前言
我是个喜欢看电子书的人,因为可以边看边记笔记,写感言,对书中精彩的地方进行学习实践,
非常感谢本书作者家智老师,分享了这本书的最新电子版,让我有机会能阅读本书!
本书正版链接:
Java系统性能优化实战
一周目
1 java系统优化
1 一段代码的优化
// 原代码
public Map buildArea(List<Area> areas){
if(areas.isEmpty()){
return new HashMap();
}
Map<String,Area> map = new HashMap<>();
for(Area area:areas){
String key = area.getProvinceId()+"#"+area.getCityId();
map.put(key,area);
}
return map;
}
- 代码重构往往遗漏了注释, 如果代码改动,会给阅读者造成负担和困惑
- String作为Map的key,在某些情况下并非最优解,尤其是key需要字符串拼接等场景,Object在某些情况下可能性能更好
- 很多方法条件判断不满足,直接返回一个 new List等,可以返回一个初始化好的,不必每次创建一个空的集合,(需要注意返回的map是否还有其他操作,没有则可以)
- 构造map时,如果知道其长度可以指定一个size,避免不必要的扩容(扩容时间消耗较大)
2 使用jvisualvm抽样器,获取每个类每个方法的执行时间
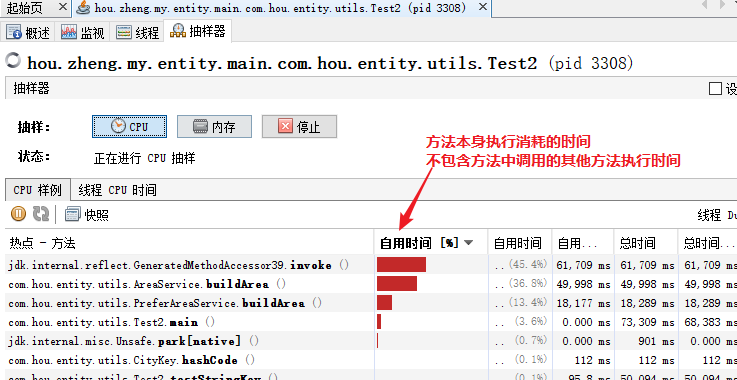
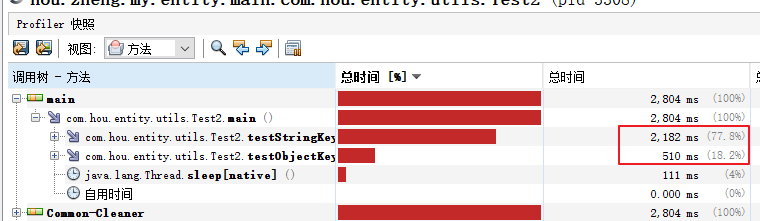
可以分析程序中哪个方法耗时最长,是否需要优化等,抽样中可以点击快照,保存当时的采样情况:
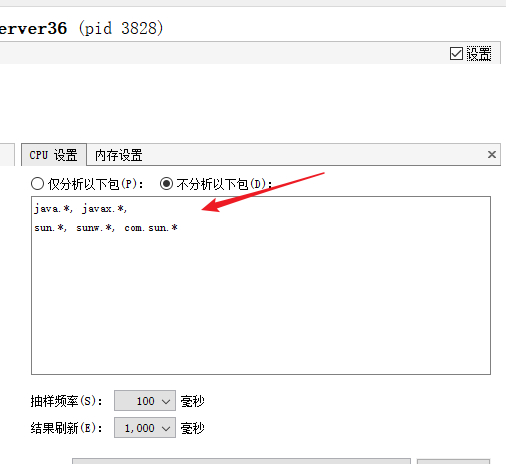
抽样器还可以自定义设置分析的包以及频率,这对于验证某些jdk方法的耗时非常有用:
3 JMH
是专门用于代码微基准测试的工具套件。主要是基于方法层面的基准测试,精度可以达到纳秒级。当你定位到热点方法,希望进一步优化方法性能的时候,就可以使用JMH对优化的结果进行量化的分析。
demo:
@BenchmarkMode(Mode.Throughput) // 使用模式,Throughput表示吞吐量,AverageTime每次执行时间
@Warmup(iterations = 3) //配置预热次数,默认是每次运行1秒,iterations:运行次数
@Measurement(iterations = 3, time = 5, timeUnit = TimeUnit.SECONDS) // 配置运行次数,time:每次运行时间
@Threads(1) // 配置多少个线程
@Fork(1) // 代表启动多少个单独的进程去测试每个方法
@OutputTimeUnit(TimeUnit.SECONDS) // 统计结果的时间单元, 即每秒的 吞吐量
public class MyBenchmark {
// 使用静态内部类,包含测试中使用的全部实例对象,可以用@State 标识对象的生命周期,JMH会决定是共用一个,还是每个线程都是一个新的
@State(Scope.Benchmark)
public static class SharedPara{
AreaService areaService = new AreaService();
PreferAreaService perferAreaService = new PreferAreaService();
List<Area> data = buildData(20);
private List<Area> buildData(int count){
List<Area> list = new ArrayList<>(count);
for(int i=0;i<count;i++){
Area area = new Area(i,i*10);
list.add(area);
}
return list;
}
/**
* Level.Tiral: 运行每个性能测试的时候执行,推荐的方式,相当于只运行一次。
* Level.Iteration, 每次运行迭代的时候执行
* Level.Invocation,每次调用方法的时候执行,这个选项需要谨慎使用
*/
@Setup(Level.Invocation)
public void init(){
//测试前的初始化,比如加载一个测试脚本
}
}
/**
* @Benchmark 标注两个需要比较的方法
* 注意:
* 1 为了避免虚拟机优化,所有测试方法都需要定义返回值,并且返回,
* 所以测试最好可以提供了一个baseline,即没有返回值的方法, 来检查是否方法被虚拟机优化而影响测试结果
* 2 尽量不要使用常量,或者返回常量(或者final类型),JIT会认为他是常量而直接优化
*/
@Benchmark
public static void testStringKey(SharedPara para){
//优化前的代码,使用 String拼接为key
para.areaService.buildArea(para.data);
}
@Benchmark
public static void testObjectKey(SharedPara para){
//要测试的优化后代码,使用Object为key
para.perferAreaService.buildArea(para.data);
}
public static void main(String[] args) throws RunnerException {
// include接受一个字符串表达式,表示需要测试的类和方法
// OptionsBuilder 也有类上注解的那些api可以直接调用
Options opt = new OptionsBuilder()
.include(MyBenchmark.class.getSimpleName())
.build();
// 执行测试,
new Runner(opt).run();
}
}
执行结果说明:
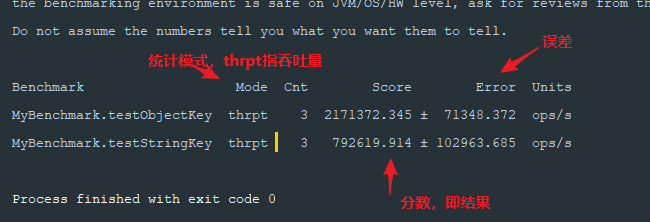
mode,可以在@BenchmarkMode注解中改变,测试执行时间等
2 字符串和数字
- 通过字节数组构造字符串是比较消耗CPU的,在设计分布式系统需要传输的字段时,尽量避免用String,比如时间用long,状态用int等
- 使用StringBuilder拼接其他类型,尤其是数字,性能会明显下降,因为Int转String至少需要50行代码,使用的时候需要考虑
- SLF4J 框架使用 {},来进行拼接,但是使用Format性能比直接拼接差(这也是很多开源框架不使用SLF4J的原因),考虑性能还是直接使用以下方式:
if(logger.isDebugEnable()){
logger.debug("订单id "+ id +" 用户 "+name+" 订单状态 "+status);
}
- String如果是查找单个字符,那么建议使用相应的接受char为参数的API,而不是String为参数的API,比如 String.indexOf('t')性能就好与String.indexOf("t").
- 关键字过滤,可以使用前缀树过滤,而不使用for循环replace,来提升性能
- 过多的数字装箱会创建对象,对垃圾回收增加负担,可以使用IntStream来进行int操作,避免使用集合等
- 在设计精度计算的时候,long类型比BigDecimal类型性能更好,大约四倍
4 代码性能优化
- 如果系统中有int转String的操作,可以提前将一部分int预先转化,作为缓存,int转String比较耗时,(原理跟Integer的装箱缓存类似)
- SimpleDateFormat类是非线程安全的,如果每次转换都需要new一个,性能比较差,可以使用ThreadLocal优化,从threadlocal中获取,或者使用DateTimeFormatter,线程安全
- 尽量避免使用异常,异常会导致性能降低(Java代码构造异常对象需要一个填写异常栈得操作),应该使用定义的错误码
- 循环展开可以提高性能,即减少循环次数,比如:
// 需要注意,这样 tasks就必须是4的倍数,如果不是,则就需要一定的预处理
List<Task> tasks = ....;
initTask(tasks)
for(int i=0;i<tasks.length;){
tasks[i++].execute();
tasks[i++].execute();
tasks[i++].execute();
tasks[i++].execute();
}
- 枚举的map使用用EnumMap性能会更好,同时微服务之间交互,尽量返回java的自带类型,不应该返回自定义类型,避免序列化,比如不返回枚举,返回String
- 位运算非常高效,优先考虑使用位运算
- 微服务调用中,压缩可以提高传输的速度,尽量减少属性key的长度,比如orderId可以用oid,可以用一个int,用位来表示多个状态
- 衡量消耗的时间最好使用System.nanoTime() 方法,nanoTime不是现实时间,是一个虚拟机提供的计时时间,精确到纳秒
- 生成随机数,可以使用ThreadLocalRandom,他在当前线程维护了一个种子,适合在多线程场景下提供高性能伪随机数生成
- Java8提供了java.util.Base64,在转化base64这块性能远远高于apache等的其他工具类
- 如果对象没有实现hashCode方法,系统返回默认的hashCode,与 System.identityHashCode(obj) 返回的一致System.identityHashCode(obj) 默认实现与虚拟机有关,其性能不高,最好的情况是自己实现高效的hashCode方法,并缓存计算好的hashCode
5 高性能工具
- 本地缓存: Caffeine
- 对象复制: selma
- Json工具:Jackson
- 数据库连接池: HikariCP (源码设计优化非常出色,后面阅读)
- 文本处理: Beetl
- 高性能反射工具:ReflectASM
7 可读性代码
-
使用临时变量不会影响性能,与其直接返回方法,不会先定义一个临时变量,然后返回,这样更容易阅读
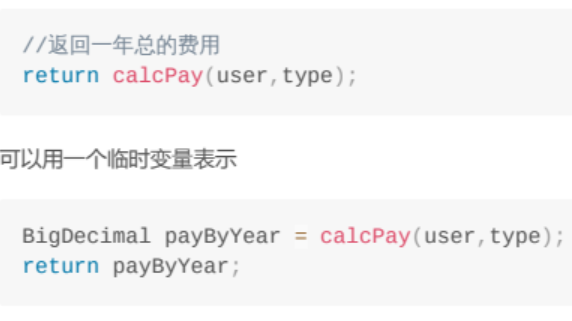
-
不需要在代码中备注修改历史,git会记录修改记录
-
尽量不要用null,无论是入参还是返回值
8 代码优化案例
- String类的搜索和replace,append,如果只是单个字符,可以使用性能更好的char参数方式
// char参数方法性能更好
int index = str.indexOf('{');
StringBuilder sb = new StringBuilder();
sb.append('{').....append(':')....apend('}')
2.StringBuilder拼接,如果知道容量,可以在new对象的时候指定容量,同时,如果有int转String,可以提前使用缓存,避免转化消耗性能
//建立一个缓存
static int cacheSize = 1024;
static String[] caches = new String[cacheSize];
static {
for(int i=0;i<cacheSize;i++){
caches[i] = String.valueOf(i);
}
}
- 方法的入参和出参最好都使用对象,来代替map,map难以阅读
- 排序问题,如果自定义排序中,每次都要调用String.equals方法,则可以在类中增加排序依据属性,构造的时候就调用equasl,排序直接根据属性判断:
// 优化前:
Collections.sort(list,new Comparator<Task>(){
@Override
public int compare(Task a,Task b){
if(a.getName.equals("start")){
return 1
}else if(a.getName.equals("end")){
return -1
}else{
}
}
})
// 优化后:
// 定义排序依据
public class Task{
String name = null;
boolean start;
boolean end;
public Task(String name){
this.name = name;
if(name.equals("start")){
start = true;
}else if(name.equals("end")){
end = true;
}
}
}
// 排序:
public int compare(Task a,Task b){
if(a.isStart()){
return 1
}else if(a.isEnd()){
return -1
}else{
- 对于特殊ID的判断,没有必要每次都转为String, int转String会消耗性能,可以用其他方法代替
- 在代码中有多个条件判断时,优先处理异常情况,即先if判断,失败的代码,再写继续执行的逻辑代码
- 遍历map,使用map.entrySet() 遍历性能更高
- SimpleDateFormat是一个线程非安全类,工具类定义一个static属性,没用,必须每个方法都new一个,但是这样会影响性能,可以使用ThreadLocal:
private ThreadLocal<SimpleDateFormat> local = new ThreadLocal<SimpleDateFormat>(){
protected SimpleDateFormat initialValue(){
return new SimpleDateFormat("yyyy-MM-dd");
}
};
//调用方法,从threadlocal获取
public String format(Date d){
return local.get().format(d);
}
- 打印日志时候,使用拼接,不适用占位符,原因在于log日志框架内部会有一个把占位符号{}替换成目标变量耗时过程。考虑到info级别有可能频繁调用,对性能有影响,因此建议直接使用字符串输出
- for循环调用,性能可以稍微优化:
//优化前:
for(int i=0;i<list.size();i++){
}
// 优化后:定义好size,不用每次判断
for(int i=0,size=list.size();i<size;i++){
}
- 在使用lock的时候,应该定义成类变量,同时一定要try catch finally,保证释放所资源
- Java字符集使用Charset对象表示
- 开关判断的优化,如果从配置中获取某个值,有if判断,比如:
public int getInt(String key){
if(config.contains(key)){
return (Integer)config.get(key);
}
//.......
}
则可以将if条件去掉:
public int getInt(String key){
Integer a = (Integer)config.get(key);
if(a!=null){
return a;
}
//.......
}
- UUID 使用replaceAll去除-的优化
String uuidStr = UUID.randomUUID().toString();
String shortUuidStr = uuidStr.replaceAll("-","");
UUID的格式如下:
123e4567-e89b-12d3-a456-426655440000
通常业务中会去除-,使用replace,这对性能影响很大
通过查看源码可以发现,此处-是UUID的toString方法拼接的,因此,我们可以自己实现一个自定义UUID方法,只需要重写toString方法即可,性能会有较大提升
10 ASM运行时增强
关于ASM工具的内容,我详细写在了另外一篇博客中:
ASM库的使用
11 JSR269编译时增强
关于JSR269的内容,我也详细写在了另外一篇博客中:
JSR269的使用
12 OQL分析JVM内存
13 代码的9种性能优化方式
被惊艳到的YYDS
1 JMH工具的使用
对于工作中需要做一些代码优化,或者引入新的组件这些工作时,这个工具非常有用,可以直接测试新旧代码的性能对比,从而了解到代码优化带来的性能提升程度
2 for循环的一个小小优化:
//优化前:
for(int i=0;i<list.size();i++){
}
// 优化后:定义好size,不用每次判断
for(int i=0,size=list.size();i<size;i++){
}
3 JSR269
4 OQL内存分析工具
读后感
在读这本书的时候,总是能时刻感受到作者严谨的逻辑思维与精妙的编程技巧,也在阅读和跟着书中例子实际测试的过程中,收获了很多编程技巧和实用的工具,都是自己不曾了解过的!
记得在17年刚工作的时候,当时领导见到我的第二个问题就是,你有自己的编程思想吗,对于当时的我,还不太理解什么是自己的编程思想,现在想来,因为这个不理解,在刚工作的一两年内犯了很多可以避免的错误,可以说那个时候的自己是一个没有思想的行尸码农!
对于一个即使很小的开发功能而言,有的人,复用之前的老代码,改改就好,有的人,匆匆忙忙写了一大堆重复代码,似乎只是为了完成开发任务,同样的一个任务,两个人的处理方式为什么截然不同,我想,他们的行为不同是因为他们编程思想的不同!
那么有时候我在想,我的编程思想到底是什么样的呢?
是不断的学习新技术吗,读电子书,读技术文档,看视频教程,很多又用不到,刚开始工作的几年,的确恶补了很多开源技术,但是这是个无底洞
是不断的钻研源码,比如jdk源码,spring源码,但这是一个非常大的工程,稍有不慎,就是从努力到放弃
是不断的画饼,名其名曰职业规划,然后一下子下载了十几本书,告诉自己今年内看完,然后就会觉得生活很充实,但是很容易眼高手低
实际在工作中碰到的很多大牛,其实并没有很多新技术储备,但是在一个技术难题上,总能给出比我想的要好的解决方案,
在产品的需求评审中,总能提出来很多需求的缺陷,而我只能静静的当一个旁观者!
他们确实比我年龄大,但是你也不能把这完全归功于人生阅历,或者对现有系统业务更熟悉,毕竟牛顿在22岁就发现了万有引力,毕竟对系统熟悉的人有很多,我想这已经不能是一种技术能力,而是一种思维模式,即编程思想!
回顾刚开始工作的前两年,因为技术储备有限,而优先学习了很多的框架,那段实践的确技术上有了很大的进步,可是对于每一次需求评审,还是在原地踏步,
之后的一年,因为在互联网,开始把之前学习到技术实践在了工作中,在实践中遇到了很多学习中根本不会发现的问题,也发现了学习始终是学习,不能只学习!
也开始在看每一次需求原型时,开始思考,这个需求的可行性,就像小时候下的象棋,这个责任其实很多时候是组长和领导们的,但是只要你有想法,兵也能当将!
也开始读完没一本书,学习完每一个技术,都开始写博客,写总结,反思,谈收获,这个习惯一直坚持到今天,这对于我而言,是一个非常重要的习惯,因为工作中我就经常翻看自己以前的博客来解决问题的思路,
这就像是我的错题本,也是我的知识宝库!
最近的这一年,由于开始谈恋爱,我其实并没有学习很多新技术,但是在工作中感觉反而更加的游刃有余,更轻松,我想很重要的一点是自己慢慢形成了“编程思想”:
我觉得可以归为四点:
学以致用,学而思,好记性不如烂笔头,努力做一位极客
1 所有大牛都是小白学习过来,但是为什么有的人成为了大牛,有的人还是代码的搬运工,其实很多人有一个误区,就是在面试之前学习应付面试,面试后就躺平了,而真正的学习技术,应该是需要去及时使用它,这样才能检验出你学习的掌握程度,倘若你短期内用不到这个技术,那么我建议你还是三思,因为时间不等人,清晰的方向比努力更优先,当然,时间充足的情况下,你还是可以努力钻研更多的技术,但是这是一杆秤,你给予学习的时间越多,就意味着你留给家人和爱人的时间越少!
2 很多人看完一本书,写几个hello world,就自我感觉良好,觉得生活又充实了,后续工作中碰到很多问题又焦头烂额,我时常告诫自己,千万不能这样,看完一本书,一定要思考总结,这本书给我的启发,以及这些技术对于我现在的工作中有哪些帮助,可以做哪些优化和尝试!
3 我有一个习惯,记笔记,对于这个快节奏的时代,很多人看视频都是二倍速的,所以当你忘记已经读过的一本书或者技术文档的时候,你当然可以选择再看一遍,而我选择重翻我的笔记!我记笔记有好几年了,最开始在码云上用xmind,到后来的博客园,在到后来的博客园的md,做了各种不同的尝试,从最初的贴代码截图,记录非常多的内容,到后面开始新建码云项目,将代码和笔记放一块,到最后精简提炼内容,写在博客园,慢慢形成了现在你看到的这种笔记,但是记笔记的同时也会伴随着巨大的时间成本,所以记笔记一定要快,准,狠!
4 工作中经常会有一个开发任务,因为之前的代码有模板,所以为了应付,而直接ctrl c ctrl v,这其实是一个很好的机会,系统架构的机会,代码重构的机会,性能优化的机会,项目改造的机会,写出极致优雅代码的机会,这是你读一本书,花几千块在培训机构学不到的机会,这个时候应该努力做一位极客,首先做架构设计,全面了解需求,做出可扩展的优秀设计,并不着急先写代码,你甚至可以自己创造一个新的技术来实现这个功能,提高自己的内卷力!
最后我想回答一下刚开始工作的时候领导问过我的那个问题,你有自己的编程思想吗?

我可能不会永远在这一行干下去,但我会记住每个在工作中帮助纠正过我的人,他们让我更深刻的懂得,学习贵在坚持,选择大于努力,机会决定高度!