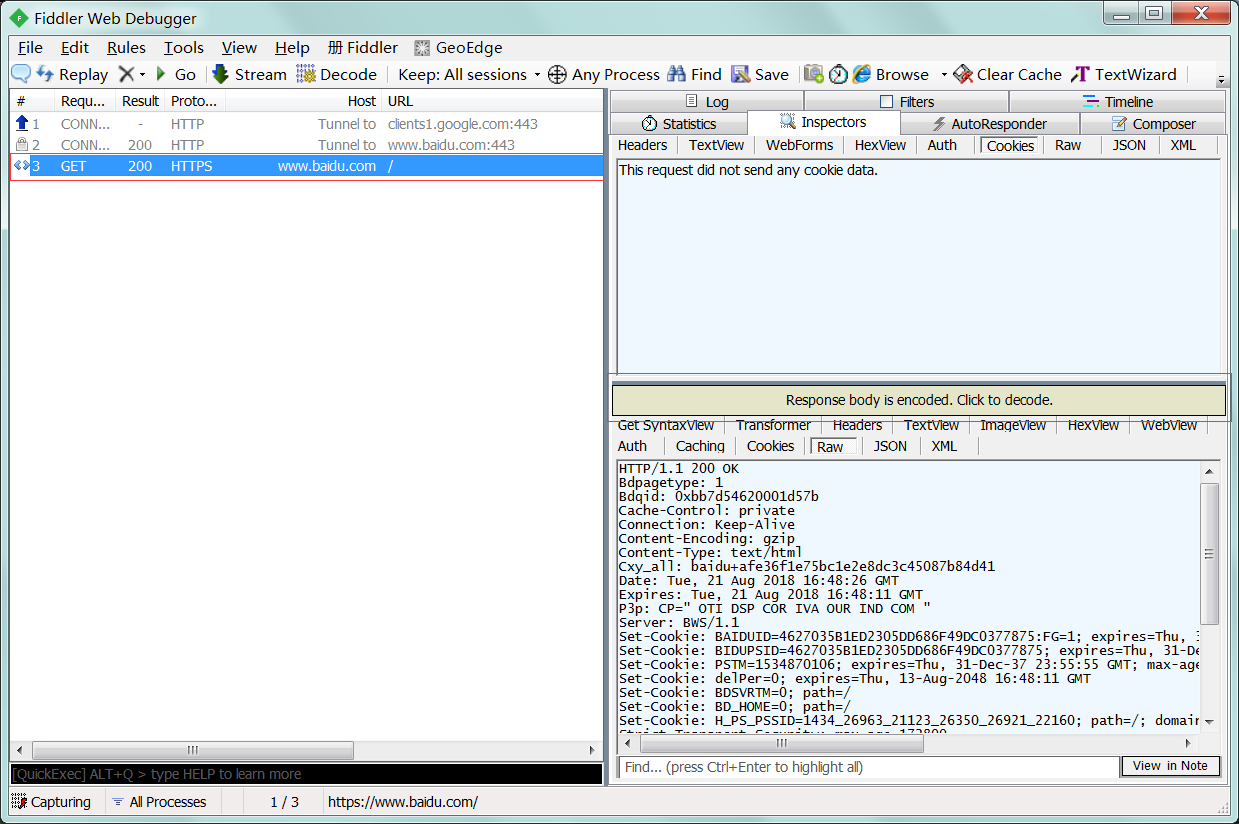
1 : 浏览器访问 https://www.baidu.com/。
2 : 点击右侧红框内的按钮,解码数据和浏览器一样。这是Fiddler自带解码,
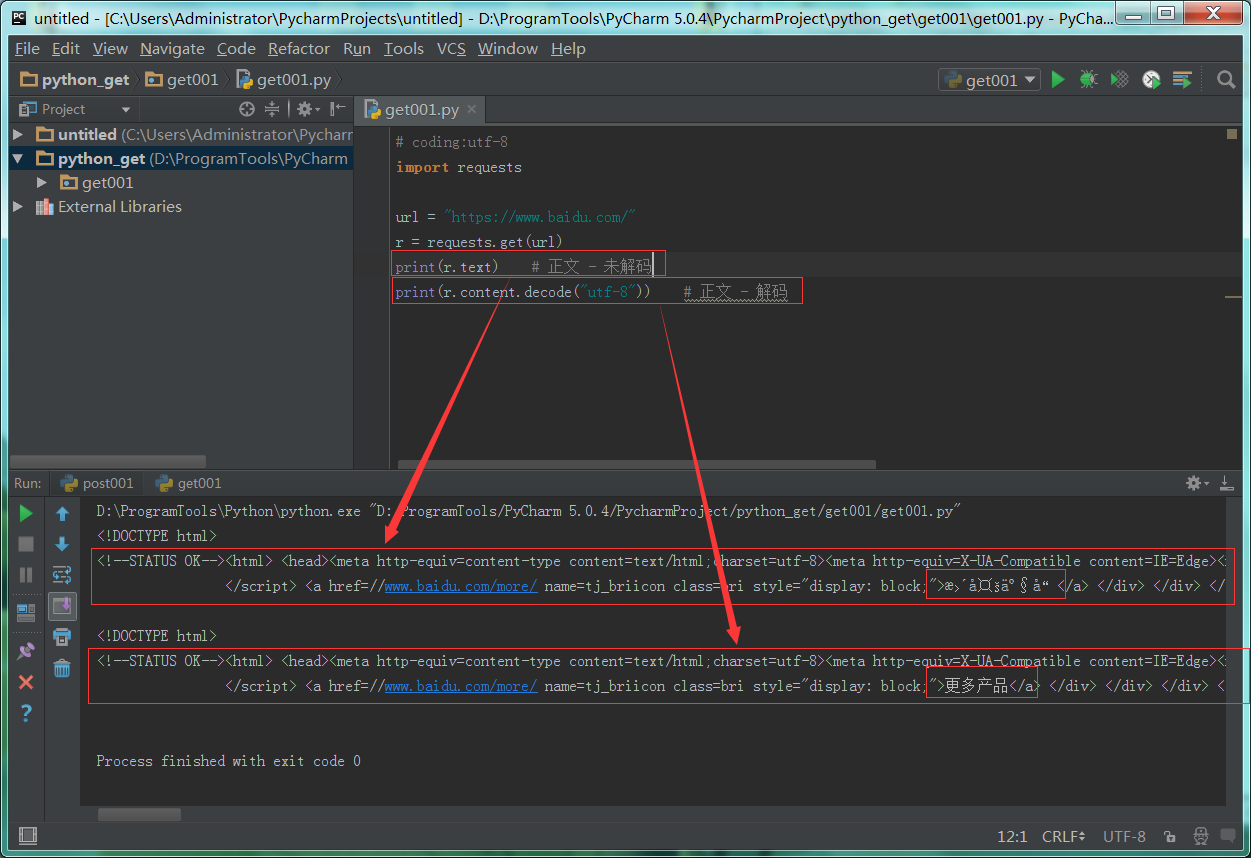
1 : python代码实现。
# coding:utf-8
import requests
url = "https://www.baidu.com/"
r = requests.get(url)
print(r.text) # 正文 - 未解码
print(r.content.decode("utf-8")) # 正文 - 解码
2 : 和fiddler解码后的一样。
三: 其他
1 详解request
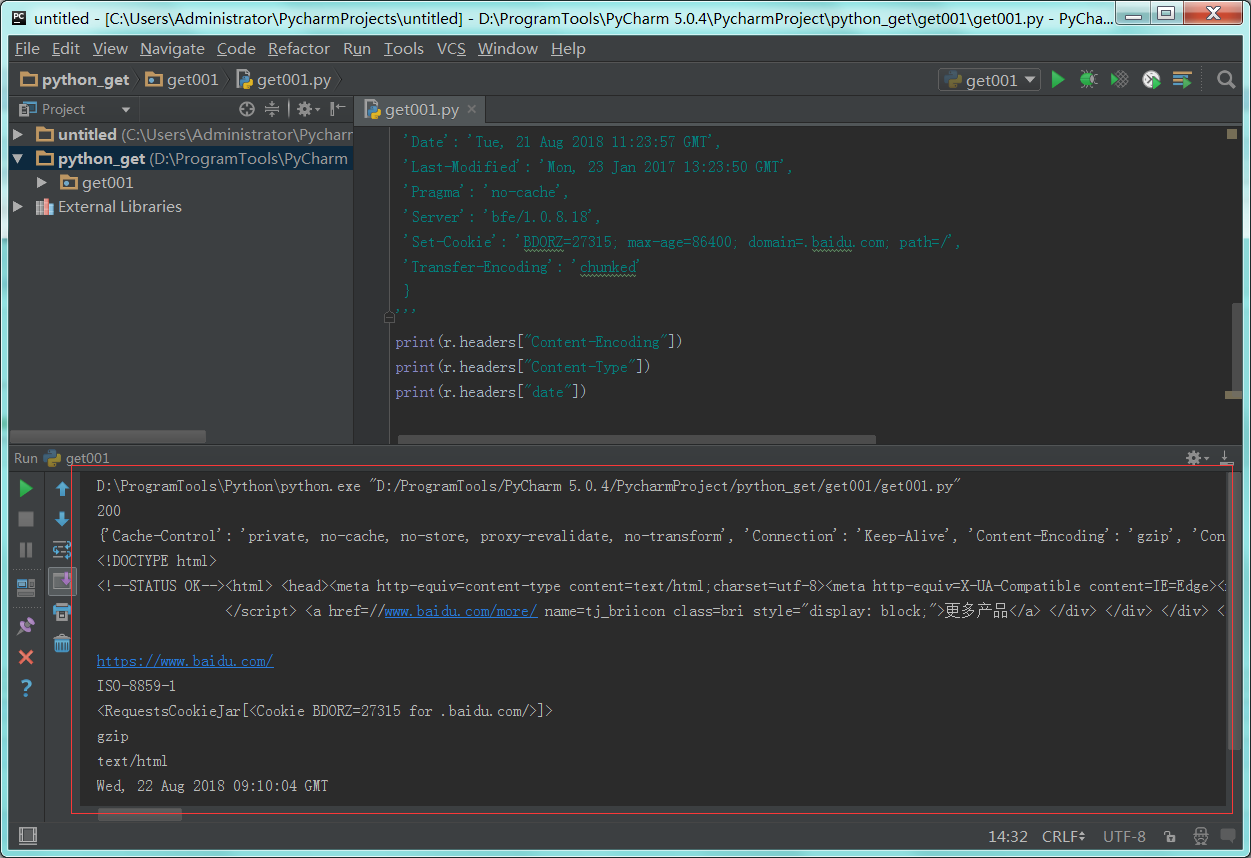
1 : python代码实现。
# coding:utf-8
import requests
url = "https://www.baidu.com/"
r = requests.get(url) # 请求地址 - 返回字典
# 主要:
print(r.status_code) # 状态码
print(r.headers) # 头部信息 - 字典存储
print(r.content.decode("utf-8")) # 正文 : r.text - 字符串
# 次要
print(r.url) # 获取url
print(r.encoding) # 编码格式
print(r.cookies) # cookie信息
'''
r.headers # 头部信息 - 字典存储
{'Cache-Control': 'private, no-cache, no-store, proxy-revalidate, no-transform',
'Connection': 'Keep-Alive',
'Content-Encoding': 'gzip',
'Content-Type': 'text/html',
'Date': 'Tue, 21 Aug 2018 11:23:57 GMT',
'Last-Modified': 'Mon, 23 Jan 2017 13:23:50 GMT',
'Pragma': 'no-cache',
'Server': 'bfe/1.0.8.18',
'Set-Cookie': 'BDORZ=27315; max-age=86400; domain=.baidu.com; path=/',
'Transfer-Encoding': 'chunked'
}
'''
print(r.headers["Content-Encoding"])
print(r.headers["Content-Type"])
print(r.headers["date"])
2 : python请求。
标准参数:
requests.get(url, params, kwargs)
requests.post(url, data, json, kwargs)
常用参数:
requests(url, params, headers, cookies, data/json, allow_redirects, verify)
2 错误提示 - SSL
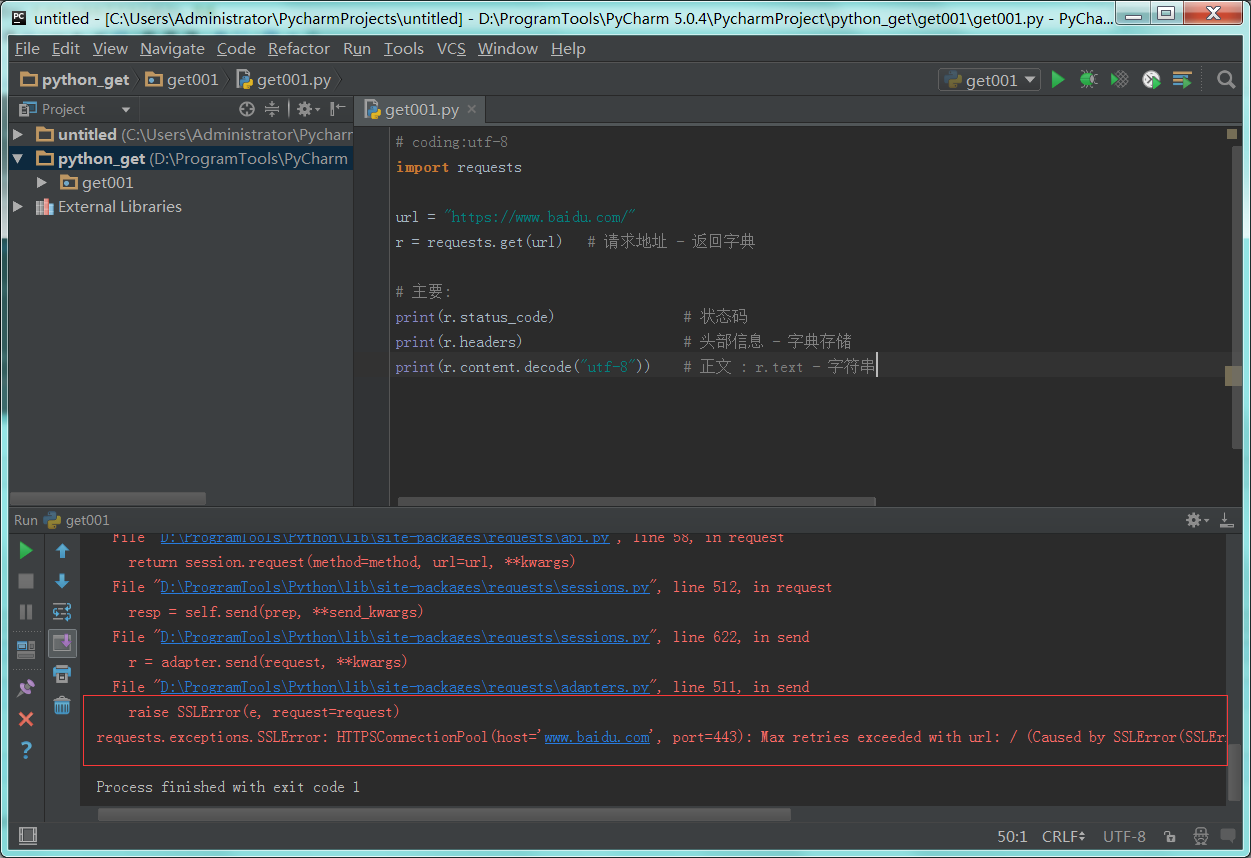
1 : python访问https协议的网站时,打开了fiddler或者其他代理,导致出错SSL。
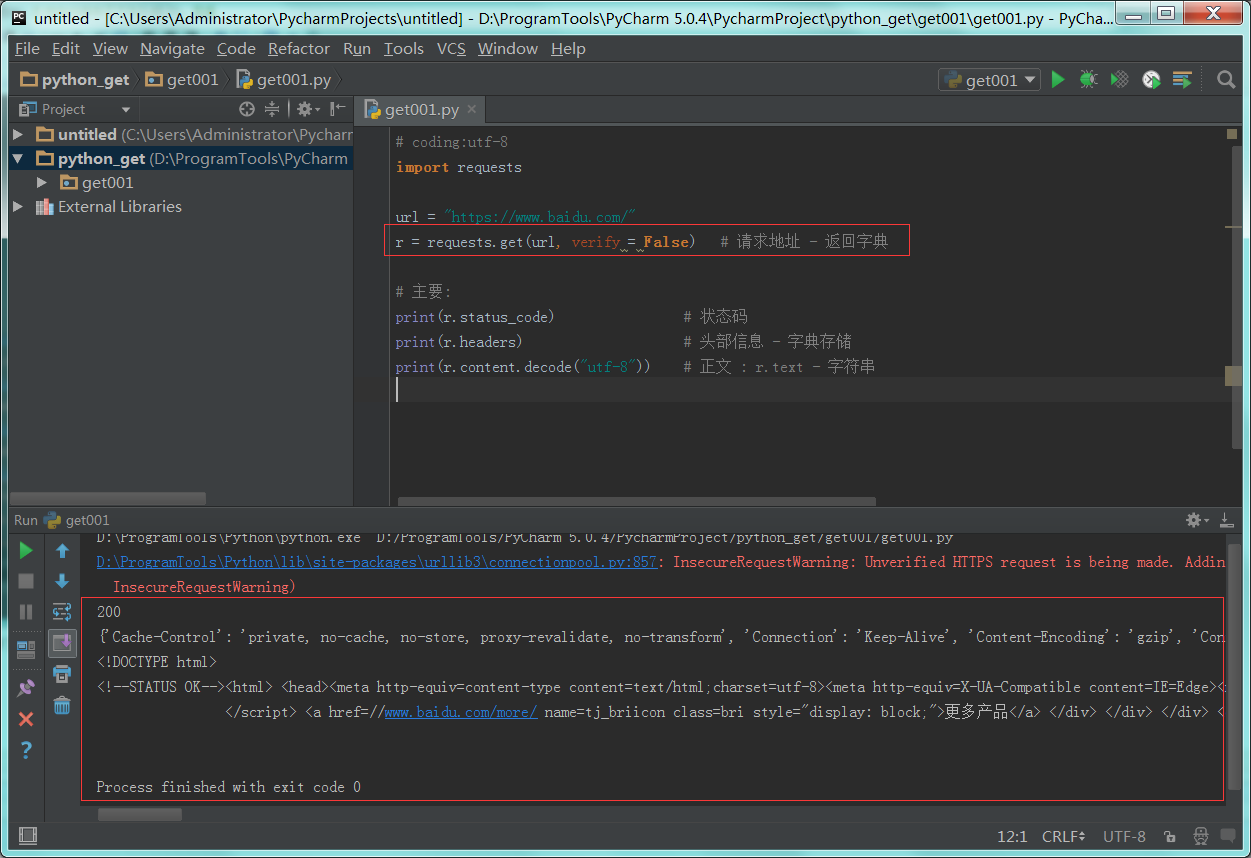
1 python代码实现。
# coding:utf-8
import requests
url = "https://www.baidu.com/"
r = requests.get(url, verify = False) # 请求地址 - 返回字典
print(r.status_code) # 状态码
print(r.headers) # 头部信息 - 字典存储
print(r.content.decode("utf-8")) # 正文 : r.text - 字符串
2 错误提示解决了,代码可以请求到服务器返回数据,只剩下警告信息。
3 警告提示
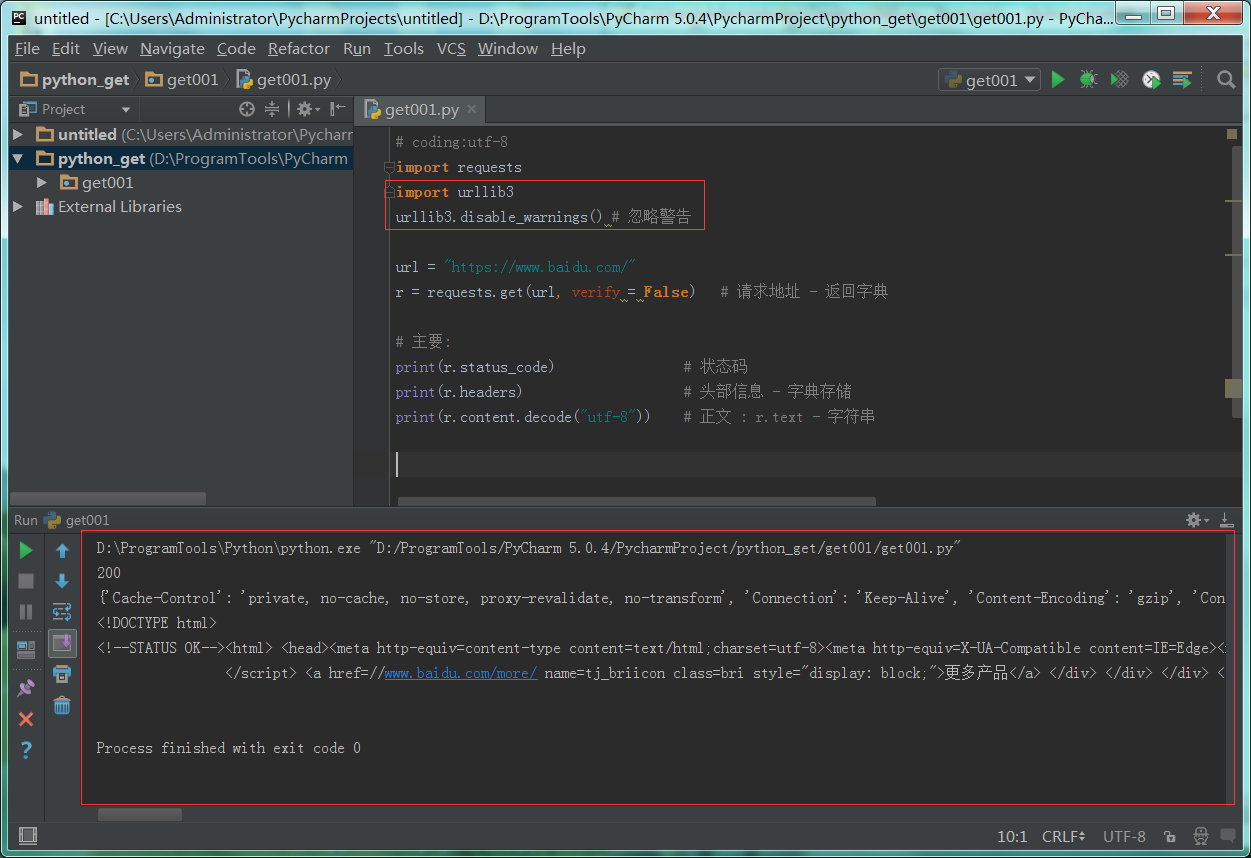
1 python代码实现。
# coding:utf-8
import requests
import urllib3
urllib3.disable_warnings() # 忽略警告
url = "https://www.baidu.com/"
r = requests.get(url, verify = False) # 请求地址 - 返回字典
print(r.status_code) # 状态码
print(r.headers) # 头部信息 - 字典存储
print(r.content.decode("utf-8")) # 正文 : r.text - 字符串
2 错误信息和警告信息全部都解决了。