看了有两三个爬虫程序了,就自己写了一个简单的爬虫程序感受一下,爬取的是:猫眼电影-榜单-热映口碑榜11月6号的数据
from urllib import request import re def getHtml(url, ua_agent='Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:61.0) Gecko'): headers = {"User-Agent":ua_agent} req = request.Request(url, headers=headers) response = request.urlopen(req) html = response.read().decode('utf-8') return html def movie_all(html): pattern = re.compile('<p class="name"[sS]*?title="([sS]*?)"[sS]*?<p class="star">([sS]*?)</p>[sS]*?<p class="releasetime">([sS]*?)</p>') items = re.findall(pattern, html) return items def write_to_file(text): with open("maoyanTop10.txt", 'a') as f: f.write(text+' ') if __name__ == "__main__": url = "https://maoyan.com/board/7" items = movie_all(getHtml(url)) for item in items: write_to_file(item[0].strip()+"||"+item[1].strip()+"||"+item[2].strip())
效果: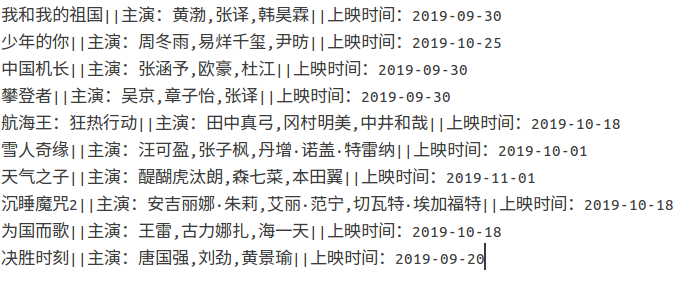
小知识点:1.用正则表达式匹配时,有的地方看着没空格,实际上有空字符串,需要用万能表达式([sS]*?)顶替,例如上一个p标记的</p>到下一个p标记的<p>中间就需要要万能表达式。pattern = re.compile('.',re.S)和pattern = re.compile('[sS]')等效。
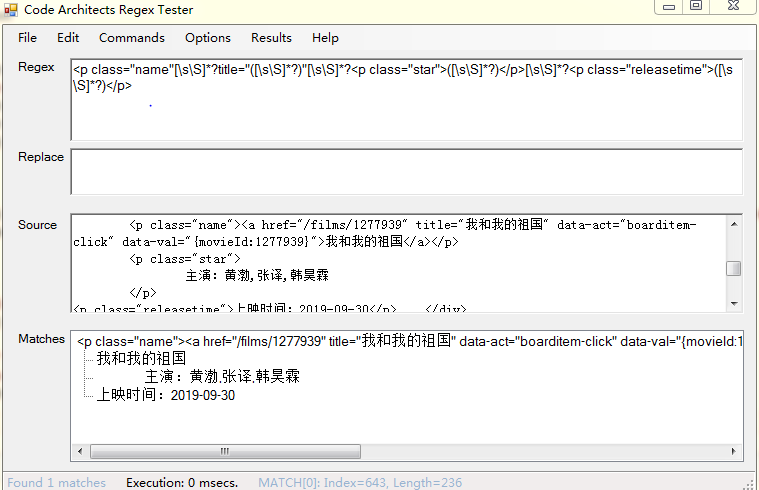
2.在写文件时,如果在循环中写文件要以“a”(追加)的方式打开文件,如果以“w”(写入)打开,只会看到写入了最后一次循环的数据,因为“w”方式会清掉之前的数据再写入。