有一个高效的网页解析库
它的名字叫做
BeautifulSoup
它
是一个可以从 HTML 或 XML 文件中提取数据的 Python 库
首先我们要安装一下这个库
pip install beautifulsoup4
beautifulsoup支持不同的解析器
比如
对 HTML 的解析
对 XML 的解析
对 HTML5 的解析
你看
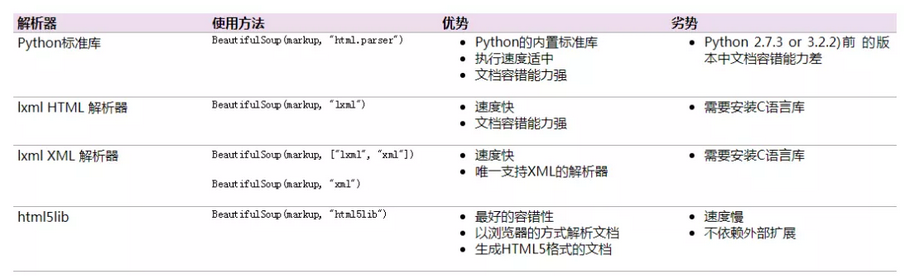
一般情况下
我们用的比较多的是 lxml 解析器
我们先来使用一个例子
让你体验一下
beautifulsoup 的一些常用的方法
有一个高效的网页解析库
它的名字叫做
BeautifulSoup
它
是一个可以从 HTML 或 XML 文件中提取数据的 Python 库
首先我们要安装一下这个库
pip install beautifulsoup4
beautifulsoup支持不同的解析器
比如
对 HTML 的解析
对 XML 的解析
对 HTML5 的解析
你看
一般情况下
我们用的比较多的是 lxml 解析器
我们先来使用一个例子
让你体验一下
beautifulsoup 的一些常用的方法