源代码地址:https://github.com/hopebo/hopelee
语言:C++
517. Super Washing Machines
You have n super washing machines on a line. Initially, each washing machine has some dresses or is empty.
For each move, you could choose any m (1 ≤ m ≤ n) washing machines, and pass one dress of each washing machine to one of its adjacent washing machines at the same time .
Given an integer array representing the number of dresses in each washing machine from left to right on the line, you should find the minimum number of moves to make all the washing machines have the same number of dresses. If it is not possible to do it, return -1.
Example1
Input: [1,0,5] Output: 3 Explanation: 1st move: 1 0 <-- 5 => 1 1 4 2nd move: 1 <-- 1 <-- 4 => 2 1 3 3rd move: 2 1 <-- 3 => 2 2 2
Example2
Input: [0,3,0] Output: 2 Explanation: 1st move: 0 <-- 3 0 => 1 2 0 2nd move: 1 2 --> 0 => 1 1 1
Example3
Input: [0,2,0] Output: -1 Explanation: It's impossible to make all the three washing machines have the same number of dresses.
Note:
- The range of n is [1, 10000].
- The range of dresses number in a super washing machine is [0, 1e5].
You are given coins of different denominations and a total amount of money. Write a function to compute the number of combinations that make up that amount. You may assume that you have infinite number of each kind of coin.
Note: You can assume that
- 0 <= amount <= 5000
- 1 <= coin <= 5000
- the number of coins is less than 500
- the answer is guaranteed to fit into signed 32-bit integer
Example 1:
Input: amount = 5, coins = [1, 2, 5] Output: 4 Explanation: there are four ways to make up the amount: 5=5 5=2+2+1 5=2+1+1+1 5=1+1+1+1+1
Example 2:
Input: amount = 3, coins = [2] Output: 0 Explanation: the amount of 3 cannot be made up just with coins of 2.
Example 3:
Input: amount = 10, coins = [10] Output: 1
解题思路:
Given a word, you need to judge whether the usage of capitals in it is right or not.
We define the usage of capitals in a word to be right when one of the following cases holds:
- All letters in this word are capitals, like "USA".
- All letters in this word are not capitals, like "leetcode".
- Only the first letter in this word is capital if it has more than one letter, like "Google".
Example 1:
Input: "USA" Output: True
Example 2:
Input: "FlaG" Output: False
Note: The input will be a non-empty word consisting of uppercase and lowercase latin letters.
解题思路:
Given a group of two strings, you need to find the longest uncommon subsequence of this group of two strings. The longest uncommon subsequence is defined as the longest subsequence of one of these strings and this subsequence should not be anysubsequence of the other strings.
A subsequence is a sequence that can be derived from one sequence by deleting some characters without changing the order of the remaining elements. Trivially, any string is a subsequence of itself and an empty string is a subsequence of any string.
The input will be two strings, and the output needs to be the length of the longest uncommon subsequence. If the longest uncommon subsequence doesn't exist, return -1.
Example 1:
Input: "aba", "cdc" Output: 3 Explanation: The longest uncommon subsequence is "aba" (or "cdc"),
because "aba" is a subsequence of "aba",
but not a subsequence of any other strings in the group of two strings.
Note:
- Both strings' lengths will not exceed 100.
- Only letters from a ~ z will appear in input strings.
解题思路:
Given a list of strings, you need to find the longest uncommon subsequence among them. The longest uncommon subsequence is defined as the longest subsequence of one of these strings and this subsequence should not be any subsequence of the other strings.
A subsequence is a sequence that can be derived from one sequence by deleting some characters without changing the order of the remaining elements. Trivially, any string is a subsequence of itself and an empty string is a subsequence of any string.
The input will be a list of strings, and the output needs to be the length of the longest uncommon subsequence. If the longest uncommon subsequence doesn't exist, return -1.
Example 1:
Input: "aba", "cdc", "eae" Output: 3
Note:
- All the given strings' lengths will not exceed 10.
- The length of the given list will be in the range of [2, 50].
Given a list of non-negative numbers and a target integer k, write a function to check if the array has a continuous subarray of size at least 2 that sums up to the multiple of k, that is, sums up to n*k where n is also an integer.
Example 1:
Input: [23, 2, 4, 6, 7], k=6 Output: True Explanation: Because [2, 4] is a continuous subarray of size 2 and sums up to 6.
Example 2:
Input: [23, 2, 6, 4, 7], k=6 Output: True Explanation: Because [23, 2, 6, 4, 7] is an continuous subarray of size 5 and sums up to 42.
Note:
- The length of the array won't exceed 10,000.
- You may assume the sum of all the numbers is in the range of a signed 32-bit integer.
解题思路:
524. Longest Word in Dictionary through Deleting
Given a string and a string dictionary, find the longest string in the dictionary that can be formed by deleting some characters of the given string. If there are more than one possible results, return the longest word with the smallest lexicographical order. If there is no possible result, return the empty string.
Example 1:
Input: s = "abpcplea", d = ["ale","apple","monkey","plea"] Output: "apple"
Example 2:
Input: s = "abpcplea", d = ["a","b","c"] Output: "a"
Note:
- All the strings in the input will only contain lower-case letters.
- The size of the dictionary won't exceed 1,000.
- The length of all the strings in the input won't exceed 1,000.
Given a binary array, find the maximum length of a contiguous subarray with equal number of 0 and 1.
Example 1:
Input: [0,1] Output: 2 Explanation: [0, 1] is the longest contiguous subarray with equal number of 0 and 1.
Example 2:
Input: [0,1,0] Output: 2 Explanation: [0, 1] (or [1, 0]) is a longest contiguous subarray with equal number of 0 and 1.
Note: The length of the given binary array will not exceed 50,000.
Suppose you have N integers from 1 to N. We define a beautiful arrangement as an array that is constructed by these N numbers successfully if one of the following is true for the ith position (1 ≤ i ≤ N) in this array:
- The number at the ith position is divisible by i.
- i is divisible by the number at the ith position.
Now given N, how many beautiful arrangements can you construct?
Example 1:
Input: 2 Output: 2 Explanation:
The first beautiful arrangement is [1, 2]:
Number at the 1st position (i=1) is 1, and 1 is divisible by i (i=1).
Number at the 2nd position (i=2) is 2, and 2 is divisible by i (i=2).
The second beautiful arrangement is [2, 1]:
Number at the 1st position (i=1) is 2, and 2 is divisible by i (i=1).
Number at the 2nd position (i=2) is 1, and i (i=2) is divisible by 1.
Note:
- N is a positive integer and will not exceed 15.
解题思路:
Let's play the minesweeper game (Wikipedia, online game)!
You are given a 2D char matrix representing the game board. 'M' represents an unrevealed mine, 'E' represents an unrevealed empty square, 'B' represents a revealed blank square that has no adjacent (above, below, left, right, and all 4 diagonals) mines, digit ('1' to '8') represents how many mines are adjacent to this revealed square, and finally 'X' represents a revealed mine.
Now given the next click position (row and column indices) among all the unrevealed squares ('M' or 'E'), return the board after revealing this position according to the following rules:
- If a mine ('M') is revealed, then the game is over - change it to 'X'.
- If an empty square ('E') with no adjacent mines is revealed, then change it to revealed blank ('B') and all of its adjacent unrevealed squares should be revealed recursively.
- If an empty square ('E') with at least one adjacent mine is revealed, then change it to a digit ('1' to '8') representing the number of adjacent mines.
- Return the board when no more squares will be revealed.
Example 1:
Input: [['E', 'E', 'E', 'E', 'E'], ['E', 'E', 'M', 'E', 'E'], ['E', 'E', 'E', 'E', 'E'], ['E', 'E', 'E', 'E', 'E']] Click : [3,0] Output: [['B', '1', 'E', '1', 'B'], ['B', '1', 'M', '1', 'B'], ['B', '1', '1', '1', 'B'], ['B', 'B', 'B', 'B', 'B']] Explanation:

Example 2:
Input: [['B', '1', 'E', '1', 'B'], ['B', '1', 'M', '1', 'B'], ['B', '1', '1', '1', 'B'], ['B', 'B', 'B', 'B', 'B']] Click : [1,2] Output: [['B', '1', 'E', '1', 'B'], ['B', '1', 'X', '1', 'B'], ['B', '1', '1', '1', 'B'], ['B', 'B', 'B', 'B', 'B']] Explanation:

Note:
- The range of the input matrix's height and width is [1,50].
- The click position will only be an unrevealed square ('M' or 'E'), which also means the input board contains at least one clickable square.
- The input board won't be a stage when game is over (some mines have been revealed).
- For simplicity, not mentioned rules should be ignored in this problem. For example, you don't need to reveal all the unrevealed mines when the game is over, consider any cases that you will win the game or flag any squares.
解题思路:
Given a binary search tree with non-negative values, find the minimum absolute difference between values of any two nodes.
Example:
Input:
1
3
/
2
Output:
1
Explanation:
The minimum absolute difference is 1, which is the difference between 2 and 1 (or between 2 and 3).
Note: There are at least two nodes in this BST.
Given an array of integers and an integer k, you need to find the number of unique k-diff pairs in the array. Here a k-diff pair is defined as an integer pair (i, j), where i and j are both numbers in the array and their absolute difference is k.
Example 1:
Input: [3, 1, 4, 1, 5], k = 2 Output: 2 Explanation: There are two 2-diff pairs in the array, (1, 3) and (3, 5).
Although we have two 1s in the input, we should only return the number of unique pairs.
Example 2:
Input:[1, 2, 3, 4, 5], k = 1 Output: 4 Explanation: There are four 1-diff pairs in the array, (1, 2), (2, 3), (3, 4) and (4, 5).
Example 3:
Input: [1, 3, 1, 5, 4], k = 0 Output: 1 Explanation: There is one 0-diff pair in the array, (1, 1).
Note:
- The pairs (i, j) and (j, i) count as the same pair.
- The length of the array won't exceed 10,000.
- All the integers in the given input belong to the range: [-1e7, 1e7].
Note: This is a companion problem to the System Design problem: Design TinyURL.
TinyURL is a URL shortening service where you enter a URL such as https://leetcode.com/problems/design-tinyurl and it returns a short URL such as http://tinyurl.com/4e9iAk.
Design the encode and decode methods for the TinyURL service. There is no restriction on how your encode/decode algorithm should work. You just need to ensure that a URL can be encoded to a tiny URL and the tiny URL can be decoded to the original URL.
Given two strings representing two complex numbers.
You need to return a string representing their multiplication. Note i2 = -1 according to the definition.
Example 1:
Input: "1+1i", "1+1i" Output: "0+2i" Explanation: (1 + i) * (1 + i) = 1 + i2 + 2 * i = 2i, and you need convert it to the form of 0+2i.
Example 2:
Input: "1+-1i", "1+-1i" Output: "0+-2i" Explanation: (1 - i) * (1 - i) = 1 + i2 - 2 * i = -2i, and you need convert it to the form of 0+-2i.
Note:
- The input strings will not have extra blank.
- The input strings will be given in the form of a+bi, where the integer a and b will both belong to the range of [-100, 100]. And the output should be also in this form.
解题思路:
Given a Binary Search Tree (BST), convert it to a Greater Tree such that every key of the original BST is changed to the original key plus sum of all keys greater than the original key in BST.
Example:
Input: The root of a Binary Search Tree like this:
5
/
2 13
Output: The root of a Greater Tree like this:
18
/
20 13
Given a list of 24-hour clock time points in "Hour:Minutes" format, find the minimum minutes difference between any two time points in the list.
Example 1:
Input: ["23:59","00:00"] Output: 1
Note:
- The number of time points in the given list is at least 2 and won't exceed 20000.
- The input time is legal and ranges from 00:00 to 23:59.
Given a sorted array consisting of only integers where every element appears twice except for one element which appears once. Find this single element that appears only once.
Example 1:
Input: [1,1,2,3,3,4,4,8,8] Output: 2
Example 2:
Input: [3,3,7,7,10,11,11] Output: 10
Note: Your solution should run in O(log n) time and O(1) space.
Example:
Input: s = "abcdefg", k = 2 Output: "bacdfeg"Restrictions:
- The string consists of lower English letters only.
- Length of the given string and k will in the range [1, 10000]
解题思路:
Given a matrix consists of 0 and 1, find the distance of the nearest 0 for each cell.
The distance between two adjacent cells is 1.Example 1:
Input:
0 0 0 0 1 0 0 0 0Output:
0 0 0 0 1 0 0 0 0
Example 2:
Input:
0 0 0 0 1 0 1 1 1Output:
0 0 0 0 1 0 1 2 1
Note:
- The number of elements of the given matrix will not exceed 10,000.
- There are at least one 0 in the given matrix.
- The cells are adjacent in only four directions: up, down, left and right.
解题思路:
Given a binary tree, you need to compute the length of the diameter of the tree. The diameter of a binary tree is the length of the longest path between any two nodes in a tree. This path may or may not pass through the root.
Example:
Given a binary tree
1
/
2 3
/
4 5
Return 3, which is the length of the path [4,2,1,3] or [5,2,1,3].
Note: The length of path between two nodes is represented by the number of edges between them.
解题思路:
Given several boxes with different colors represented by different positive numbers.
You may experience several rounds to remove boxes until there is no box left. Each time you can choose some continuous boxes with the same color (composed of k boxes, k >= 1), remove them and get k*k points.
Find the maximum points you can get.
Example 1:
Input:
[1, 3, 2, 2, 2, 3, 4, 3, 1]Output:
23Explanation:
[1, 3, 2, 2, 2, 3, 4, 3, 1] ----> [1, 3, 3, 4, 3, 1] (3*3=9 points) ----> [1, 3, 3, 3, 1] (1*1=1 points) ----> [1, 1] (3*3=9 points) ----> [] (2*2=4 points)
Note: The number of boxes n would not exceed 100.
解题思路:
There are N students in a class. Some of them are friends, while some are not. Their friendship is transitive in nature. For example, if A is a direct friend of B, and B is a direct friend of C, then A is an indirect friend of C. And we defined a friend circle is a group of students who are direct or indirect friends.
Given a N*N matrix M representing the friend relationship between students in the class. If M[i][j] = 1, then the ith and jth students are direct friends with each other, otherwise not. And you have to output the total number of friend circles among all the students.
Example 1:
Input: [[1,1,0], [1,1,0], [0,0,1]] Output: 2 Explanation:The 0th and 1st students are direct friends, so they are in a friend circle.
The 2nd student himself is in a friend circle. So return 2.
Example 2:
Input: [[1,1,0], [1,1,1], [0,1,1]] Output: 1 Explanation:The 0th and 1st students are direct friends, the 1st and 2nd students are direct friends,
so the 0th and 2nd students are indirect friends. All of them are in the same friend circle, so return 1.
Note:
- N is in range [1,200].
- M[i][i] = 1 for all students.
- If M[i][j] = 1, then M[j][i] = 1.
You are given a string representing an attendance record for a student. The record only contains the following three characters:
- 'A' : Absent.
- 'L' : Late.
- 'P' : Present.
A student could be rewarded if his attendance record doesn't contain more than one 'A' (absent) or more than two continuous 'L' (late).
You need to return whether the student could be rewarded according to his attendance record.
Example 1:
Input: "PPALLP" Output: True
Example 2:
Input: "PPALLL" Output: False
Given a positive integer n, return the number of all possible attendance records with length n, which will be regarded as rewardable. The answer may be very large, return it after mod 109 + 7.
A student attendance record is a string that only contains the following three characters:
- 'A' : Absent.
- 'L' : Late.
- 'P' : Present.
A record is regarded as rewardable if it doesn't contain more than one 'A' (absent) or more than two continuous 'L' (late).
Example 1:
Input: n = 2 Output: 8 Explanation: There are 8 records with length 2 will be regarded as rewardable: "PP" , "AP", "PA", "LP", "PL", "AL", "LA", "LL" Only "AA" won't be regarded as rewardable owing to more than one absent times.
Note: The value of n won't exceed 100,000.
解题思路:
Given a list of positive integers, the adjacent integers will perform the float division. For example, [2,3,4] -> 2 / 3 / 4.
However, you can add any number of parenthesis at any position to change the priority of operations. You should find out how to add parenthesis to get the maximum result, and return the corresponding expression in string format. Your expression should NOT contain redundant parenthesis.
Example:
Input: [1000,100,10,2] Output: "1000/(100/10/2)" Explanation: 1000/(100/10/2) = 1000/((100/10)/2) = 200 However, the bold parenthesis in "1000/((100/10)/2)" are redundant,
since they don't influence the operation priority. So you should return "1000/(100/10/2)". Other cases: 1000/(100/10)/2 = 50 1000/(100/(10/2)) = 50 1000/100/10/2 = 0.5 1000/100/(10/2) = 2
Note:
- The length of the input array is [1, 10].
- Elements in the given array will be in range [2, 1000].
- There is only one optimal division for each test case.
解题思路:
There is a brick wall in front of you. The wall is rectangular and has several rows of bricks. The bricks have the same height but different width. You want to draw a vertical line from the top to the bottom and cross the least bricks.
The brick wall is represented by a list of rows. Each row is a list of integers representing the width of each brick in this row from left to right.
If your line go through the edge of a brick, then the brick is not considered as crossed. You need to find out how to draw the line to cross the least bricks and return the number of crossed bricks.
You cannot draw a line just along one of the two vertical edges of the wall, in which case the line will obviously cross no bricks.
Example:
Input: [[1,2,2,1], [3,1,2], [1,3,2], [2,4], [3,1,2], [1,3,1,1]] Output: 2 Explanation:
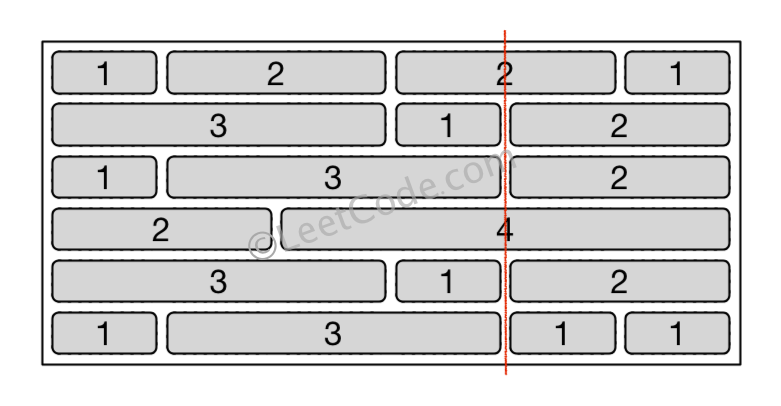
Note:
- The width sum of bricks in different rows are the same and won't exceed INT_MAX.
- The number of bricks in each row is in range [1,10,000]. The height of wall is in range [1,10,000]. Total number of bricks of the wall won't exceed 20,000.
Given a positive 32-bit integer n, you need to find the smallest 32-bit integer which has exactly the same digits existing in the integer nand is greater in value than n. If no such positive 32-bit integer exists, you need to return -1.
Example 1:
Input: 12 Output: 21
Example 2:
Input: 21 Output: -1
解题思路:
Given a string, you need to reverse the order of characters in each word within a sentence while still preserving whitespace and initial word order.
Example 1:
Input: "Let's take LeetCode contest" Output: "s'teL ekat edoCteeL tsetnoc"
Note: In the string, each word is separated by single space and there will not be any extra space in the string.
解题思路:
Given an array of integers and an integer k, you need to find the total number of continuous subarrays whose sum equals to k.
Example 1:
Input:nums = [1,1,1], k = 2 Output: 2
Note:
- The length of the array is in range [1, 20,000].
- The range of numbers in the array is [-1000, 1000] and the range of the integer k is [-1e7, 1e7].
Given an array of 2n integers, your task is to group these integers into n pairs of integer, say (a1, b1), (a2, b2), ..., (an, bn) which makes sum of min(ai, bi) for all i from 1 to n as large as possible.
Example 1:
Input: [1,4,3,2] Output: 4 Explanation: n is 2, and the maximum sum of pairs is 4 = min(1, 2) + min(3, 4).
Note:
- n is a positive integer, which is in the range of [1, 10000].
- All the integers in the array will be in the range of [-10000, 10000].
解题思路:
Given a binary tree, return the tilt of the whole tree.
The tilt of a tree node is defined as the absolute difference between the sum of all left subtree node values and the sum of all right subtree node values. Null node has tilt 0.
The tilt of the whole tree is defined as the sum of all nodes' tilt.
Example:
Input:
1
/
2 3
Output: 1
Explanation:
Tilt of node 2 : 0
Tilt of node 3 : 0
Tilt of node 1 : |2-3| = 1
Tilt of binary tree : 0 + 0 + 1 = 1
Note:
- The sum of node values in any subtree won't exceed the range of 32-bit integer.
- All the tilt values won't exceed the range of 32-bit integer.
Given an integer n, find the closest integer (not including itself), which is a palindrome.
The 'closest' is defined as absolute difference minimized between two integers.
Example 1:
Input: "123" Output: "121"
Note:
- The input n is a positive integer represented by string, whose length will not exceed 18.
- If there is a tie, return the smaller one as answer.
解题思路:
A zero-indexed array A consisting of N different integers is given. The array contains all integers in the range [0, N - 1].
Sets S[K] for 0 <= K < N are defined as follows:
S[K] = { A[K], A[A[K]], A[A[A[K]]], ... }.
Sets S[K] are finite for each K and should NOT contain duplicates.
Write a function that given an array A consisting of N integers, return the size of the largest set S[K] for this array.
Example 1:
Input: A = [5,4,0,3,1,6,2] Output: 4 Explanation: A[0] = 5, A[1] = 4, A[2] = 0, A[3] = 3, A[4] = 1, A[5] = 6, A[6] = 2.
One of the longest S[K]: S[0] = {A[0], A[5], A[6], A[2]} = {5, 6, 2, 0}
Note:
- N is an integer within the range [1, 20,000].
- The elements of A are all distinct.
- Each element of array A is an integer within the range [0, N-1].
In MATLAB, there is a very useful function called 'reshape', which can reshape a matrix into a new one with different size but keep its original data.
You're given a matrix represented by a two-dimensional array, and two positive integers r and c representing the row number and column number of the wanted reshaped matrix, respectively.
The reshaped matrix need to be filled with all the elements of the original matrix in the same row-traversing order as they were.
If the 'reshape' operation with given parameters is possible and legal, output the new reshaped matrix; Otherwise, output the original matrix.
Example 1:
Input: nums = [[1,2], [3,4]] r = 1, c = 4 Output: [[1,2,3,4]] Explanation:
The row-traversing of nums is [1,2,3,4]. The new reshaped matrix is a 1 * 4 matrix, fill it row by row by using the previous list.
Example 2:
Input: nums = [[1,2], [3,4]] r = 2, c = 4 Output: [[1,2], [3,4]] Explanation:
There is no way to reshape a 2 * 2 matrix to a 2 * 4 matrix. So output the original matrix.
Note:
- The height and width of the given matrix is in range [1, 100].
- The given r and c are all positive.
Given two strings s1 and s2, write a function to return true if s2 contains the permutation of s1. In other words, one of the first string's permutations is the substring of the second string.
Example 1:
Input:s1 = "ab" s2 = "eidbaooo"
Output:True
Explanation: s2 contains one permutation of s1 ("ba").
Example 2:
Input:s1= "ab" s2 = "eidboaoo" Output: False
Note:
- The input strings only contain lower case letters.
- The length of both given strings is in range [1, 10,000].
Given two non-empty binary trees s and t, check whether tree t has exactly the same structure and node values with a subtree of s. A subtree of s is a tree consists of a node in s and all of this node's descendants. The tree s could also be considered as a subtree of itself.
Example 1:
Given tree s:
3
/
4 5
/
1 2
Given tree t:
4 / 1 2Return true, because t has the same structure and node values with a subtree of s.
Example 2:
Given tree s:
3
/
4 5
/
1 2
/
0
Given tree t:
4 / 1 2Return false.
解题思路:
Given an integer array with even length, where different numbers in this array represent different kinds of candies. Each number means one candy of the corresponding kind. You need to distribute these candies equally in number to brother and sister. Return the maximum number of kinds of candies the sister could gain.
Example 1:
Input: candies = [1,1,2,2,3,3] Output: 3 Explanation: There are three different kinds of candies (1, 2 and 3), and two candies for each kind. Optimal distribution: The sister has candies [1,2,3] and the brother has candies [1,2,3], too. The sister has three different kinds of candies.
Example 2:
Input: candies = [1,1,2,3] Output: 2 Explanation: For example, the sister has candies [2,3] and the brother has candies [1,1]. The sister has two different kinds of candies, the brother has only one kind of candies.
Note:
- The length of the given array is in range [2, 10,000], and will be even.
- The number in given array is in range [-100,000, 100,000].
There is an m by n grid with a ball. Given the start coordinate (i,j) of the ball, you can move the ball to adjacent cell or cross the grid boundary in four directions (up, down, left, right). However, you can at most move N times. Find out the number of paths to move the ball out of grid boundary. The answer may be very large, return it after mod 109 + 7.
Example 1:
Input:m = 2, n = 2, N = 2, i = 0, j = 0 Output: 6 Explanation:
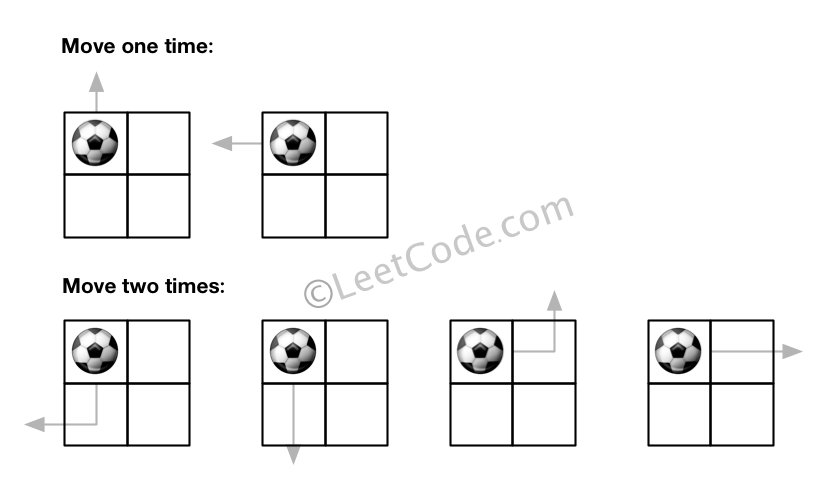
Example 2:
Input:m = 1, n = 3, N = 3, i = 0, j = 1 Output: 12 Explanation:
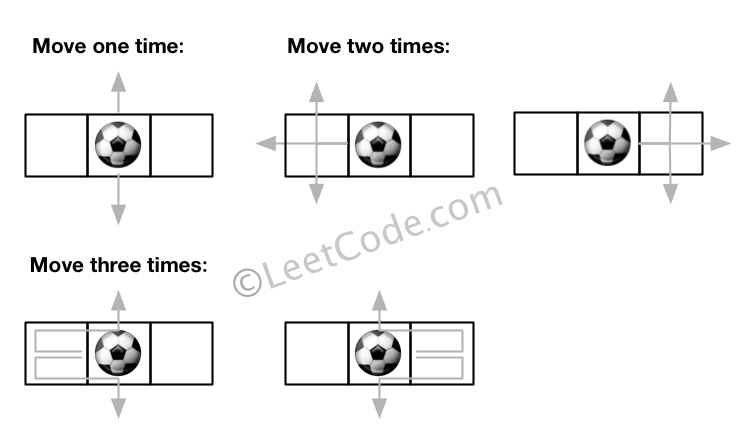
Note:
- Once you move the ball out of boundary, you cannot move it back.
- The length and height of the grid is in range [1,50].
- N is in range [0,50].
解题思路:
Given an integer array, you need to find one continuous subarray that if you only sort this subarray in ascending order, then the whole array will be sorted in ascending order, too.
You need to find the shortest such subarray and output its length.
Example 1:
Input: [2, 6, 4, 8, 10, 9, 15] Output: 5 Explanation: You need to sort [6, 4, 8, 10, 9] in ascending order to make the whole array sorted in ascending order.
Note:
- Then length of the input array is in range [1, 10,000].
- The input array may contain duplicates, so ascending order here means <=.
Given two words word1 and word2, find the minimum number of steps required to make word1 and word2 the same, where in each step you can delete one character in either string.
Example 1:
Input: "sea", "eat" Output: 2 Explanation: You need one step to make "sea" to "ea" and another step to make "eat" to "ea".
Note:
- The length of given words won't exceed 500.
- Characters in given words can only be lower-case letters.
There are some trees, where each tree is represented by (x,y) coordinate in a two-dimensional garden. Your job is to fence the entire garden using the minimum length of rope as it is expensive. The garden is well fenced only if all the trees are enclosed. Your task is to help find the coordinates of trees which are exactly located on the fence perimeter.
Example 1:
Input: [[1,1],[2,2],[2,0],[2,4],[3,3],[4,2]] Output: [[1,1],[2,0],[4,2],[3,3],[2,4]] Explanation:
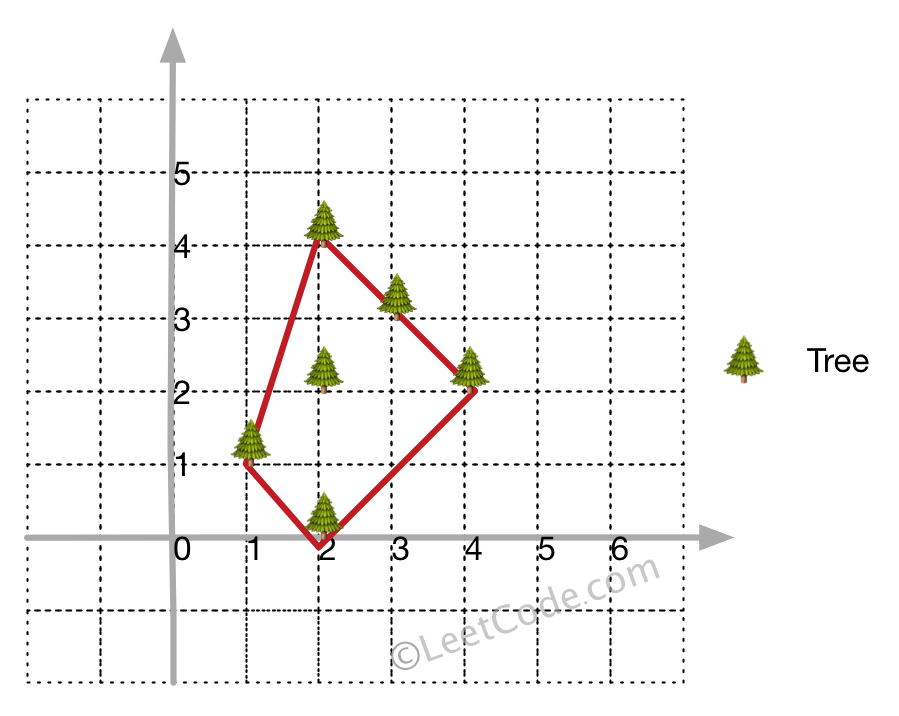
Example 2:
Input: [[1,2],[2,2],[4,2]] Output: [[1,2],[2,2],[4,2]] Explanation:
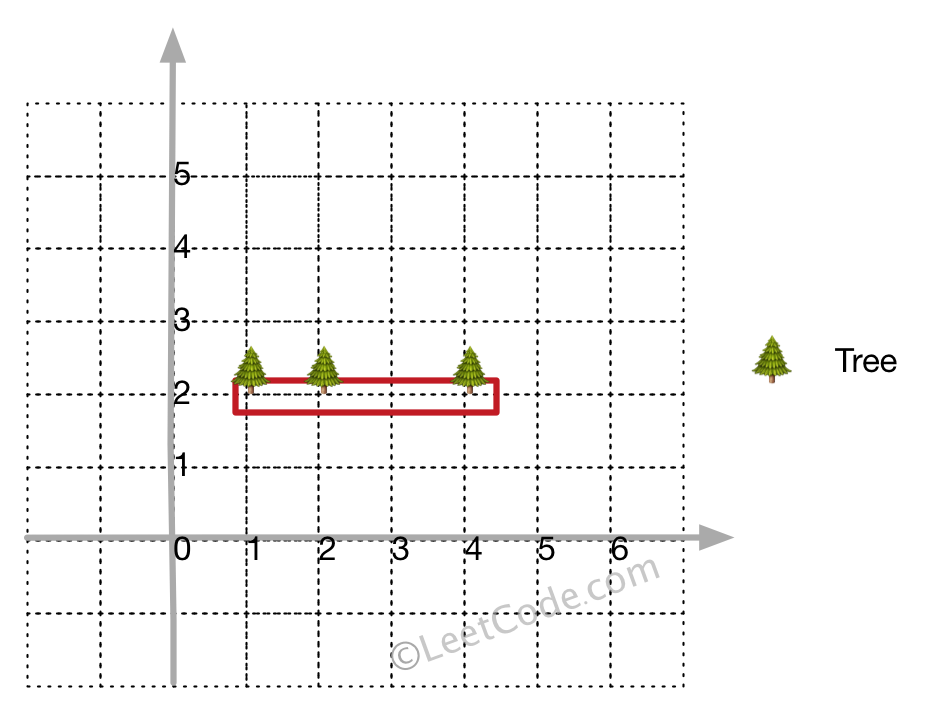
Even you only have trees in a line, you need to use rope to enclose them.
Note:
- All trees should be enclosed together. You cannot cut the rope to enclose trees that will separate them in more than one group.
- All input integers will range from 0 to 100.
- The garden has at least one tree.
- All coordinates are distinct.
- Input points have NO order. No order required for output.
解题思路:
Given a string representing a code snippet, you need to implement a tag validator to parse the code and return whether it is valid. A code snippet is valid if all the following rules hold:
- The code must be wrapped in a valid closed tag. Otherwise, the code is invalid.
- A closed tag (not necessarily valid) has exactly the following format :
<TAG_NAME>TAG_CONTENT</TAG_NAME>. Among them,<TAG_NAME>is the start tag, and</TAG_NAME>is the end tag. The TAG_NAME in start and end tags should be the same. A closed tag is valid if and only if the TAG_NAME and TAG_CONTENT are valid. - A valid
TAG_NAMEonly contain upper-case letters, and has length in range [1,9]. Otherwise, theTAG_NAMEis invalid. - A valid
TAG_CONTENTmay contain other valid closed tags, cdata and any characters (see note1) EXCEPT unmatched<, unmatched start and end tag, and unmatched or closed tags with invalid TAG_NAME. Otherwise, theTAG_CONTENTis invalid. - A start tag is unmatched if no end tag exists with the same TAG_NAME, and vice versa. However, you also need to consider the issue of unbalanced when tags are nested.
- A
<is unmatched if you cannot find a subsequent>. And when you find a<or</, all the subsequent characters until the next>should be parsed as TAG_NAME (not necessarily valid). - The cdata has the following format :
<![CDATA[CDATA_CONTENT]]>. The range ofCDATA_CONTENTis defined as the characters between<![CDATA[and the first subsequent]]>. CDATA_CONTENTmay contain any characters. The function of cdata is to forbid the validator to parseCDATA_CONTENT, so even it has some characters that can be parsed as tag (no matter valid or invalid), you should treat it as regular characters.
Valid Code Examples:
Input: "<DIV>This is the first line <![CDATA[<div>]]></DIV>"
Output: True
Explanation:
The code is wrapped in a closed tag : <DIV> and </DIV>.
The TAG_NAME is valid, the TAG_CONTENT consists of some characters and cdata.
Although CDATA_CONTENT has unmatched start tag with invalid TAG_NAME, it should be considered as plain text, not parsed as tag.
So TAG_CONTENT is valid, and then the code is valid. Thus return true.
Input: "<DIV>>> ![cdata[]] <![CDATA[<div>]>]]>]]>>]</DIV>"
Output: True
Explanation:
We first separate the code into : start_tag|tag_content|end_tag.
start_tag -> "<DIV>"
end_tag -> "</DIV>"
tag_content could also be separated into : text1|cdata|text2.
text1 -> ">> ![cdata[]] "
cdata -> "<![CDATA[<div>]>]]>", where the CDATA_CONTENT is "<div>]>"
text2 -> "]]>>]"
The reason why start_tag is NOT "<DIV>>>" is because of the rule 6. The reason why cdata is NOT "<![CDATA[<div>]>]]>]]>" is because of the rule 7.
Invalid Code Examples:
Input: "<A> <B> </A> </B>" Output: False Explanation: Unbalanced. If "<A>" is closed, then "<B>" must be unmatched, and vice versa. Input: "<DIV> div tag is not closed <DIV>" Output: False Input: "<DIV> unmatched < </DIV>" Output: False Input: "<DIV> closed tags with invalid tag name <b>123</b> </DIV>" Output: False Input: "<DIV> unmatched tags with invalid tag name </1234567890> and <CDATA[[]]> </DIV>" Output: False Input: "<DIV> unmatched start tag <B> and unmatched end tag </C> </DIV>" Output: False
Note:
- For simplicity, you could assume the input code (including the any characters mentioned above) only contain
letters,digits,'<','>','/','!','[',']'and' '.
解题思路:
Given a string representing an expression of fraction addition and subtraction, you need to return the calculation result in string format. The final result should be irreducible fraction. If your final result is an integer, say 2, you need to change it to the format of fraction that has denominator 1. So in this case, 2 should be converted to 2/1.
Example 1:
Input:"-1/2+1/2" Output: "0/1"
Example 2:
Input:"-1/2+1/2+1/3" Output: "1/3"
Example 3:
Input:"1/3-1/2" Output: "-1/6"
Example 4:
Input:"5/3+1/3" Output: "2/1"
Note:
- The input string only contains
'0'to'9','/','+'and'-'. So does the output. - Each fraction (input and output) has format
±numerator/denominator. If the first input fraction or the output is positive, then'+'will be omitted. - The input only contains valid irreducible fractions, where the numerator and denominator of each fraction will always be in the range [1,10]. If the denominator is 1, it means this fraction is actually an integer in a fraction format defined above.
- The number of given fractions will be in the range [1,10].
- The numerator and denominator of the final result are guaranteed to be valid and in the range of 32-bit int.
Given the coordinates of four points in 2D space, return whether the four points could construct a square.
The coordinate (x,y) of a point is represented by an integer array with two integers.
Example:
Input: p1 = [0,0], p2 = [1,1], p3 = [1,0], p4 = [0,1] Output: True
Note:
- All the input integers are in the range [-10000, 10000].
- A valid square has four equal sides with positive length and four equal angles (90-degree angles).
- Input points have no order.
We define a harmonious array is an array where the difference between its maximum value and its minimum value is exactly 1.
Now, given an integer array, you need to find the length of its longest harmonious subsequence among all its possible subsequences.
Example 1:
Input: [1,3,2,2,5,2,3,7] Output: 5 Explanation: The longest harmonious subsequence is [3,2,2,2,3].
Note: The length of the input array will not exceed 20,000.
Given an m * n matrix M initialized with all 0's and several update operations.
Operations are represented by a 2D array, and each operation is represented by an array with two positive integers a and b, which means M[i][j] should be added by one for all 0 <= i < a and 0 <= j < b.
You need to count and return the number of maximum integers in the matrix after performing all the operations.
Example 1:
Input: m = 3, n = 3 operations = [[2,2],[3,3]] Output: 4 Explanation: Initially, M = [[0, 0, 0], [0, 0, 0], [0, 0, 0]] After performing [2,2], M = [[1, 1, 0], [1, 1, 0], [0, 0, 0]] After performing [3,3], M = [[2, 2, 1], [2, 2, 1], [1, 1, 1]] So the maximum integer in M is 2, and there are four of it in M. So return 4.
Note:
- The range of m and n is [1,40000].
- The range of a is [1,m], and the range of b is [1,n].
- The range of operations size won't exceed 10,000.
Suppose Andy and Doris want to choose a restaurant for dinner, and they both have a list of favorite restaurants represented by strings.
You need to help them find out their common interest with the least list index sum. If there is a choice tie between answers, output all of them with no order requirement. You could assume there always exists an answer.
Example 1:
Input: ["Shogun", "Tapioca Express", "Burger King", "KFC"] ["Piatti", "The Grill at Torrey Pines", "Hungry Hunter Steakhouse", "Shogun"] Output: ["Shogun"] Explanation: The only restaurant they both like is "Shogun".
Example 2:
Input: ["Shogun", "Tapioca Express", "Burger King", "KFC"] ["KFC", "Shogun", "Burger King"] Output: ["Shogun"] Explanation: The restaurant they both like and have the least index sum is "Shogun" with index sum 1 (0+1).
Note:
- The length of both lists will be in the range of [1, 1000].
- The length of strings in both lists will be in the range of [1, 30].
- The index is starting from 0 to the list length minus 1.
- No duplicates in both lists.
解题思路:
Given a positive integer n, find the number of non-negative integers less than or equal to n, whose binary representations do NOT contain consecutive ones.
Example 1:
Input: 5 Output: 5 Explanation: Here are the non-negative integers <= 5 with their corresponding binary representations: 0 : 0 1 : 1 2 : 10 3 : 11 4 : 100 5 : 101 Among them, only integer 3 disobeys the rule (two consecutive ones) and the other 5 satisfy the rule.
Note: 1 <= n <= 109
解题思路:
Suppose you have a long flowerbed in which some of the plots are planted and some are not. However, flowers cannot be planted in adjacent plots - they would compete for water and both would die.
Given a flowerbed (represented as an array containing 0 and 1, where 0 means empty and 1 means not empty), and a number n, return if n new flowers can be planted in it without violating the no-adjacent-flowers rule.
Example 1:
Input: flowerbed = [1,0,0,0,1], n = 1 Output: True
Example 2:
Input: flowerbed = [1,0,0,0,1], n = 2 Output: False
Note:
- The input array won't violate no-adjacent-flowers rule.
- The input array size is in the range of [1, 20000].
- n is a non-negative integer which won't exceed the input array size.
解题思路:
You need to construct a string consists of parenthesis and integers from a binary tree with the preorder traversing way.
The null node needs to be represented by empty parenthesis pair "()". And you need to omit all the empty parenthesis pairs that don't affect the one-to-one mapping relationship between the string and the original binary tree.
Example 1:
Input: Binary tree: [1,2,3,4]
1
/
2 3
/
4
Output: "1(2(4))(3)"
Explanation: Originallay it needs to be "1(2(4)())(3()())",
but you need to omit all the unnecessary empty parenthesis pairs.
And it will be "1(2(4))(3)".
Example 2:
Input: Binary tree: [1,2,3,null,4]
1
/
2 3
4
Output: "1(2()(4))(3)"
Explanation: Almost the same as the first example,
except we can't omit the first parenthesis pair to break the one-to-one mapping relationship between the input and the output.
解题思路:
Given a list of directory info including directory path, and all the files with contents in this directory, you need to find out all the groups of duplicate files in the file system in terms of their paths.
A group of duplicate files consists of at least two files that have exactly the same content.
A single directory info string in the input list has the following format:
"root/d1/d2/.../dm f1.txt(f1_content) f2.txt(f2_content) ... fn.txt(fn_content)"
It means there are n files (f1.txt, f2.txt ... fn.txt with content f1_content, f2_content ... fn_content, respectively) in directory root/d1/d2/.../dm. Note that n >= 1 and m >= 0. If m = 0, it means the directory is just the root directory.
The output is a list of group of duplicate file paths. For each group, it contains all the file paths of the files that have the same content. A file path is a string that has the following format:
"directory_path/file_name.txt"
Example 1:
Input: ["root/a 1.txt(abcd) 2.txt(efgh)", "root/c 3.txt(abcd)", "root/c/d 4.txt(efgh)", "root 4.txt(efgh)"] Output: [["root/a/2.txt","root/c/d/4.txt","root/4.txt"],["root/a/1.txt","root/c/3.txt"]]
Note:
- No order is required for the final output.
- You may assume the directory name, file name and file content only has letters and digits, and the length of file content is in the range of [1,50].
- The number of files given is in the range of [1,20000].
- You may assume no files or directories share the same name in the same directory.
- You may assume each given directory info represents a unique directory. Directory path and file info are separated by a single blank space.
- Imagine you are given a real file system, how will you search files? DFS or BFS?
- If the file content is very large (GB level), how will you modify your solution?
- If you can only read the file by 1kb each time, how will you modify your solution?
- What is the time complexity of your modified solution? What is the most time-consuming part and memory consuming part of it? How to optimize?
- How to make sure the duplicated files you find are not false positive?
解题思路:
Given an array consists of non-negative integers, your task is to count the number of triplets chosen from the array that can make triangles if we take them as side lengths of a triangle.
Example 1:
Input: [2,2,3,4] Output: 3 Explanation: Valid combinations are: 2,3,4 (using the first 2) 2,3,4 (using the second 2) 2,2,3
Note:
- The length of the given array won't exceed 1000.
- The integers in the given array are in the range of [0, 1000].
解题思路:
Given two binary trees and imagine that when you put one of them to cover the other, some nodes of the two trees are overlapped while the others are not.
You need to merge them into a new binary tree. The merge rule is that if two nodes overlap, then sum node values up as the new value of the merged node. Otherwise, the NOT null node will be used as the node of new tree.
Example 1:
Input:
Tree 1 Tree 2
1 2
/ /
3 2 1 3
/
5 4 7
Output:
Merged tree:
3
/
4 5
/
5 4 7
解题思路:
1. 使用递归的方法来构造两个树合成的树,如果对应的结点都为NULL,那么返回NULL;如果只有一个为NULL,那么将根结点赋为另一个结点的val值;如果两个都不为NULL,那么将两个结点之和赋给根结点。再递归调用原函数求其左子树和右子树,由于NULL结点的左子结点和右子结点都不存在,因此需要分情况,将参数直接赋为NULL。
621. Task Scheduler
Given a char array representing tasks CPU need to do. It contains capital letters A to Z where different letters represent different tasks.Tasks could be done without original order. Each task could be done in one interval. For each interval, CPU could finish one task or just be idle.
However, there is a non-negative cooling interval n that means between two same tasks, there must be at least n intervals that CPU are doing different tasks or just be idle.
You need to return the least number of intervals the CPU will take to finish all the given tasks.
Example 1:
Input: tasks = ['A','A','A','B','B','B'], n = 2 Output: 8 Explanation: A -> B -> idle -> A -> B -> idle -> A -> B.
Note:
- The number of tasks is in the range [1, 10000].
- The integer n is in the range [0, 100].
Given the root of a binary tree, then value v and depth d, you need to add a row of nodes with value v at the given depth d. The root node is at depth 1.
The adding rule is: given a positive integer depth d, for each NOT null tree nodes N in depth d-1, create two tree nodes with value v as N's left subtree root and right subtree root. And N's original left subtree should be the left subtree of the new left subtree root, its original right subtree should be the right subtree of the new right subtree root. If depth d is 1 that means there is no depth d-1 at all, then create a tree node with value v as the new root of the whole original tree, and the original tree is the new root's left subtree.
Example 1:
Input:
A binary tree as following:
4
/
2 6
/ /
3 1 5
v = 1
d = 2
Output:
4
/
1 1
/
2 6
/ /
3 1 5
Example 2:
Input:
A binary tree as following:
4
/
2
/
3 1
v = 1
d = 3
Output:
4
/
2
/
1 1
/
3 1
Note:
- The given d is in range [1, maximum depth of the given tree + 1].
- The given binary tree has at least one tree node.
解题思路:
Given an integer array, find three numbers whose product is maximum and output the maximum product.
Example 1:
Input: [1,2,3] Output: 6
Example 2:
Input: [1,2,3,4] Output: 24
Note:
- The length of the given array will be in range [3,104] and all elements are in the range [-1000, 1000].
- Multiplication of any three numbers in the input won't exceed the range of 32-bit signed integer.
解题思路:
Given two integers n and k, find how many different arrays consist of numbers from 1 to n such that there are exactly k inverse pairs.
We define an inverse pair as following: For ith and jth element in the array, if i < j and a[i] > a[j] then it's an inverse pair; Otherwise, it's not.
Since the answer may be very large, the answer should be modulo 109 + 7.
Example 1:
Input: n = 3, k = 0 Output: 1 Explanation: Only the array [1,2,3] which consists of numbers from 1 to 3 has exactly 0 inverse pair.
Example 2:
Input: n = 3, k = 1 Output: 2 Explanation: The array [1,3,2] and [2,1,3] have exactly 1 inverse pair.
Note:
- The integer
nis in the range [1, 1000] andkis in the range [0, 1000].
解题思路:
There are n different online courses numbered from 1 to n. Each course has some duration(course length) t and closed on dthday. A course should be taken continuously for t days and must be finished before or on the dth day. You will start at the 1st day.
Given n online courses represented by pairs (t,d), your task is to find the maximal number of courses that can be taken.
Example:
Input: [[100, 200], [200, 1300], [1000, 1250], [2000, 3200]] Output: 3 Explanation: There're totally 4 courses, but you can take 3 courses at most: First, take the 1st course, it costs 100 days so you will finish it on the 100th day, and ready to take the next course on the 101st day. Second, take the 3rd course, it costs 1000 days so you will finish it on the 1100th day, and ready to take the next course on the 1101st day. Third, take the 2nd course, it costs 200 days so you will finish it on the 1300th day. The 4th course cannot be taken now, since you will finish it on the 3300th day, which exceeds the closed date.
Note:
- The integer 1 <= d, t, n <= 10,000.
- You can't take two courses simultaneously.
解题思路:
You have k lists of sorted integers in ascending order. Find the smallest range that includes at least one number from each of the klists.
We define the range [a,b] is smaller than range [c,d] if b-a < d-c or a < c if b-a == d-c.
Example 1:
Input:[[4,10,15,24,26], [0,9,12,20], [5,18,22,30]] Output: [20,24] Explanation: List 1: [4, 10, 15, 24,26], 24 is in range [20,24]. List 2: [0, 9, 12, 20], 20 is in range [20,24]. List 3: [5, 18, 22, 30], 22 is in range [20,24].
Note:
- The given list may contain duplicates, so ascending order means >= here.
- 1 <=
k<= 3500 - -105 <=
value of elements<= 105. - For Java users, please note that the input type has been changed to List<List<Integer>>. And after you reset the code template, you'll see this point.
Given a non-negative integer c, your task is to decide whether there're two integers a and b such that a2 + b2 = c.
Example 1:
Input: 5 Output: True Explanation: 1 * 1 + 2 * 2 = 5
Example 2:
Input: 3 Output: False
解题思路:
Given the running logs of n functions that are executed in a nonpreemptive single threaded CPU, find the exclusive time of these functions.
Each function has a unique id, start from 0 to n-1. A function may be called recursively or by another function.
A log is a string has this format : function_id:start_or_end:timestamp. For example, "0:start:0" means function 0 starts from the very beginning of time 0. "0:end:0" means function 0 ends to the very end of time 0.
Exclusive time of a function is defined as the time spent within this function, the time spent by calling other functions should not be considered as this function's exclusive time. You should return the exclusive time of each function sorted by their function id.
Example 1:
Input: n = 2 logs = ["0:start:0", "1:start:2", "1:end:5", "0:end:6"] Output:[3, 4] Explanation: Function 0 starts at time 0, then it executes 2 units of time and reaches the end of time 1. Now function 0 calls function 1, function 1 starts at time 2, executes 4 units of time and end at time 5. Function 0 is running again at time 6, and also end at the time 6, thus executes 1 unit of time. So function 0 totally execute 2 + 1 = 3 units of time, and function 1 totally execute 4 units of time.
Note:
- Input logs will be sorted by timestamp, NOT log id.
- Your output should be sorted by function id, which means the 0th element of your output corresponds to the exclusive time of function 0.
- Two functions won't start or end at the same time.
- Functions could be called recursively, and will always end.
- 1 <= n <= 100
解题思路:
Given a non-empty binary tree, return the average value of the nodes on each level in the form of an array.
Example 1:
Input:
3
/
9 20
/
15 7
Output: [3, 14.5, 11]
Explanation:
The average value of nodes on level 0 is 3, on level 1 is 14.5, and on level 2 is 11. Hence return [3, 14.5, 11].
Note:
- The range of node's value is in the range of 32-bit signed integer.
解题思路:
In LeetCode Store, there are some kinds of items to sell. Each item has a price.
However, there are some special offers, and a special offer consists of one or more different kinds of items with a sale price.
You are given the each item's price, a set of special offers, and the number we need to buy for each item. The job is to output the lowest price you have to pay for exactly certain items as given, where you could make optimal use of the special offers.
Each special offer is represented in the form of an array, the last number represents the price you need to pay for this special offer, other numbers represents how many specific items you could get if you buy this offer.
You could use any of special offers as many times as you want.
Example 1:
Input: [2,5], [[3,0,5],[1,2,10]], [3,2] Output: 14 Explanation: There are two kinds of items, A and B. Their prices are $2 and $5 respectively. In special offer 1, you can pay $5 for 3A and 0B In special offer 2, you can pay $10 for 1A and 2B. You need to buy 3A and 2B, so you may pay $10 for 1A and 2B (special offer #2), and $4 for 2A.
Example 2:
Input: [2,3,4], [[1,1,0,4],[2,2,1,9]], [1,2,1] Output: 11 Explanation: The price of A is $2, and $3 for B, $4 for C. You may pay $4 for 1A and 1B, and $9 for 2A ,2B and 1C. You need to buy 1A ,2B and 1C, so you may pay $4 for 1A and 1B (special offer #1), and $3 for 1B, $4 for 1C. You cannot add more items, though only $9 for 2A ,2B and 1C.
Note:
- There are at most 6 kinds of items, 100 special offers.
- For each item, you need to buy at most 6 of them.
- You are not allowed to buy more items than you want, even if that would lower the overall price.
解题思路:
A message containing letters from A-Z is being encoded to numbers using the following mapping way:
'A' -> 1 'B' -> 2 ... 'Z' -> 26
Beyond that, now the encoded string can also contain the character '*', which can be treated as one of the numbers from 1 to 9.
Given the encoded message containing digits and the character '*', return the total number of ways to decode it.
Also, since the answer may be very large, you should return the output mod 109 + 7.
Example 1:
Input: "*" Output: 9 Explanation: The encoded message can be decoded to the string: "A", "B", "C", "D", "E", "F", "G", "H", "I".
Example 2:
Input: "1*" Output: 9 + 9 = 18
Note:
- The length of the input string will fit in range [1, 105].
- The input string will only contain the character '*' and digits '0' - '9'.
解题思路:
Solve a given equation and return the value of x in the form of string "x=#value". The equation contains only '+', '-' operation, the variable x and its coefficient.
If there is no solution for the equation, return "No solution".
If there are infinite solutions for the equation, return "Infinite solutions".
If there is exactly one solution for the equation, we ensure that the value of x is an integer.
Example 1:
Input: "x+5-3+x=6+x-2" Output: "x=2"
Example 2:
Input: "x=x" Output: "Infinite solutions"
Example 3:
Input: "2x=x" Output: "x=0"
Example 4:
Input: "2x+3x-6x=x+2" Output: "x=-1"
Example 5:
Input: "x=x+2" Output: "No solution"
解题思路:
Given an array consisting of n integers, find the contiguous subarray of given length k that has the maximum average value. And you need to output the maximum average value.
Example 1:
Input: [1,12,-5,-6,50,3], k = 4 Output: 12.75 Explanation: Maximum average is (12-5-6+50)/4 = 51/4 = 12.75
Note:
- 1 <=
k<=n<= 30,000. - Elements of the given array will be in the range [-10,000, 10,000].
Given an array consisting of n integers, find the contiguous subarray whose length is greater than or equal to k that has the maximum average value. And you need to output the maximum average value.
Example 1:
Input: [1,12,-5,-6,50,3], k = 4 Output: 12.75 Explanation: when length is 5, maximum average value is 10.8, when length is 6, maximum average value is 9.16667. Thus return 12.75.
Note:
- 1 <=
k<=n<= 10,000. - Elements of the given array will be in range [-10,000, 10,000].
- The answer with the calculation error less than 10-5 will be accepted.
解题思路: