最近在学习python爬虫,简单易上手,而且有成就感。爬虫不仅需要一个url地址,headers,而且Cookie也是必须的。下面我总结三种方法关于cookie的相关请求
不管第几种,我们都得先要登录进去想要爬虫的网页,来获取cookie(通过抓包方式)
第一种:将获取的cookie放到我们的headers里。Cookie首字母要大写,如下: ``` headers = {"User-Agent": "User-Agen值" ,"Cookie": "Cookie值" } ``` --- 第二种:将获取的cookie到一个cookie字典,通过get方法传递参数,如下: ``` cookie = "cookie值" cookie_dict = {i.split("=")[0]:i.split("=")[-1] for i in cookie.split("; ")} response = requests.get(url,headers=headers,cookies = cookie_dict) ``` 因为cookie的形式事 "..."="...",并且以; 分开,所以我们需要将他们拆分,具体步骤就是第二行代码 --- 第三种:用session方法,将cookie保留在session里
第三种:首先我们要获取它的action地址(一般网站action不会写出的,所以需要我们抓包,在抓包的时候,点击Network里的Preserve log,当我们点击登录按钮时,就会显示我们需要验证的action地址。在直接一步前,先把用户名和密码的name属性值获得)
1
2
3
4
5
6
7
session = requests.session() #获取session
post_url = "是你进行相应的地址,就是你抓包获得地址"
data = {"u":"对应你的的用户名","p":"对应你的密码"} #这个u我爬腾讯空间用户名的name值,y时密码的name值
session.post(post_url,headers=headers,data=data) #通过post请求会自动将服务器设置在本地的cookie保存在session
url = "你要爬虫的地址"
response = session.get(url) #会带上之前保存在session的cookie
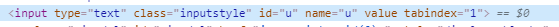
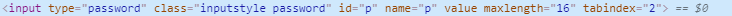
以上就是处理cookie的方法,可以试试