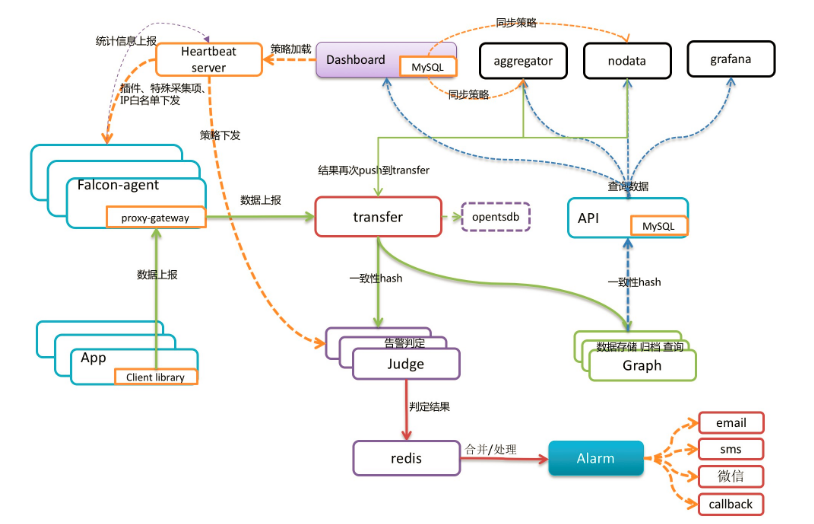
先扔出一张官方的架构图,
agent是用于采集机器的监控指标,然后每60秒就会push给transfer,agent与transfer是建立了长连接的,传输速度会比较快;
transfer接受到数据后,会按照哈希规则对数据进行处理分片,并把hash后的数据push给Judge和Graph;
Judge接受到hash数据后,就会根据设置的策略判断是否触发告警,如果触发告警就会把数据写入redis中;
Alarm会从redis中读取报警事件,然后通过各种媒介发送出;(redis的存活关乎着告警是否能够发出)
Graph接收到数据,会响应api中的查询请求,返回给绘图数据;
API会针对用户请求,到Graph中拿取数据组合后一起返回到Dashboard;
Dashboard服务的前端,可以查询图形化数据;也可以设置监控策略、报警策略等;与后端交互,可以将策略写入数据库;
HBS心跳机制,所有的agent都会连接到HBS,每分钟发一次心跳请求,Portal的数据库中有一个host表,记录了机器的信息,可以从CMDB中同步公司机器的信息,但小公司一般没有CMDB;所以HBS就赋予了一个搜集功能,agent发送心跳信息给HBS的时候,会把hostname、ip、agent version、plugin version等信息告诉HBS,HBS负责更新host表;第二个功能就是下发监控策略,端口监控和进程数监控,默认不会监控任何端口,只采集用户配置的端口,agent会向HBS索取这些用户配置,而HBS会在protal的数据库中读取;HBS还有一个功能就是,反正HBS会去数据库中读取端口策略,就让它把报警策略从数据库中缓存到内存,这样Judge只需向HBS请求,缓解数据库的压力。