Real Adaboost分类器是对经典Adaboost分类器的扩展和提升,经典Adaboost分类器的每个弱分类器仅输出{1,0}或{+1,-1},分类能力较弱,Real Adaboost的每个弱分类器输出的是一个实数值(这也是为什么叫“Real”),可以认为是一个置信度。和LUT(look-up table)结合之后,表达复杂函数的能力比经典Adaboost更强。
接下来分三部分,第一部分解释经典Adaboost,第二部分解释Real Adaboost,第三部分举例说明
一、经典Adaboost
经典Adaboost分类器的训练过程如下:

虽然弱分类器的样式没有限制,可以是基于多维特征的决策树,甚至是SVM,但通常每个弱分类器都是基于所有特征中的某一维构建,并且输出的结果只有+1,-1两种(对于二分类)。因此,在训练时,每一轮迭代都挑选在当前训练集分布下,分类效果最好的那一维特征对应的弱分类器。
在预测时,输入一个样本,经典Adaboost将所有弱分类器输出的{-1,+1}值带权相加,作为最后结果。为了得到不同的准确率和召回率,使用者可以设置不同的threshold。例如:如果输出是0.334,那么如果设置threshold=0,分类结果为+1,如果threshold=0.5,分类结果为-1.
二、Real Adaboost
Real Adaboost分类器的训练过程如下:


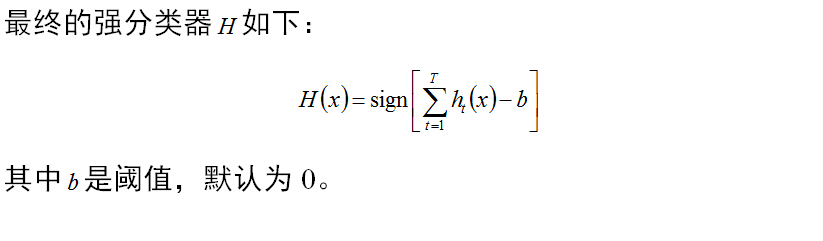
三、举例说明
第二部分里面介绍的Real Adaboost训练估计大部分人看起来还是挺费解的,举个例子说明一下。在堪称经典的《fast rotation invariant multi-view face detection based on real adaboost》一文中,就用到了real adaboost。首先,论文从滑动窗口中提取了很多haar特征,如果不知道haar特征是什么,可以参考我的博客Viola Jones Face Detector。然后对于每一个haar特征,将其归一化到[0,1],再对其做64等分。也就是说把0-1等分成了64份。这就是二里面说的若干个互不相交的子空间。接下来的计算和二里面一致,在这64个子空间里面计算正负样本的带权和W(+1)、W(-1),再用这两个值计算弱分类器输出和归一化因子Z。最终选择Z最小的那一个haar特征上的弱分类器作为该轮迭代选取出的弱分类器。这个弱分类器,其实就是对于64个子空间有64个对应的实数输出值。在预测时,如果把64个值保存到数组中,我们就可以使用查表的方式来计算任意输入特征对应的分类器输出了。假设输入的haar特征是0.376(已经归一化了),0.376/(1/64)=24.064,那么这个值落在了第24个子空间中,也就是数组中的第24个元素的值。即当前弱分类器的输出值。最后我们再将所有弱分类器的输出求和,并设置好阈值b,就可以得到最终的强分类器输出结果了。就是这么简单。