第二章
程序的两大任务:描述数据与处理数据。
数据可以看做是对现实世界的各个事物的抽象;对数据的处理就反应了事物的变化,表达了事物之间的关系。对数据处理的抽象,人们称为算法。

iostream 中的输入和输出的意思:
- 输入:数据从外部(包括键盘输入或外部文件)流到程序。有类istream;ifstream
- 输出:数据从程序流动到外部。有类ostream;ofstream
插入符:“<<”;提取符:“>>”
C++中的约定成俗:
- 变量加前缀 s_ ,表示静态(static)变量;变量加前缀 g_ ,表示全局(global)变量;类的数据成员加前缀 m_ ,表示成员(member)变量。
- 常量大写。例如:const int MAX_LENGTH = 100;
字符串类型
3.5.1 字符类型
- char 1个字节(8位或8bit) 范围:-128~127
- signed char 与 char 一样
- unsigned char 1个字节(8位或8bit) 范围:0~255
- wchar_t 2个字节(16位) 为了表示unicode字符
3.7 枚举类型
列出它的所有可能值。枚举类型实质上是整型数值;默认是0,1,2...,也可以指定。
enum Weekday{mon = 1, tue, wed, thu, fri, sat, sun = 0 };//从mon开始,没有指定值的依次加1,最后sun=0
Weekday nDay(tue);//也可以用nDay=tue;初始化
cout << nDay;
结果:2
但,不能用整数给枚举类型变量赋值。枚举类型的数值是常量,定义后不可改变。(不可做lvalue)
最佳实践:不要使用“==”比较两个浮点数是否相等。要用如下方法:
float x = 0.0005;
double y = 0.0005;
//设定允许的误差值
const double fEpsion = 0.00001;
//如果相减的结果,比一极小值还小,则认为相等。
if(fabs(x - y) < fEpsion)
cout << "x等于y" << endl;
else
cout<< "x不等于y" << endl;
const 表示常量:
int* const pNumber = &number;//const在“*”的右边,则表示const修饰的是指针,这个指针的值在声明后不能修改,所以声明时必须赋初值。声明一个整型常量指针 const int* pNumber; // const在“*”的左边,则表示const修饰的是int,这个指针指向的值不能修改。——常量整型指针 int const * pNumber; // 声明一个常量整型指针,意义同上 const int* const pNumber = &number; // 声明一个常量整型常量指针,指针和指针指向的变量值都不能修改。
类的成员函数中的const:
const Stock & Stock::topval (const Stock & s) const
{
if (s.toltal_val > total_val)
return s;
else
return *this;
}
在这个成员函数中,Stock是之前定义的一个类,下面我们介绍每个const的含义。
①const Stock & Stock::topval (②const Stock & s) ③const
我们把三处const分别用序号①②③分别表示,分别讲解。
①处const:确保返回的Stock对象在以后的使用中不能被修改
②处const:确保此方法不修改传递的参数 S
③处const:保证此方法不修改调用它的对象(保证不修改类中的数据成员;函数体中不能调用非const函数)
1.如果函数有返回值,则不可返回一个指向函数体内部声明的局部对象的“指针”或“引用”。
2.简单地用断言(assert)检查参数的有效性。
assert(expression) 的作用是现计算表达式 expression ,如果其值为假(即为0),那么它先向stderr打印一条出错信息,然后通过调用 abort 来终止程序运行
#include <assert.h> //插入断言头文件
using namespace std;
double Divide(int nDivident, int nDivisor)
{
assert(0 != nDivisor); //使用断言判断除数是否为0
return (double)nDivident / nDivisor;
}
int main()
{
double fRet = Divide(3, 0);
return 0;
}
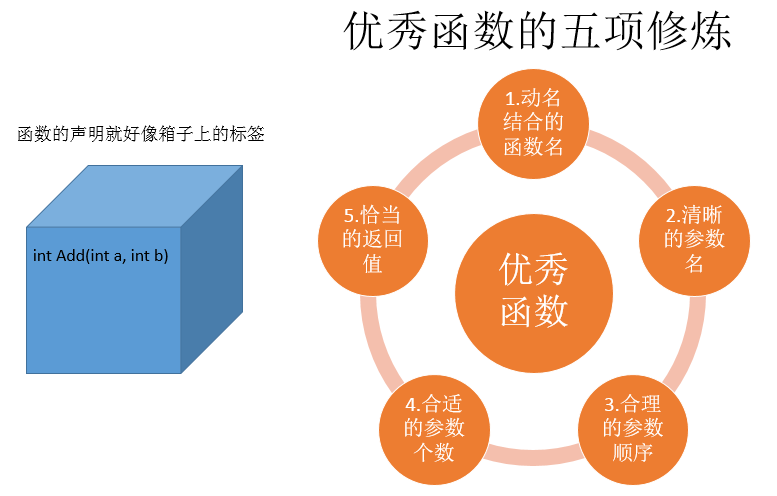
3.函数的功能要单一。
4.函数主体不宜太长。
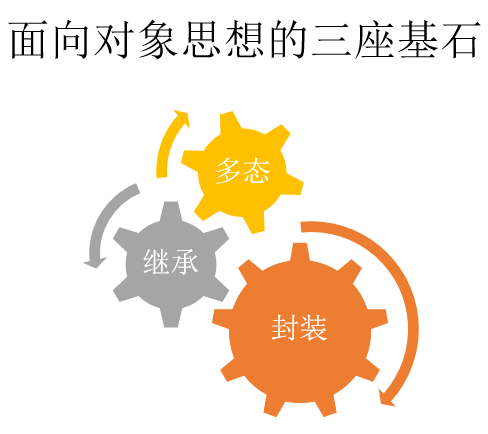
1.封装:将描述对象属性的数据和描述对象行为或功能的函数(方法)结合在一起,形成对象。——更加准确的描述了现实世界。好处:对数据进行保护,以免外部无意的修改。
2.继承:是可以让某个对象获得另一个类型的对象的属性和方法。好处:代码的重复利用,更方便的维护,更易扩展。
3.多态:相同的调用语句,具有不同的表现形式。多态由继承而来,由虚函数virtual来实现。例如,一个父类的指针指向子类的对象,当调用某一个父类和子类都有的成员函数时,(若用virtual修饰的成员函数)则调用子类自己的成员函数(可能会有许多的子类对象)。若没virtual,则调用父类的方法(成员函数)。
class Father
{
public:
virtual void func(){cout << "调用father的func" << endl;}
};
class Son : public Father
{
public:
void func(){cout << "调用Son的func" << endl;}
};
int main()
{
Son son;
Father *ptrFuther = &son;
ptrFuther->func(); //若Father类中的func函数有virtual修饰,结果为:"调用Son的func"
return 0; //若Father类中的func函数没有virtual修饰,结果为:"调用father的func"
}
基类的成员在派生类中的访问属性:
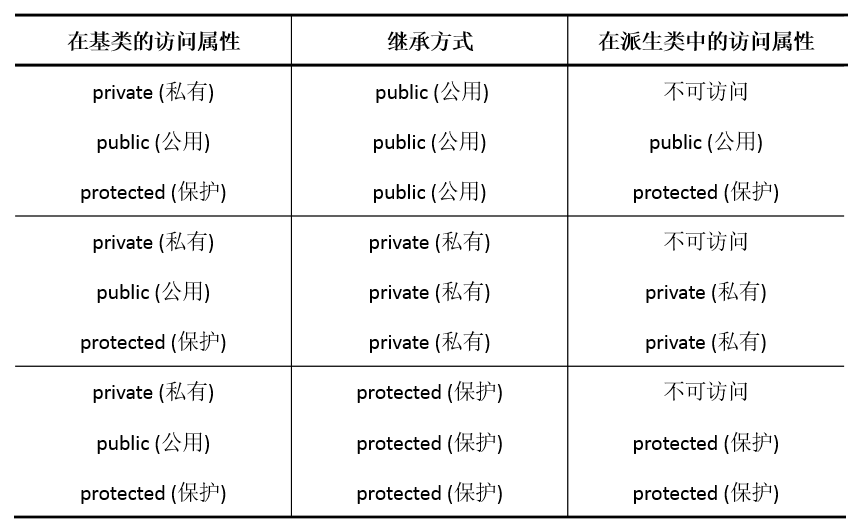
可访问性:private < protected < public.
private:只有自己能访问,子类和外部均不可以访问。
protected:自己和自己的子类可以访问,外部不可访问。
public:自己,自己的子类,外部均可以访问。
子类会继承父类全部的成员,继承后子类对父类的成员的访问权限:①原来private升级为不可访问。②在原来的访问属性与继承方式中取可访问性更小的。
子类不可访问父类的所有private;子类可以访问自己的private,protected,public;
操作符重载:
class 类名
{
public:
返回值类型 operator 操作符 (参数列表)
{
...
}
};
a + b; 这条语句相当于 a.operator + (b);
1.友元函数:
class 类名
{
friend 返回值类型 函数名(形式参数) ; // 友元函数的声明
//类的其他声明和定义...
};
返回值类型 函数名(形式参数) // 友元函数的定义
{
... //可以访问private,protected,public
}
友元函数的定义在类的外部,不属于类的成员函数,故其声明既可以在private:,也可以在public:,...,没有区别的。一般单独放。
2.友元类:
class 类名
{
friend class 友元类名;
// 类的其他声明和定义
}
这样声明后,在友元类中就可以不受类成员访问控制的限制。
class Teacher
{
friend class TaxationDep;
friend int AdjustSalary(Teacher& teacher);
public:
Teacher():m_nSalary(5000){} //直接定义,隐式的inline函数
private:
int m_nSalary ;
};
//友元函数
int AdjustSalary(Teacher& teacher)
{
return teacher.m_nSalary + 299;
}
//友元类
class TaxationDep
{
public:
int CheckSalary(Teacher& teacher)
{
return teacher.m_nSalary;
}
};
int main()
{
Teacher MrChen;
TaxationDep taxOfficial;
int nSalary = taxOfficial.CheckSalary(MrChen);
cout << nSalary << endl;
cout << AdjustSalary(MrChen) << endl;
return 0;
}
//结果 5000
// 5229
函数指针:
函数指针的声明:
函数返回值类型标志符 (指针变量名)(形参列表);
譬如:
-
void (*pPrintFunc)(int nScore);//注意:第一个"()"不可以省略。
-
void (*pPrintFunc)(int);
- typedef void (*PRINTFUNC)(int ); // 如果要定义多个同一类性的指针,还可以用typedef关键字定义一种新的函数指针类型。此句表示定义一种新的函数指针类型PRINTFUNC,它可以指向一个参数为int、返回值为void的函数。用这个类型可以连续定义多个函数指针。
PRINTFUNC pFuncFailed;
PRINTFUNC pFuncPass; ...
- auto pPrintFunc = printPass; //C++11后,auto定义的类型,编译器会在变量赋值的时候,自动推断类型。必须初始化。
函数名就是指向函数的指针,即函数入口的地址。把函数名赋值给函数指针变量即可。
void printPass(int nScore) //函数名就是指向函数的指针,即函数入口的地址。
{
cout << "分数是:" << nScore << ",恭喜你通过考试!" << endl;
}
int main()
{
int nScore = 72;
// 函数指针的声明,本质上就是定义一个指针(像int* p;),只是它指向一个函数。另外,C++11后,可用 auto pPrintFunc = printPass; 代替下面的两行语句。
void (*pPrintFunc)(int nScore);//可以写成省略形式:void (*pPrintFunc)(int );
pPrintFunc = printPass; //用函数名给函数指针赋值
(*pPrintFunc)(nScore); //用函数指针调用函数,实际调用printPass(nScore)
return 0;
}
既然,调用函数指针与函数的调用没什么差别,那么何必使用函数指针呢?但普通函数的调用不够灵活。指针的灵魂就是它的灵活性。
譬如
void printPass(int nScore) //函数名就是指向函数的指针,即函数入口的地址。
{
cout << "分数是:" << nScore << ",恭喜你通过考试!" << endl;
}
void printFailed(int nScore)
{
cout << "分数是:" << nScore << ",抱歉,你没有通过考试!" << endl;
}
void printExcellent(int nScore)
{
cout << "分数是:" << nScore << ",哇,你是个天才!" << endl;
}
int main()
{
int nScore = 172;
void (*pPrintFunc)(int );
if(nScore < 60)
pPrintFunc = printFailed;
else if(nScore >= 60 && nScore < 100)
pPrintFunc = printPass;
else
pPrintFunc = printExcellent;
//因为函数指针被不同的函数入口地址赋值,从而实现了不同函数的调用。
(*pPrintFunc)(nScore); //用函数指针调用函数
return 0;
}
11.1.3 用函数指针实现回调函数
除了可以使用函数指针简化函数的调用之外,函数指针更大的用途在于它可以作为函数参数传递给某个函数,从而实现函数的回调。譬如:
#include <iostream>
using namespace std;
void printPass(int nScore) //函数名就是指向函数的指针,即函数入口的地址。
{
cout << "分数是:" << nScore << ",恭喜你通过考试!" << endl;
}
void printFailed(int nScore)
{
cout << "分数是:" << nScore << ",抱歉,你没有通过考试!" << endl;
}
void printExcellent(int nScore)
{
cout << "分数是:" << nScore << ",哇,你是个天才!" << endl;
}
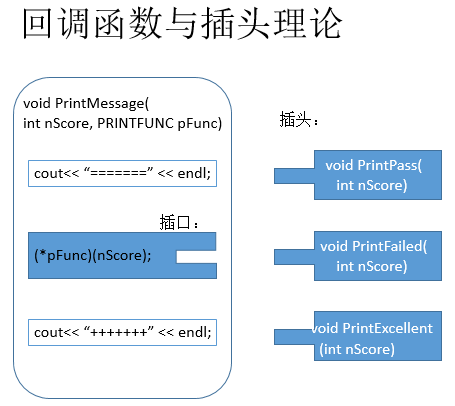
typedef void (*PRINTFUNC)(int );//定义函数指针类型
void printMessage(int nScore, PRINTFUNC pFunc)
{
cout << "================" << endl;
//通过函数指针回调函数
(*pFunc)(nScore); //这里就像留下一个插口,等待具体的回调函数插头的插入。插口的规则由PRINTFUNC类型规定。
cout << "++++++++++++++++" << endl;
}
int main()
{
int nScore = 72;
PRINTFUNC pFunc;
if(nScore < 60)
pFunc = printFailed;
else if(nScore >= 60 && nScore < 100)
pFunc = printPass;
else
pFunc = printExcellent;
printMessage(nScore, pFunc);//使用不同的函数指针作为参数调用PrintMessage()函数。
return 0;
}
11.1.4 将函数指针应用到STL算法中
class Student
{
public:
Student(int height):m_nHeight(height)
{
}
int getHeight()
{
return m_nHeight;
}
private:
int m_nHeight;
};
bool countHeight(Student stu)
{
return(stu.getHeight() > 170);
}
int main()
{
Student student1(163);
Student student2(172);
Student student3(175);
vector<Student> vecStu;
vecStu.push_back(student1);
vecStu.push_back(student2);
vecStu.push_back(student3);
//这样,满足countHeight函数条件的进行统计。count_if(begin, end, p)表示:在迭代器[begin, end)中调用if(p(*begin))res++;
int nCount = count_if(vecStu.begin(), vecStu.end(), countHeight );
cout << "身高大于170的学生有:" << nCount << endl;
return 0;
}//结果:身高大于170的学生有:2
为了增加灵活性,把身高标准也作为函数参数。
bool countHeight(int nHeight, Student stu)
{
return(stu.getHeight() > nHeight);
}
然后,这样调用 count_if() 函数(头文件algorithm中)
int nStandardHeight = 170;//定义标准高度 int nCount = count_if(vecStu.begin(), vecStu.end(), bind1st(ptr_fun(countHeight), nStandardHeight) ); //在这里,首先使用 ptr_fun() 函数将一个普通的函数指针转换为一个函数对象, //然后用 bind1st() 函数将整个函数对象的第一个参数绑定为 nStandardHeight ,而第二个参数就是容器中的 Student 对象,即*begin。
除了可以在STL算法中使用指向普通函数指针外,还可以在算法中使用指向某个类的成员函数的函数指针。譬如,用调用成员函数的函数指针的方法来实现上面的例子。
#include <iostream>
#include <vector>
#include <algorithm>//声明 count_if()函数
using namespace std;
class Student
{
public:
Student(int height):m_nHeight(height)
{
}
bool countHeight(int nHeight)
{
return(m_nHeight > nHeight);
}
private:
int m_nHeight;
};
int main()
{
Student student1(163);
Student student2(172);
Student student3(175);
vector<Student> vecStu;
vecStu.push_back(student1);
vecStu.push_back(student2);
vecStu.push_back(student3);
int nStandardHeight = 170;//定义标准高度
int nCount = count_if(vecStu.begin(), vecStu.end(), bind2nd(mem_fun_ref(&Student::countHeight), nStandardHeight) );
cout << "身高大于170的学生有:" << nCount << endl;
return 0;
}
这里,首先使用“&”运算符获得 Student 类的成员函数 countHeight() 的地址,即指向成员函数的函数指针;然后用mem_fun_ref() 函数将这个函数指针构造成一个函数对象。使用 bind2nd() 函数绑定其第二个参数为nStandardHeight,因为成员函数的隐含默认第一个参数为对象本身,*this
如果容器中保存的是指向对象的指针,就应该用 mem_fun() 函数来完成 bind2nd() 这一语句。
...//同上
int main()
{
Student student1(163);
Student student2(172);
Student student3(175);
vector<Student*> vecStu;
vecStu.push_back(&student1);
vecStu.push_back(&student2);
vecStu.push_back(&student3);
int nStandardHeight = 170;//定义标准高度
int nCount = count_if(vecStu.begin(), vecStu.end(), bind2nd(mem_fun(&Student::countHeight), nStandardHeight) );//此处用mem_fun()来完成
cout << "身高大于170的学生有:" << nCount << endl;
return 0;
}
总的来说,vector 里放对象用 mem_fun_ref(),vector里放指针用 mem_fun() 。
11.2 函数对象
所谓函数对象,就是定义了函数调用操作符【(function-call operator),即operator() 】 的普通类的对象。简单说,就是重载"()" 的类的对象。
// 类模板
template <class T>
class mymax
{
public:
//重载“()”操作符
T operator() (T a, T b)
{
return a>b ? a:b;
}
};
int main()
{
mymax<int> intmax; // 由 模板类 产生 函数对象
int nMax = intmax(3, 4); // 与函数调用极其相似,编译器将 intmax(3,4); 转换为 intmax.operator()(3,4);
cout << nMax << endl; // 4
return 0;
}
11.2.2 利用函数对象记住状态数据
for_each 的实现:
template<class InputIt, class UnaryFunction>
UnaryFunction for_each(InputIt first, InputIt last, UnaryFunction f)
{
for (; first != last; ++first) {
f(*first);
}
return f;
}
譬如:
class Student
{
public:
Student(string name=0, int height=0) : m_strName(name), m_nHeight(height) {}
int GetHeight(){return m_nHeight;}
private:
string m_strName;
int m_nHeight;
};
//定义一个函数对象类
class AverageHeight
{
public:
AverageHeight() : m_nCount(0), m_nTotalHeight(0) {}
//重载"()"操作符
void operator() (Student st)
{
m_nTotalHeight += st.GetHeight();
++m_nCount;
}
//接口函数
float GetAverageHeight()
{
if(0 != m_nCount)
{
return (float)GetTotal() / GetCount();
}
else
return -1;
}
//获取函数对象类的各个成员属性
int GetCount(){return m_nCount;}
int GetTotal(){return m_nTotalHeight;}
//定义类型转换函数
/*
类型转换函数的一般形式为 :
operator 类型名()
{实现转换的语句}
*/
operator float(){return GetAverageHeight();}//可以将Student类型转换为float类型
private:
int m_nCount;
int m_nTotalHeight;
};
int main()
{
Student st1("Lee", 165);
Student st2("Wang", 168);
Student st3("Hou", 171);
vector<Student> vecStu = {st1,st2,st3};
//创建函数对象
AverageHeight ah;
//将函数对象应用到STL算法中
ah = for_each(vecStu.begin(), vecStu.end(), ah);
cout << ah.GetCount() << "个学生的平均身高是:" << ah.GetAverageHeight() << endl; // 168
//若定义类型转换函数,就可以将Student ——> float
float average = for_each(vecStu.begin(), vecStu.end(), ah);
cout << average << endl; // 168
return 0;
}
11.3 Lambda 表达式
在作用上,Lambda 表达式类似于函数指针和函数对象。譬如,上面的例子不用函数对象,而用 Lambda 表达式 则更简单。
int main()
{
Student st1("Lee", 165);
Student st2("Wang", 168);
Student st3("Hou", 171);
vector<Student> vecStu = {st1,st2,st3};
//定义变量,以保存状态数据
int nTotalHeight = 0;
int nCount = 0;
//将 Lambda表达式 应用到STL算法中
for_each(vecStu.begin(), vecStu.end(), [&](Student st){nTotalHeight += st.GetHeight();++nCount;});
cout << nCount << "个学生的平均身高是:" << (float)nTotalHeight / nCount << endl; // 168
return 0;
}
- Lambda 表达式的语法规则
[ 变量使用说明符 ] ( 参数列表 ) -> 返回值数据类型
{
// 函数体
}
其中,高亮部分可选。中括号 "[ ]" 表示 Lambda 表达式的开始。"[=]" 表示传值(复制)方式,它使得Lambda表达式以只读的方式访问当前作用域的变量。"[ ]" 表示默认方式,也是传值方式。"[&]" 表示以引用的方式定义Lambda表达式,它使得Lambda表达式的变量是外部同名变量的引用,即可以修改外部变量。
vector<int> v = {0,1,2,3};
int nAdd = 3;
for_each(v.begin(), v.end(),
[=](int x) // [=] 传值方式,但是"[]"方式会出错,不知为什么?
{
//nAdd = 2; // 试图修改nAdd,编译错误
x += nAdd; //只读访问nAdd
cout << x << " "; // 3 4 5 6
});
vector<int> v = {0,1,2,3};
int nAdd = 3;
for_each(v.begin(), v.end(),
[&](int x) // [&] 引用方式
{
nAdd = 2; // 引用方式可以修改外部变量nAdd,编译OK
x += nAdd;
cout << x << " "; // 2 3 4 5
});
cout << endl << nAdd << endl; // 2 可以看到 nAdd 变了,即实现了向外部传递数据的功能。
如果需要与Lambda表达式传递多个数据,那么可以在"[ ]" 的第一位设置一个默认的传递方式,然后再分别指定各个变量的传递方式。譬如
vector<int> v = {0,1,2,3};
int nAdd = 3;
int nTotal = 0;
for_each(v.begin(), v.end(),
[&, nAdd](int x) // 默认情况子下使用引用方式,nAdd使用传值方式
{
nTotal += (x*nAdd); //只读访问nAdd
});
cout << "容器中的数据乘以" << nAdd << "之后总和是" << nTotal << endl;
通常来说,Lambda 表达式没有返回值,这时可以省略返回值类型的定义,若某些算法需要它有返回值,则用“->”来定义返回值类型。譬如
vector<int> v = {0,1,2,3,};
int nEven = count_if(v.begin(), v.end(),
[=](int x) -> bool // 也可以 [](int x) 或者 [](int x) -> bool 都行
{
return x%2==0;
});
cout << nEven << endl; // 2
11.3.3 Lambda 表达式的复用
vector<int> v = {0,1,2,3,};
list<int> l = {2, 4, 6 ,8};
l.push_back(10);
//定义一个可以输出整数的Lambda表达式
auto show = [](int x)
{
cout << x << endl;
}; //注意有";"
//在vector容器上应用
for_each(v.begin(), v.end(), show);
//在list容器上应用
for_each(l.begin(), l.end(), show);
12.1 右值
左值:可以放在“=”的左边,即能被赋值也能对其他左值赋值。对左值的引用:“&”
右值:只能放在“=”的右边,给左值赋值。通常是一些数值常量、临时变量或无名变量等,例如一个函数的返回值。对右值的引用:“&&”
//这个函数返回值就是右值
int creatInt(int x)
{
return x;
}
int main()
{
int i;// 定义一个int类型变量,这个变量就是左值
//定义一个左值引用,左值引用只能绑定左值
int& lrefInt = i;
//定义一个右值引用,右值引用只能绑定右值(临时对象)
int&& rrefInt = creatInt(4);
//左值引用与右值引用的使用没有区别,都可以当成普通数据类型变量
rrefInt = 1;
lrefInt = rrefInt;
return 0;
}
实际上,右值就是一些无名的数据变量。
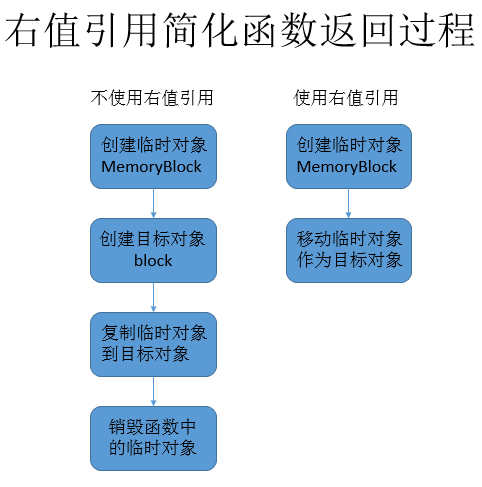
右值引用在函数返回值上的应用。
//利用函数创建并返回一个类的对象
MemoryBlock CreateBlock(size_t nSize)
{
return MemoryBlock(nSize);
}
//利用返回值对变量进行赋值
MemoryBlock block = CreateBlock(703);
MemoryBlock&& block2 = CreateBlock(703);
12.2 智能指针 shared_ptr
#include <iostream>
#include <memory>//声明shared_ptr
using namespace std;
int main()
{
shared_ptr<int> pFirst(new int);
//这时,只有一个指针指向这块int类型的内存,所以这时的引用计数是1。
cout<< "当前引用计数:" << pFirst.use_count() << endl;
{
//创建另一个shared_ptr,并用pFirst对其赋值,让它们指向同一块内存资源
shared_ptr<int> pCopy = pFirst;
//这时,引用计数是2,pCopy.use_count()也是2
cout << "当前引用计数:" << pFirst.use_count() << endl;
}
//pCopy的生命周期结束,引用计数减1
cout<< "当前引用计数:" << pFirst.use_count() << endl;
//当程序结束执行返回,pFirst指针也结束其生命周期
//这时引用计数为0,内存资源自动得到释放
return 0;
}
并不是任何时候都应该使用智能指针。
总结起来,以下情况应该优先考虑使用 share_ptr
- 有多个使用者共同使用同一对象,而没有一个明显的拥有者。
- 一个对象的复制操作很昂贵。
- 要把指针存入标准库容器。
- 要传送对象到库或从库获取对象,而这些对象没有明确的所有权。
- 当管理需要特殊清理方式的资源时,这时可以通过定制shared_ptr 的删除器来实现。
#include <iostream>
#include <memory>//声明shared_ptr
using namespace std;
class Employee
{
public:
Employee(string strName) : m_strName(strName){}
string GetName(){return m_strName;}
private:
string m_strName;
};
class PrintEng
{
public:
PrintEng(shared_ptr<Employee> sp) : m_spEmp(sp) {}
void doPrint()
{
if(true == (bool)m_spEmp)
cout << "Name of Employee: " << m_spEmp->GetName() << endl;
}
private:
shared_ptr<Employee> m_spEmp;
};
class PrintChs
{
public:
PrintChs(shared_ptr<Employee> sp) : m_spEmp(sp) {}
void doPrint()
{
if(true == (bool)m_spEmp)
cout << "员工的姓名:" << m_spEmp->GetName() << endl;
}
private:
shared_ptr<Employee> m_spEmp;
};
int main()
{
shared_ptr<Employee> spEmp(new Employee("JiaWei"));
//将智能指针spEmp共享给pEng对象
PrintEng pEng(spEmp);
pEng.doPrint();
//将智能指针spEmp共享给pChs对象
PrintChs pChs(spEmp);
pChs.doPrint();
//不用自己释放内存空间,智能指针帮忙释放了。
return 0;
}
瘦身版的智能指针 —— unique_ptr
由于shared_ptr指针需要40字节的内存,体积较大。故有 unique_ptr,当 unique_ptr 销毁时,同样会自动释放它所管理的内存空间。与 shared_ptr 不同的是,某个内存资源只允许一个 unique_ptr 与之关联,对其进行管理。也就是说 unique_ptr 不能进行复制。
//定义一个unique_ptr,并将其与一个Employee对象关联 unique_ptr<Employee> upEmployee(new Employee); //使用 -> int nAge = upEmployee->GetAge(); //使用 * PrintObj(*upEmployee);
13.1.2 函数
题8 请编写一个函数将一个链表翻转。例如,现在有一链表1->2->3->4->5,通过调用函数将链表翻转成为5->4->3->2->1。
Student* reverseList(Student* head)
{
if(NULL == head) //对当前的参数有效性进行验证
return head;
Student *pre, *cur, *next; //定义前一节点、当前节点、后一节点
pre = head;
cur = pre->next;
while(cur)
{
next = cur->next;
cur->next = pre;
pre = cur;
cur = next;
}
head->next = NULL;
head = pre;
return head;
}
或者,用指针的引用
struct link
{
int data;
link* next;
};
//反转链表函数
void reverseList(link* &head)
{
if(NULL == head)
return ;
Student *pre, *cur, *next;
pre = head;
cur = pre->next;
while(cur)
{
next = cur->next;
cur->next = pre;
pre = cur;
cur = next;
}
head->next = NULL;
head = pre;
}

题 9 请编写一个字符串拷贝函数
//糟糕的
void strcpy( char* strDest, char* strSrc )
{
while( (*strDest++ = *strSrc++) != '�' );
}
比较完美的答案:
// 为了实现链式操作,将目标地址返回
char* strcpy ( char* strDest, const char* strSrc)
{
assert( (strDest != NULL) && (strSrc != NULL) ); //断言是否为空指针
//保存目标地址
char* address = strDest;
//逐个复制字符串数组中的数据,直到字符串结束
while( (*strDest++ = *strSrc++) != '�' );
return address;
}
题 10 内联函数的意义
编译时,内联函数的代码会被插入代码流中,避免了函数的调用,从而改善了程序的性能。另外,将一个函数定义为内联函数,有些要使用inline关键字在函数名前,有些则不需要,例如直接在类定义中定义成员函数。内联函数只是给编译器一个“建议”,编译器可以采纳,也可以忽略。
13.1.3 面向对象思想
面向对象思想是开发大型的复杂的应用软件和系统的最佳方法,了解它,有助于学习和应用面向对象技术。
题 12 面向对象的三个基本特征
1. 封装:封装将客观事物抽象成类,每个类对自身的数据和方法实行访问控制,通过关键字public、protected和private 来控制外界对类成员的访问,以达到保护数据和方法的目的。
2. 继承:子类从父类继承,从而获得父类的所有属性和方法。
3. 多态:相同的调用语句,不同的表现形式。由虚函数来实现,简单说,允许子类指针赋值给父类指针,并且用指向子类对象的父类指针可调用子类自己的函数。
题 13 何时该使用继承
当某个事物是另一个事物的“一种”时(即 is-a 关系),就应该使用继承。
题 14 类是什么?对象又是什么?
类是对现实世界中同一类物体的抽象,它是概念、规范。它包括成员变量和成员函数(即属性和方法)。
对象是类的实例化,是具体的。例如,int i,i 就是 int 类型的对象。
题 15 简述struct 与 class 的区别
在语法上,struct 与 class 的唯一区别就是默认访问权限。struct 默认成员是公有的,默认继承方式是公有;而class 默认成员是私有的,默认继承也是私有的。一般来说,当类有很少是方法并且有公有的数据时,才用struct,否则使用class。
题 16 重载(overload)和重写(override)的区别
重载:是指在同一作用域允许同时存在多个同名函数,但它们之间的函数参数表不同。另外,函数的返回类型不同,不能构成函数重载。const 限定参数按值传递不能构成重载,而const限定参数按指针或引用传递时,则可以构成重载。const 限定成员函数 也可构成重载。
重写(覆盖):是指子类重新定义父类的方法。其参数列表、返回类型必须与父类的一致。像重写虚函数以实现多态。注:C++中,只有对virtual函数才是重写。非virtual函数的重新定义也可以,其成为重定义或隐藏。
class Base
{
public:
//C++11允许将方法标记为final,这意味着无法在子类中重写这个方法。试图重写final()方法将导致编译器错误。
virtual void virFunc()/*final*/ //虚函数,子类中此函数默认virtual,可写可不写。
{cout << "Base virFunc()" << endl;}
void func()
{
cout << "Base func()" << endl;
}
};
class Sub : public Base
{
public:
virtual void virFunc(){cout << "Sub virFunc()" << endl;} // 基类中virFunc有virtual,故是重写或覆盖。
void func(){cout << "Sub func()" << endl;} // 基类中func无virtual,重定义
};
int main()
{
Sub a;
a.func(); // Sub func()
a.Base::func(); // Base func()
a.virFunc(); // Sub virFunc()
a.Base::virFunc(); // Base virFunc()
// 重写与重定义的区别主要在多态上
Base* p;
p = &a; //父类指针指向子类对象
p->func(); // Base func() 非虚函数调用父类的
p->virFunc(); // Sub virFunc() 虚函数调用自己的
return 0;
}
题 17 子类覆盖父类的虚函数是否不用加virtual 关键字?
virtual修饰符是会隐性继承的,子类中虚函数前virtual可加可不加,但为了增加代码的可读性,最好还是加上。
题18 能重载类的析构函数吗?
不能,在C++中,类有且只有一个析构函数。无论何时都不能传递参数给析构函数,也就无法根据参数的变化形成重载。
题19 局部对象的析构的顺序是什么?
局部对象的析构是反序的,就是说,先构造的对象,后析构。
题20 在派生类的析构函数中,需要显示的调用基类的析构函数吗?
永远不需要显示地调用析构函数,在派生类的析构函数当然也不需要。派生类的析构函数(无论是否显式定义)会自动调用基类的析构函数,并且基类的析构函数在派生类的对象析构之后调用。
题21 可以将一个派生类指针转换为它的基类指针吗?
可以。派生类是基类的一种,所以从派生类指针到基类的指针转换是非常安全的,并且始终成功。经常使用。
题22 C++中是如何实现指针的静态类型和动态绑定的?
有一个父类指针,它指向子类的对象。像 Student st; Human* pHuman = &st; ,这时,pHuman指针就有两种类型:指针的静态类型(此处是Human);它所指向的动态类型(此处是Student)。静态类型,使得编译器在编译时能够检查成员函数调用的合法性。动态绑定,在编译时成员函数的调用并不确定,而是在运行时根据指针指向的对象来确定调用哪个函数。动态绑定是虚函数所带来的C++特性之一。
题23 在C++中,如何实现接口与实现的分离?
在C++语言中,我们是通过抽象基类来实现接口与实现的分离的。我们把带有一个或多个纯虚成员函数的类称为抽象基类。它不能实例化,在子类中实现抽象基类的纯虚函数,就是将接口逐个实现。
题24 如何将自定义的类通过标准输出流对象输出?
通过重载“<<”运算符,自定义的类也可以通过标准输出流对象输出。
class Student
{
friend ostream& operator<< (ostream& o, const Student& st);
friend istream& operator>> (istream& i, Student& st);
private:
string m_strName;
};
ostream& operator<< (ostream& o, const Student& st)
{
return o << st.m_strName;
}
istream& operator>> (istream& i, Student& st)
{
return i >> st.m_strName;
}
int main()
{
Student stChen;
cin >> stChen; // Chen
cout << stChen << endl; // Chen
return 0;
}
题 25 完成自己的String类
//自己的String类
class String
{
public:
String(const char* data = NULL) ;
String(const String& str);
~String();
String& operator=(const String& str);
String& operator=(const char* str);
friend String operator+(const String& str1, const String& str2);
friend ostream& operator<< (ostream& o, const String& str);
private:
char* m_data;
};
String::String(const char* data )
{
if(NULL == data)
{
m_data = new char[1];
m_data[0] = '�';
}
else
{
m_data = new char[strlen(data) + 1];
strcpy(m_data, data);
}
}
String::String(const String& str)
{
m_data = new char [strlen(str.m_data) + 1];
strcpy(m_data, str.m_data);
}
String::~String()
{
delete[] m_data;
}
String& String::operator=(const String& str)
{
m_data = new char[strlen(str.m_data) + 1];
strcpy(m_data, str.m_data);
return *this;
}
String& String::operator=(const char* str)
{
m_data = new char[strlen(str) + 1];
strcpy(m_data, str);
return *this;
}
String operator+(const String& str1, const String& str2)
{
char* buffer = new char[ strlen(str1.m_data) + strlen(str2.m_data) +1 ];
strcpy(buffer, str1.m_data);
strcat(buffer, str2.m_data);
String newStr(buffer);
delete[] buffer;
return newStr;
}
ostream& operator<< (ostream& o, const String& str)
{
return o << str.m_data;
}
题 26 如何删除容器中的元素
typedef vector<int> IntArray;
IntArray arr;
arr.push_back(1);
arr.push_back(2);
arr.push_back(2);
arr.push_back(3);
//删除所有的数字2
//方法1:遍历
for(IntArray::iterator it = arr.begin(); it != arr.end(); ++it)
{
if(2 == *it)
{
arr.erase(it);
--it;
}
}
// 方法2:用remove() 在<algorithm>中
arr.erase(remove(arr.begin(),arr.end(),2), arr.end());
题 27 一个班级的成绩保存在vecSorce 容器中,请统计其中的及格人数。
vector<int> vecSorce = {35, 60, 65, 75, 86, 90};
int nPass = 0;
//方法1:遍历
for (auto it = vecSorce.begin(); it != vecSorce.end(); ++it)
{
if(*it >= 60)
nPass++;
}
//方法2:for_each() <algorithm>
for_each(vecSorce.begin(), vecSorce.end(),
[&](int nSorce) // []中有&,则可以修改nPass。若无,则不可以修改nPass。
{
if(nSorce >= 60)
nPass++;
});
//方法3:count_if() <algorithm>
//nPass = count_if(vecSorce.begin(), vecSorce.end(), bind2nd(std::greater<int>(), 60)); // *it > 60
nPass = count_if(vecSorce.begin(), vecSorce.end(), not1(bind1st(std::greater<int>(), 60))); // !(60 > *it)
cout << "及格人数:" << nPass << endl;
题 31 float 与 double 该如何选择
若精度要求不太高,可以用 float;若精度要求高,精度非常重要,则选择double。因为float 只保证小数点后6位的正确性;而double 可到达小数点后15位。
题 33 求下面函数的返回值
int func(int x)
{
int countx = 0;
while(x)
{
coutx ++;
x = x & (x-1);
}
return countx;
}
假定 x = 9999。
答案是:8。其实是将 x 转换为2进制数,其中含1 的个数。
题 34 写一个函数寻找整数数组中的第二大的数
int find_sec_max(int data[], int n)
{
int maxNum = data[0];
int secMax = INT_MIN;
for (int i = 1; i < n; ++i)
{
if(data[i] > maxNum)
{
secMax = maxNum;
maxNum = data[i];
}
else
{
if(data[i] > secMax && data[i] < maxNum)
{
secMax = data[i];
}
}
}
return secMax;
}
6.3.3 用虚函数实现多态
如果通过基类指针调用虚函数,那么将调用这个指针所指向的具体对象的虚函数,以此来代替基类的虚函数。
若有virtual,自己有调用自己的,自己没有调用父类的。注意:类声明外部不可以使用 virtual,即虚函数外部实现时不要带 virtual 修饰。
class Human
{
public:
//注:基类的函数是虚函数(声明前加virtual),
// 那么派生类的此函数都是虚函数。前加不加virtual都可以,一般加上。
virtual void BuyTicket()
{
cout << "人买票
";
}
virtual ~Human(){}
};
class Teacher : public Human
{
public:
void BuyTicket()
{
cout << "老师投币买票
";
}
};
class Student : public Human
{
public:
void BuyTicket()
{
cout << "学生刷卡买票
";
}
};
int main()
{
//声明一个基类的指针
Human* p = NULL;
//车上上来一位老师
p = new Teacher();
//老师买票
p->BuyTicket();
delete p;
//车上上来一位学生
p = new Student();
//学生买票
p->BuyTicket();
delete p;
p = NULL;//栓住指针以防乱指。
return 0;
}
结果: 老师投币买票
学生刷卡买票
注:若无virtual,则是
人买票
人买票
若想强制派生类定义某个函数,则可以在基类中将这个函数声明为纯虚函数,也就是基类不实现这个虚函数,它的所有实现都留给派生类来完成。
class Human
{
public:
virtual void BuyTicket() = 0;//纯虚函数
virtual ~Human(){}
};
当类中有纯虚函数时,这个类就成为了一个抽象类。不能创建抽象类的具体对象,因为有尚未完工的纯虚函数。
Human ren;//编译会出错,因为不可实例化抽象类。
若从抽象类派生某个类,那么它必须实现其中的虚函数才能成为一个实体类。否则还是抽象类。
6.5.1 C++ 类对象的内存模型
对象的第一个成员变量的地址跟整个对象的地址相同,第二个成员变量紧跟其后。对象中的成员变量是按照类声明中的顺序依次排列的。
而类的成员函数都被放在一个特殊的位置(因为同一类的所有对象的成员函数都是相同的,没有必要为每个对象配备一份),所有这个类的对象都共用这份成员函数。如下图:

另外:若类中有虚函数,那么在对象最开始的内存位置添加一个虚函数表的指针 _vfptr ,其后才是对象的成员变量内存数据。若某个类是派生类,那么它的对象内存中最开始的地方其实是基类的拷贝(包括基类的虚函数表指针和成员变量),其后才是派生类自己的成员变量数据。
6.5.2 指向自身的this指针
this指针是指向当前对象的指针。(即当前对象的地址)。每个非静态成员函数的第一个参数总是this指针(被系统隐式的传递)。
7.1.2 灵活的 void 类型和 void 类型指针
在程序中,void类型更多的是用于“修饰”和“限制”一个函数。例如:如果一个函数没有返回值,则用void作为这个函数的返回值类型;如果一个函数没有形式参数,则可用void作为其形式参数,表示这个函数不需要任何参数。
跟void类型不同,void类型指针作为指向抽象数据的指针,它可以成为两个具有特定类型指针之间相互转换的桥梁。任何其他类型的指针都可以直接赋值给void类型指针,但void类型指针必须强制类型转换为其他指针。因为“无类型”可以包容“有类型”,而“有类型”不能包容“无类型”。
int* pInt; float* pFloat; void* pVoid; pVoid = pInt; // 其他指针类型 ---》 void* 可以直接赋值 pFloat = (float*)pVoid; // void* ---》 其他指针类型要强制类型转换 //另外,C++引进了新的类型转换操作符 static_cast 。形式: static_cast<类型说明符>(表达式)。 //譬如:上面的语句可写为 pFloat = static_cast<float*>(pVoid);
当然,如果把void类型指针转换为并不是他实际指向的数据类型,其结果是不可预测的。
若函数可以接受任何类型的指针,那么应该将其参数声明为 void*。
譬如:内存复制函数: void * memcpy(void *dest, const void *src, size_t len);
7.1.4 指针在函数中的应用
- 指针作为函数参数
可以不用大量数据的拷贝,又可以对同一数据进行读/写操作。因为函数的调用者和函数都可以使用指向同一内存地址的指针。
- 指针作为函数的返回值
牢记:指针函数可以返回全新申请的内存地址;可以返回全局变量的地址;可以返回静态变量的地址,但就是不可以返回局部变量的地址。(因为函数内部声明的局部变量在函数结束后,其生命周期已结束,内存会被自动释放。)
7.3.2 名字空间
不同的名字空间下,可以有相同的函数、数据声明。定义一个名字空间的语法格式:
namespace 名字空间名
{
//名字空间内的声明与定义
} //结尾可以加';'
若没有说明在哪一个具体的名字空间,则默认在全局名字空间(又称匿名名字空间)
- 如何使用名字空间:
具体的名字空间要用 名字空间名::数据类型(类) 变量名
全局名字空间用 ::数据类型(类) 变量名
通常用 “ using namespace ” 关键字来指明编译时默认查找的名字空间。但不能与默认使用的全局名字空间中的数据类型相同。譬如:
#include <iostream>
namespace Zhangsan
{
struct Student
{
int nAge;
};
}
struct Student
{
bool bMale;
};
using namespace std; //将std空间,作为编译时默认查找的名字空间
using namespace Zhangsan; //将Zhangsan空间,作为编译时默认查找的名字空间
//注意:全局的名字空间,默认查找。
int main()
{
Student stu1; //编译错误。“'Student' is ambiguous”,由于Zhangsan空间与全局名字空间都有成员Student
::Student stu2; //Ok;使用全局名字空间的Student
Zhangsan::Student stu3; //OK;使用Zhangsan空间的Student
return 0;
}
若成员名(类名或函数名,变量名...)前不用 作用域分解符"::" ,则必须保证默认查找的名字空间们中只有一个这样的名称。否则,必须显式地使用 "::"。
- extern
若想在多个源文件中使用某个源文件定义的全局变量或函数,则在多个源文件中 extern int gTotal; extern int Add(int , int ); 来重新声明全局变量和全局函数。
使用通用算法 count_if 统计容器中大于100的元素个数
#include <iostream>
#include <vector>
#include <algorithm> //std::count_if
using namespace std; //将std空间,作为编译时默认查找的名字空间
int main()
{
vector<int> v;
for(int i = 0; i < 10; ++i)
{
v.push_back(i+93);
}
for(int& k : v)
{
cout << k << " ";
}
cout << endl;
//使用通用算法 count_if 统计容器中大于100的元素个数
int nTotal = count_if( v.begin(), v.end(), bind2nd(greater<int>(), 100));
cout << nTotal << endl;
//降序排序
sort (v.begin(), v.end(), greater<int>());
for(int& k : v)
{
cout << k << " ";
}
cout << endl;
return 0;
}
第八章 用STL优雅你的程序
STL(Standard Template Library) = algorithm + container + iterator.
8.2.1 函数模板
函数模板代表一类函数。(可理解为:产生函数的模板)
#include <iostream>
using namespace std;
//函数模板的定义
template <class T> //此处 class 与 typename 等价
T mymax(const T &a, const T &b)
{
return a > b ? a : b;
}
int main()
{
int nA = 2;
int nB = 5;
cout << mymax(nA, nB) << endl; //动态生成模板函数int mymax(int, int)
cout << mymax<int>(nA, nB) << endl; //显式调用模板函数
float fA = 2.3;
float fB = 2.5;
cout << mymax(fA, fB) << endl;//动态生成模板函数float mymax(float, float)
cout << mymax<float>(fA, fB) << endl;//显式调用模板函数
//cout << mymax("Chen", "Jia") << endl;//编译错误,因为"Chen"的类型是const char [5],而"Jia"是const char [4]。默认字符串常量后有'�'。
//cout << mymax("Che", "Jia") << endl;// 编译错误
cout << mymax<string>("Chen", "Jia") << endl;//OK,比较大小以字典顺序
return 0;
}
模板特化。有了某个特定类型的模板特化之后,当使用这一类型的模板函数时,编译器将使用特化后的模板函数,而其他类型,仍将用模板函数的普通版本。
//模板特化
template <>
string mymax(const string& a, const string& b) //参数列表把T替换,其他都要一致。
{
return a.length() > b.length() ? a : b;
}
一般
//较小值
template <class T>
inline const T& Min(const T& a, const T& b) {
return b < a ? b : a;
}
//较大值
template <class T>
inline const T& Max(const T& a, const T& b) {
return a < b ? b : a;
}
8.2.2 类模板
#include <iostream>
//#include <vector>
//#include <algorithm>
using namespace std;
//类模板的定义
template <typename T> //此处 typename 与 class 等价
class compare
{
public:
//构造函数,实际上它相当于一个函数模板
compare(T a, T b) : m_a(a),m_b(b)
{
}
//类模板中的函数都类似于函数模板
const T& Min() const // 若想用 T& ,后边加了const,前面也要加const,否则错误
{
return m_a < m_b ? m_a : m_b;
}
const T& Max() const
{
return m_a > m_b ? m_a : m_b;
}
private:
T m_a;
T m_b;
};
int main()
{
//类模板的实例化,就是类,即模板类(由类模板产生的类)
compare<int> intcompare(2,3);
cout << intcompare.Max() << " > " << intcompare.Min() << endl;
compare<string> stringcompare("A","a");
cout << stringcompare.Max() << " > " << stringcompare.Min() << endl;
return 0;
}

泛型编程(generic programming)就是一种大量应用模板来实现更好代码重用性的编程方式。
容器(container)
顺序容器:vector(向量)、list(线性表)、双向队列(deque)、队列(queue)...
关联容器:它所容纳的对象是由 {键-值} 对组成,有set(集合),map(映射)...
连续内存容器:vector
基于节点的容器:list
迭代器
C++ 语言中的指针可以看成是一种迭代器,但迭代器不仅仅是指针。
//使用迭代器循环遍历容器中的数据
for ( vector<int>::iterator it = vect1.begin(); it != vect1.end(); ++ it)
{
nTotal += (*it);
}
//注:一般使用 != 来判断是否到达循环结束位置,而不用 < ,因为在某些容器中没有定义 < 号
- 一般来说,容器可以存放普通数据,对象,也可以存放这些对象的指针。如果使用的是基于连续内存的容器(像vector),当在这些容器中插入或者删除元素时,往往会引起内存的重新分配或内存的复制移动。在这种情况下,我们优先选择保存对象的指针(因为指针的体积通常比对象的更小)。对基于节点内存的容器,一般选择保存对象。如果需要保存一些机器资源(例如,文件句柄、命名管道、套接字),那么通常选择保存对象的指针。
- 若容器里存的是 new 出来的指针,必须手动释放内存。
vector<Employee*> vecEmployee;
//对容器进行操作...
//使用完之后,释放指针所指的内存;清空容器。
for (auto it = vecEmployee.begin(); it != vecEmployee.end(); ++it)
{
delete (*it); //释放指针指向的对象
*it = NULL;
}
vecEmployee.clear(); // 清空整个容器
STL为我们引荐了一位打包专家——tuple。可以代替一些简单的结构体。
#include <iostream>
#include <vector>
#include <tuple>
using namespace std;
int main()
{
//tuple<string, unsigned int, double>已经是一个新的类型,分别表示姓名,年龄,体重
tuple<string, unsigned int, double> huChen;
//使用make_tuple()函数对huChen赋值
huChen = make_tuple("Chenliangqiao", 28, 66.3);
//或者更简单的,利用typedef为这种新的数据类型定义一个简短的类型名
typedef tuple<string, unsigned int, double> Human;
//利用tuple的构造函数为变量赋初值
Human huJia("Jiawei", 23, 56.3);
vector<Human> vecHuman;
vecHuman.push_back(huChen);
vecHuman.push_back(huJia);
//获取tuple数据变量中的数据
cout << "姓名:" << get<0>(huChen) << endl;
get<1>(huChen) ++;
cout << "年龄:" << get<1>(huChen) << endl;
cout << "体重:" << get<2>(huChen) << endl;
//用tie()函数将多个变量捆绑在一起,接受tuple数据组变量赋值
string strName;
unsigned nAge;
double fWeight;
tie(strName, nAge, fWeight) = huChen;
cout << "姓名:" << strName << endl;
cout << "年龄:" << nAge << endl;
cout << "体重:" << fWeight << endl;
return 0;
}
还有一种打包两种数据的方法——pair
//头文件:#include <utility>,但我没加依然正确,??
//pair的声明并初始化
pair<int, string> a(201610228, "lee");
cout << a.first << " " << a.second << endl;
//也可以用make_pair()函数初始化
pair<int, char> b;
b = make_pair(12720510, 'L');
cout << b.first << " " << b.second << endl;
//用复制构造函数初始化
pair<int, string> c(a);
cout << c.first << " " << c.second << endl;
//甚至,C++11之后,可以用auto
auto d = make_pair("I love ", "you!");
cout << d.first << " " << d.second << endl;
- map
#include <iostream>
#include <map>
using namespace std;
class Employee
{
public:
Employee(){}
Employee(int a, string b) : nAge(a),strName(b){}
int nAge;
string strName;
};
int main()
{
map<int, Employee> mapEmployee; //注:此处要求Employee必须有默认构造函数,即Employee(){}
Employee emp1(15, "Lee");
Employee emp2(25, "L");
//使用pair的模板类的对象,插入map容器中
mapEmployee.insert(pair<int, Employee>(1,emp1));
//或使用value_type类型实现数据的插入
mapEmployee.insert(map<int, Employee>::value_type(1, emp2));//由于键值一样,插入失败,但没有错,只是相当于没有插入。
//或使用“[]”
mapEmployee[1983] = emp1;
mapEmployee[2] =emp2;
//以上三种方法是等效的。
//因为map对所用的键进行排序,所用键必须是唯一的,必须能比较大小,对基本类型不必担心,但自定义类型就需要重载"<"运算符。
cout << mapEmployee.size() << endl;
//利用迭代器访问map容器中的数据
for ( map<int, Employee>::iterator it = mapEmployee.begin(); it != mapEmployee.end(); ++it )
{
cout << "当前员工工号是:" << it->first << endl;
cout << "姓名:" << it->second .strName << endl;
}
//定义要查找的键
int nFindKey = 3;
//使用find()函数查找键,返回指向这个键的数据对的迭代器。若无,返回末尾迭代器end()
map<int, Employee>::iterator it = mapEmployee.find(nFindKey);
if (mapEmployee.end() == it)
{
cout << "无法找到键为" << nFindKey << "的数据对。" << endl;
}
else
{
cout << "找到键为" << nFindKey << "的数据对。" << endl;
cout << "年龄:" << it->second.nAge << endl;
cout << "姓名:" << it->second.strName << endl;
}
//定义键的范围
int nFromKey = 1;
int nToKey = 1000;
//用迭代器表示起始位置和终止位置
map<int, Employee>::iterator itform = mapEmployee. lower_bound( nFromKey );//返回第一个 <= nFromKey 的迭代器
map<int, Employee>::iterator itto = mapEmployee. upper_bound( nToKey );//返回第一个 > nToKey 的迭代器,若没找到,返回last
//判断是否在正确的范围
if(mapEmployee.end() != itform && mapEmployee.end() != itto )
{
cout << "正确范围。" << endl;
}
else
{
cout << "错误范围。" << endl;
}
return 0;
}
10.3 容器元素的复制与变换
10.3.1 复制容器元素:copy() 与 copy_if()
template< class InputIt, class OutputIt >
OutputIt copy( InputIt first, InputIt last, OutputIt d_first );
template< class InputIt, class OutputIt, class UnaryPredicate >
OutputIt copy_if( InputIt first, InputIt last, OutputIt d_first, //C++11之后
UnaryPredicate pred );
实例:
vector<int> vecScoreC1 = {65, 59, 85, 92, 25,};
vector<int> vecScoreC2 = {60, 95, 46, 86, 35,};
vector<int> vecScore;
vecScore.resize(vecScoreC1.size() + vecScoreC2.size());
//将第一个容器vecScoreC1中的数据复制到vecScore中
vector<int>::iterator lastit = copy(vecScoreC1.begin(),vecScoreC1.end(), vecScore.begin());//返回复制进来的新数据的尾迭代器
//将第二个容器vectScoreC2中的数据复制到
copy(vecScoreC2.begin(), vecScoreC2.end(), lastit);
for (int& k : vecScore)
{
cout << k << " ";
}
cout << endl;
vector<int> vecScore2(10);//必须分配足够的空间,现在数组中是10个0。
auto lastit2 = copy_if(vecScoreC1.begin(), vecScoreC1.end(), vecScore2.begin(), bind2nd(greater<int>(), 60));//复制大于60的元素
copy_if(vecScoreC2.begin(), vecScoreC2.end(), lastit2, bind2nd(greater<int>(), 60));//复制大于60的元素
for (int& k : vecScore2)
{
cout << k << " ";
}
cout << endl;
- copy_backward() 函数
template< class BidirIt1, class BidirIt2 >
BidirIt2 copy_backward( BidirIt1 first, BidirIt1 last, BidirIt2 d_last );
//从 [first, last) 中的最后一个元素开始拷贝到指定位置d_last,依次往前放。返回最后复制的元素的迭代器。
//个人理解:把 [first, last) 的元素(顺序不变地)复制到指定末尾元素位置的地方。返回整个复制块的头迭代器。
// 像 将{65, 59, 85, 92, 25} copy_backward 到 {0,0,0,0,0,0,0,0,0,0} 的end()位置 ----> {0,0,0,0,0,65, 59, 85, 92, 25} 返回的迭代器指向65
譬如:
vector<int> vecScoreC1 = {65, 59, 85, 92, 25,};
vector<int> vecScore(10);
//copy_backward()从最后一个元素开始拷贝到指定位置往前放
vector<int>::iterator lastit = copy_backward(vecScoreC1.begin(),vecScoreC1.end(), vecScore.end());//返回复制进来的最后元素的迭代器,即指向65的迭代器
cout << *lastit << endl; // 65
copy(vecScore.begin(),vecScore.end(),ostream_iterator<int>(cout," "));//在<iterator>头文件中,相当于cout<<...
cout << endl;
// 0 0 0 0 0 65 59 85 92 25
10.3.2 合并容器元素:merge()
template <class InputIterator1, class InputIterrator2, class OutputIterator>
OutputIterator merge ( InputIterator1 first1, InputIterator1 last1,
InputIterator2 first2, InputIterator2 last2,
OutputIterator result );//默认从小到大,若想从大到小,最后加一个参数 comp 比较函数。
// 将两个容器的范围 [first1, last1), [first2, last2),而result表示合并到目标容器的起始位置。使用 merge() 可以将两个排序后的容器合并成一个新的有序容器。返回尾迭代器。
使用方法:
升序:
vector<int> vecScoreC1 = {65, 59, 85, 92, 25,};
vector<int> vecScoreC2 = {5, 9, 75, 2, -2,};
//使用 merge() 进行合并之前,必须先使用 sort() 对两个容器排序。
vector<int> vecScore;
vecScore.resize(vecScoreC1.size() + vecScoreC2.size());//分配足够的空间
sort(vecScoreC1.begin(), vecScoreC1.end());
sort(vecScoreC2.begin(), vecScoreC2.end());
merge(vecScoreC1.begin(), vecScoreC1.end(), //第一个容器范围
vecScoreC2.begin(), vecScoreC2.end(), //第二个容器范围
vecScore.begin()); //目标容器的开始位置
copy(vecScore.begin(), vecScore.end(), ostream_iterator<int>(cout, " "));
cout << endl; // 结果:-2 2 5 9 25 59 65 75 85 92
降序:
vector<int> vecScoreC1 = {65, 59, 85, 92, 25,};
vector<int> vecScoreC2 = {5, 9, 75, 2, -2,};
//使用 merge() 进行合并之前,必须先使用 sort() 对两个容器排序。
vector<int> vecScore;
vecScore.resize(vecScoreC1.size() + vecScoreC2.size());//分配足够的空间
sort(vecScoreC1.begin(), vecScoreC1.end(), greater<int>());
sort(vecScoreC2.begin(), vecScoreC2.end(), greater<int>());
merge(vecScoreC1.begin(), vecScoreC1.end(), //第一个容器范围
vecScoreC2.begin(), vecScoreC2.end(), //第二个容器范围
vecScore.begin(), greater<int>()); //目标容器的开始位置
copy(vecScore.begin(), vecScore.end(), ostream_iterator<int>(cout, " "));
cout << endl; // 92 85 75 65 59 25 9 5 2 -2
//试了一下,没有 sort 也可以,但只是简单的拼接(不排序),也不成块,但merge降序会成块。
//还有若sort排序与merge排序不一致,也是简单的拼接并不排序。
//若默认升序,则sort与merge都默认。若想降序,则sort与merge均降序。可以先简单地拼接,然后在sort排序。
set_union() 将在合并时相同的元素只保留一份。set_union()返回尾迭代器。实际上,set_union() 是计算两个容器的并集。set_deference() 计算两个容器的差集。譬如:
vector<string> a = {"Pen", "Eraser", "Notebook",};
vector<string> b = {"Pen", "Folder", "Pen"};
vector<string> c;
c.resize(a.size() + b.size());//分配足够的空间
sort(a.begin(), a.end());
sort(b.begin(), b.end());
auto it = set_union(a.begin(), a.end(), //第一个容器范围
b.begin(), b.end(), //第二个容器范围
c.begin()); //目标容器的开始位置,也可以加comp比较函数。
cout << *(it-1) << endl; // set_union()返回尾迭代器
copy(c.begin(), c.end(), ostream_iterator<string>(cout, " "));
cout << endl;
// Eraser Folder Notebook Pen Pen
//看出set_union()可以合并两个容器并把它们之间相同的元素只保留一个,
//但对容器内部的相同元素无能为力。若想删除容器中的重复元素,可以先sort,再unique,后erase。
//sort(v.begin(),v.end()); v.erase(unique(v.begin(), v.end()), v.end());
10.3.3 变换容器元素:transform 函数
transform() 原型如下:返回尾迭代器(目标容器中被存入最后一个元素的下一位置)
template< class InputIt, class OutputIt, class UnaryOperation >
OutputIt transform( InputIt first1, InputIt last1, OutputIt d_first,
UnaryOperation unary_op );
template< class InputIt1, class InputIt2, class OutputIt, class BinaryOperation >
OutputIt transform( InputIt1 first1, InputIt1 last1, InputIt2 first2,
OutputIt d_first, BinaryOperation binary_op );
用法:
int add(int a, int b)
{
return a+b;
}
vector<int> vecScoreMath;
vecScoreMath.push_back(26);
vecScoreMath.push_back(42);
vecScoreMath.push_back(72);
//transform处理数据
transform(vecScoreMath.begin(), vecScoreMath.end(),//输入数据的范围
vecScoreMath.begin(), //保存结果的容器的开始位置
[](int i){if(i>30 && i<60)i=60;return i;}); //对数据处理的操作函数
copy(vecScoreMath.begin(), vecScoreMath.end(), ostream_iterator<int>(cout, " "));
cout << endl; // 26 60 72
//transform 版本2
vector<int> vecScoreEng = {75, 65, 20};
vector<int> vecScore;
vecScore.resize(4);
transform(vecScoreMath.begin(), vecScoreMath.end(), //第一个输入数据的范围
vecScoreEng.begin(), //第二个输入数据的开始位置
vecScore.begin(), //保存数据结果的容器的开始位置
add); //对数据处理的操作函数
copy(vecScore.begin(), vecScore.end(), ostream_iterator<int>(cout, " "));
cout << endl;
//若第一个容器是 26 60 72 ,第二个容器是 75 65 85 62 ,存结果的容器大小为4,——》结果:101 125 157 0
//若第一个容器是 26 60 72 ,第二个容器是 75 65 ,存结果的容器大小为4,——》结果:101 125 未知数 0
//所以,必须保证 第一个容器的大小 < 第二个容器的大小 。一般两个容器的大小要相等。
- lower_bound() 与 upper_bound() 必须先升序排列。
lower_bound(first,last,value)返回第一个 ≥ value 的迭代器。upper_bound(first,last,value)返回第一个 > value 的迭代器
- equal_range(first, last, value) 返回一个pair 包含 等于value的 范围。必须先升序排列。
template<class ForwardIt, class T>
std::pair<ForwardIt,ForwardIt>
equal_range(ForwardIt first, ForwardIt last,
const T& value)
{
return std::make_pair(std::lower_bound(first, last, value),
std::upper_bound(first, last, value));
}
用法:
vector<int> vecScoreEng = {75, 1, 2, 2, 65, 20};
sort(vecScoreEng.begin(), vecScoreEng.end());//默认升序
// reverse(vecScoreEng.begin(), vecScoreEng.end());//颠倒数组
//使用lower_bound()与upper_bound()函数必须先升序排列
//lower_bound(first,last,value)返回第一个 ≥ value 的迭代器
//upper_bound(first,last,value)返回第一个 > value 的迭代器
auto lower = lower_bound(vecScoreEng.begin(), vecScoreEng.end(), 20);
auto upper = upper_bound(vecScoreEng.begin(), vecScoreEng.end(), 20);
copy(lower, upper, ostream_iterator<int>(cout, " "));
/*
auto it = equal_range(vecScoreEng.begin(), vecScoreEng.end(), 20);
copy(it.first, it.second, ostream_iterator<int>(cout, " ")); //这两句与上3句等价,输出20
cout << endl;
*/
// 升序后:1 2 2 20 65 75
// 第一个 ≥ 20 的是 20的位置,第一个 > 20 的是 65的位置,故输出 20
- max_element() 与 min_element()
max_element(first,last) 函数返回最大值的迭代器。也可以加 参数comp (可以是 bool 类型比较函数,或函数对象) 来自定义。
min_element(first,last) 函数返回最小值的迭代器。也可以加 参数comp (可以是 bool 类型比较函数,或函数对象) 来自定义。
10.5 实战STL算法
Student st1("ChenLianqiao", 173);
Student st2("JiaWei", 163);
Student st3("JiaJunpeng", 187);
vector<Student> vecStu;
vecStu.push_back(st1);
vecStu.push_back(st2);
vecStu.push_back(st3);
Student st4("Lee", 164);
Student st5("Wang", 180);
Student st6("Liu", 163);
Student st7("ChenLianqiao", 173);
vector<Student> vecStuC2;
vecStuC2.push_back(st4);
vecStuC2.push_back(st5);
vecStuC2.push_back(st6);
vecStuC2.push_back(st7);
vecStu.resize(vecStu.size() + vecStuC2.size());
copy_backward(vecStuC2.begin(), vecStuC2.end(), vecStu.end());//参考上面的介绍
//当vector中存的是对象,用mem_fun_ref()将成员函数地址构造成函数对象
//当vector中存的是对象的指针,用mem_fun()将成员函数地址构造成函数对象
//ptr_fun() 函数将一个普通的函数指针转换为一个函数对象
sort(vecStu.begin(), vecStu.end(), sortbyHeight);
for_each(vecStu.begin(), vecStu.end(), mem_fun_ref(&Student::ReportName));
cout << endl;
//删除冗余数据
//先sort()升序,再unique()——自定义类型要重载"==",后erase()
// //第一步,排序。上面已做过
// //第二步:unique()
// vector<Student>::iterator it = unique(vecStu.begin(), vecStu.end());
// //第三步:erase()
// vecStu.erase(it, vecStu.end());
vecStu.erase(unique(vecStu.begin(), vecStu.end()), vecStu.end()); //或者合并第二步与第三步
for_each(vecStu.begin(), vecStu.end(), mem_fun_ref(&Student::ReportName));
cout << endl;