1.目标分析:
(1)打开起点中文网,搜索所有完本小说:
原始的网址是这样的:http://a.qidian.com/?action=1&orderId=&page=1&style=1&pageSize=2&siteid=4&hiddenField=3
界面是这样的:
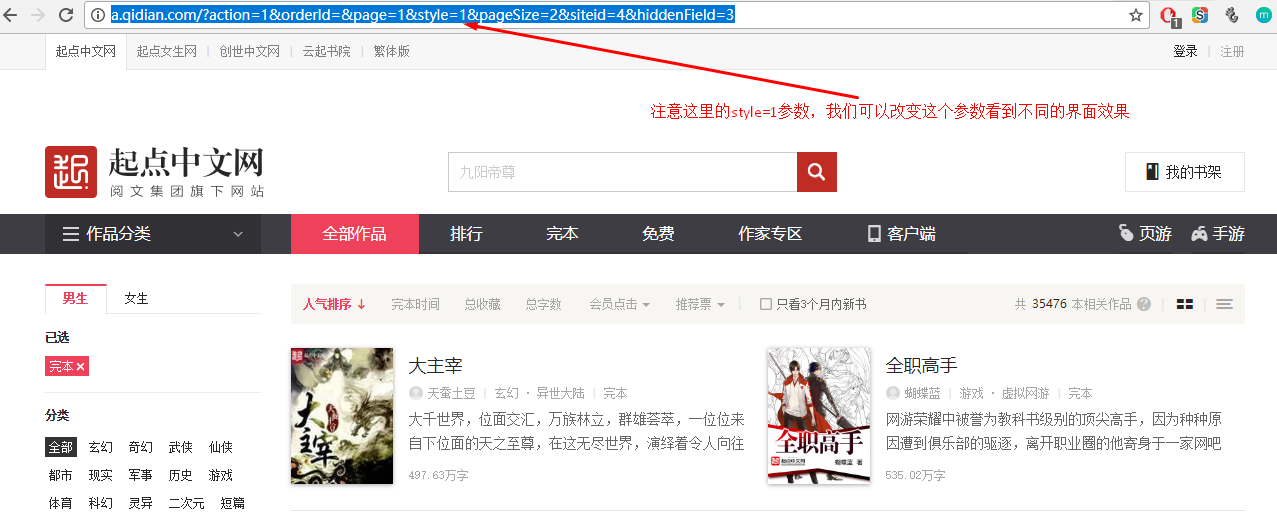
修改网址中的参数,观察不同效果:
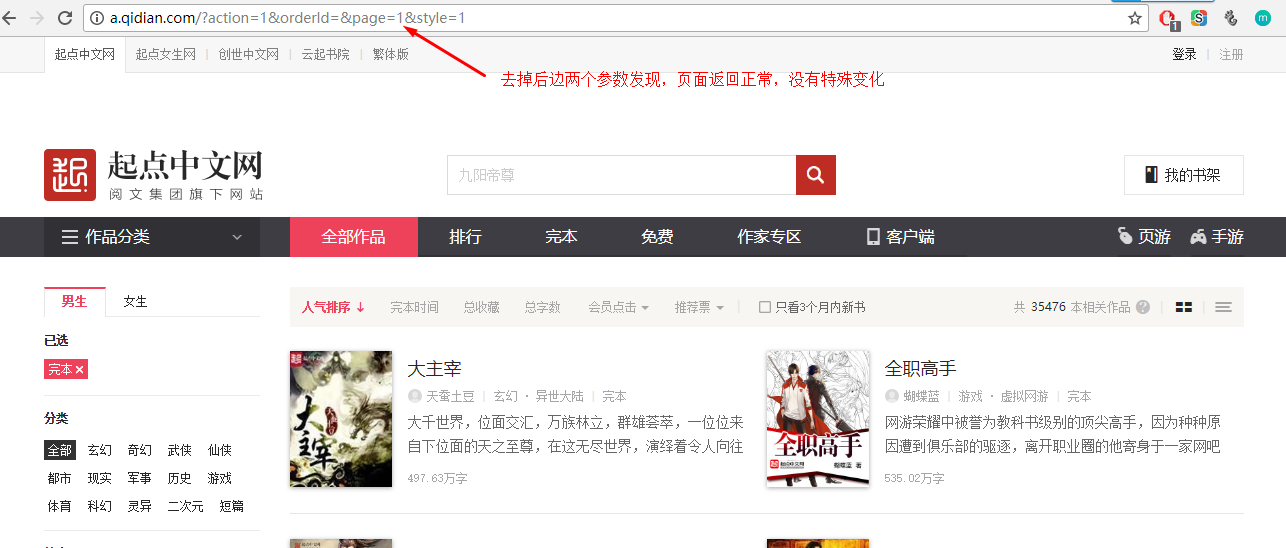
再修改参数style试试:
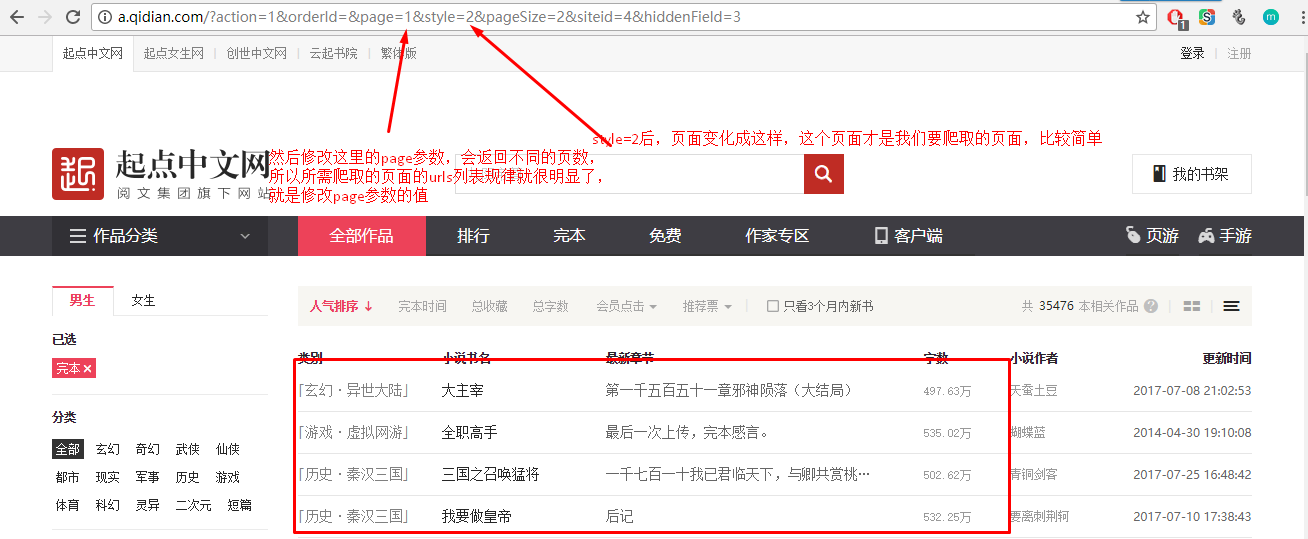
(2)查看页面源代码:
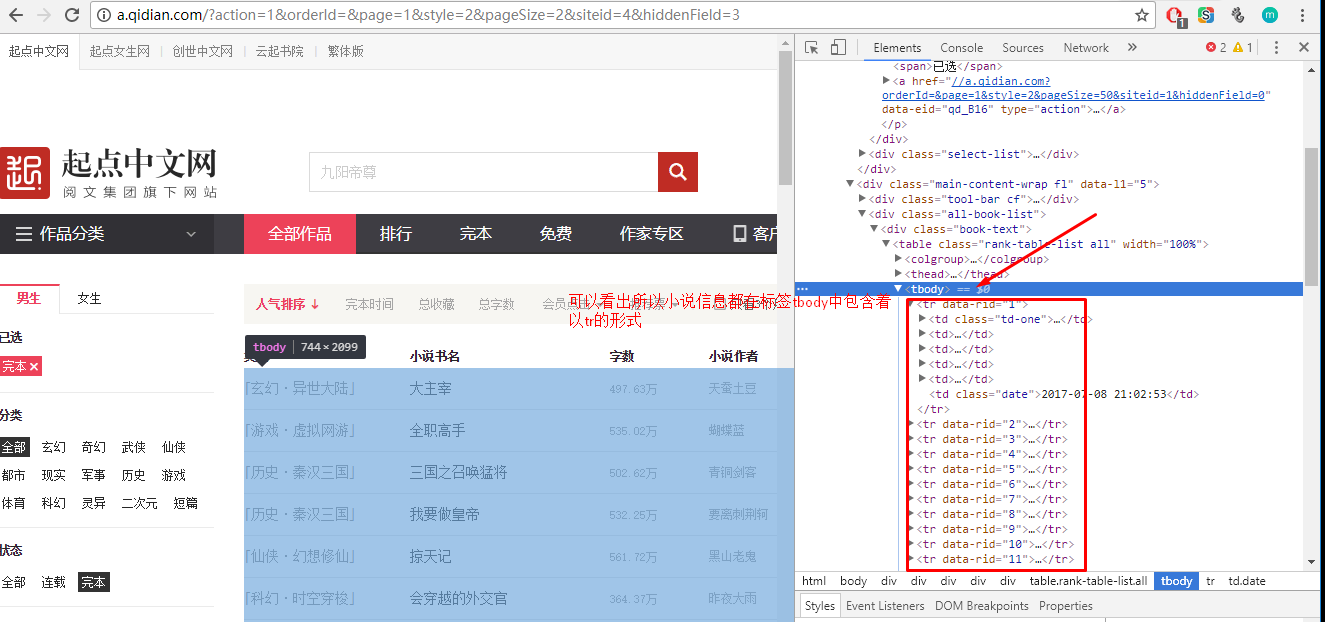
2.项目实施:
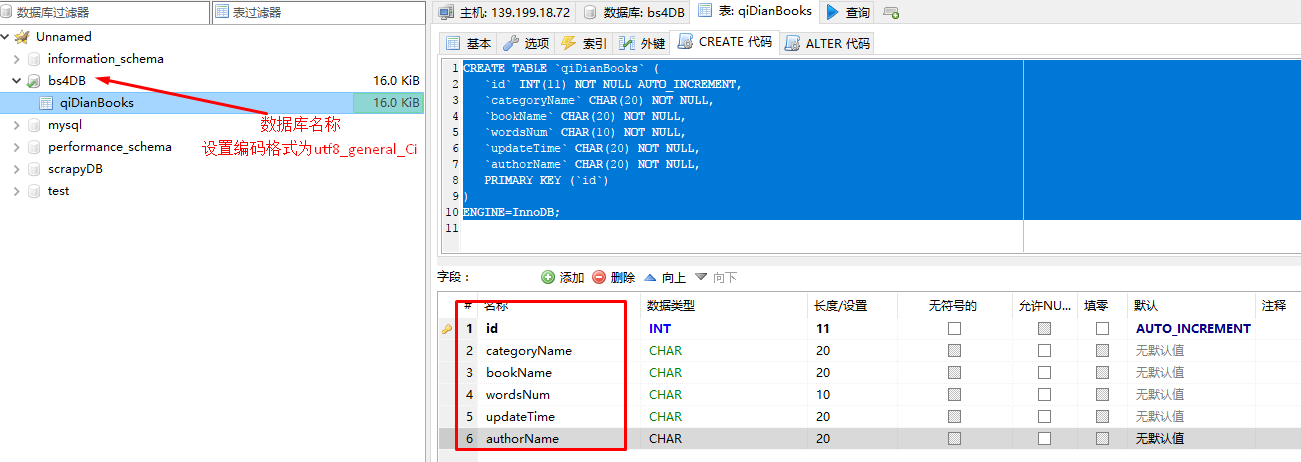
(1)创建远程数据库以及表:
CREATE TABLE `qiDianBooks` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`categoryName` CHAR(20) NOT NULL,
`bookName` CHAR(20) NOT NULL,
`wordsNum` CHAR(10) NOT NULL,
`updateTime` CHAR(20) NOT NULL,
`authorName` CHAR(20) NOT NULL,
PRIMARY KEY (`id`)
)
ENGINE=InnoDB;
(2)编写把数据保存到远程mysql数据库的文件:save2mysql.py
#! /usr/bin/env python
#-*- coding:utf-8 -*-
import MySQLdb
class SavebookData(object):
def __init__(self,items):
self.host='*********'
self.port=3306
self.user='crawlUSER'
self.passwd='*******'
self.db='bs4DB'
self.run(items)
def run(self,items):
conn=MySQLdb.connect(host=self.host,port=self.port,user=self.user,passwd=self.passwd,db=self.db,charset='utf8')
cur=conn.cursor()
print(u'连接成功')
for item in items:
cur.execute("INSERT INTO qiDianBooks(categoryName,bookName,wordsNum,updateTime,authorName) VALUES (%s,%s,%s,%s,%s)",
(item.categoryName.encode('utf8'),item.bookName.encode('utf8'),item.wordsNum.encode('utf8'),item.updateTime.encode('utf8'),item.authorName.encode('utf8')))
cur.close()
conn.commit()
conn.close()
if __name__ == '__main__':
pass
(3)编写主程序文件completeBook.py文件:
#! /usr/bin/env python
#-*- coding:utf-8 -*-
from bs4 import BeautifulSoup
import urllib2
import re
import codecs
import time
from mylog import MyLog as mylog
from save2mysql import SavebookData
class BookItem(object):
categoryName=None #小时类型
middleUrl=None
bookName=None #小说名
wordsNum=None #总字数
updateTime=None #更新时间
authorName=None #作者
class GetBookName(object):
def __init__(self):
self.urlBase='http://a.qidian.com/?action=1&orderId=&style=2&page=1'
self.log=mylog()
self.pages=self.getPages(self.urlBase)
self.booksList=[]
self.spider(self.urlBase,self.pages)
self.pipelines(self.booksList)
self.log.info('begin save data to mysql ')
SavebookData(self.booksList)
self.log.info('save data to mysql end...... ')
def getPages(self,url):
htmlContent=self.getResponseContent(url)
soup=BeautifulSoup(htmlContent,'lxml')
tags=soup.find('ul',attrs={'class':'lbf-pagination-item-list'})
strUrl=tags.find_all('a')[-2].get('href')
self.log.info(strUrl)
self.log.info(strUrl.split('&'))
for st in strUrl.split('&'):
self.log.info(st)
if re.search('page=',st):
pages=st.split('=')[-1]
self.log.info(u'获取页数为:%s' %pages)
return int(pages)
def getResponseContent(self,url):
try:
response=urllib2.urlopen(url.encode('utf8'))
except:
self.log.error(u'python 返回 URL:%s 数据失败' %url)
else:
self.log.info(u'Python 返回URL:%s A数据成功' %url)
return response.read()
def spider(self,url,pages):
urlList=url.split('=')
self.log.info(urlList)
for i in xrange(1,pages+1):
urlList[-1]=str(i)
newUrl='='.join(urlList)
self.log.info(newUrl)
htmlContent=self.getResponseContent(newUrl)
soup=BeautifulSoup(htmlContent,'lxml')
tags=soup.find('div',attrs={'class':'main-content-wrap fl'}).find('div',attrs={'class':'all-book-list'}).find('tbody').find_all('tr')
self.log.info(tags[0])
for tag in tags:
tds=tag.find_all('td')
self.log.info(tds)
item=BookItem()
item.categoryName=tds[0].find('a',attrs={'class':'type'}).get_text()+tds[0].find('a',attrs={'class':'go-sub-type'}).get_text()
item.middleUrl=tds[0].find('a',attrs={'class':'type'}).get('href')
item.bookName=tds[1].find('a',attrs={'class':'name'}).get_text()
item.wordsNum=tds[3].find('span',attrs={'class':'total'}).get_text()
item.updateTime=tds[5].get_text()
item.authorName=tds[4].find('a',attrs={'class':'author'}).get_text()
self.log.info(item.categoryName)
self.booksList.append(item)
self.log.info(u'获取书名为<<%s>>的数据成功' %item.bookName)
def pipelines(self,bookList):
bookName=u'起点中文网完本小说.txt'.encode('GBK')
nowTime=time.strftime('%Y-%m-%d %H:%M:%S ',time.localtime())
with codecs.open(bookName,'w','utf8') as fp:
fp.write('run time :%s' %nowTime)
for item in self.booksList:
fp.write('%s %s %s %s %s ' %(item.categoryName,item.bookName,item.wordsNum,item.updateTime,item.authorName))
self.log.info(u'将书名为<<%s>>的数据存入"%s".....' %(item.bookName,bookName.decode('GBK')))
if __name__ == '__main__':
GBN=GetBookName()
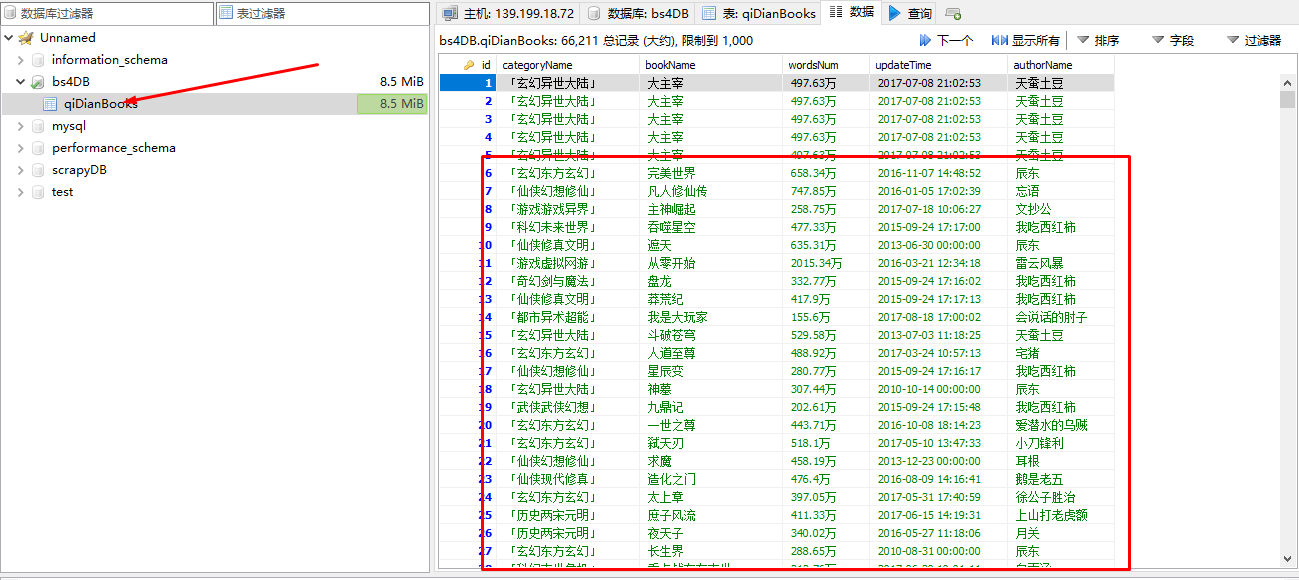
(4)运行结果:
数据库保存的数据
文本保存的数据:
