再顺便多写一篇PE文件的文章吧,这一篇文章介绍PE文件的导出表。导出表相对来说应该算最简单的,它的关键结构只有一个。本质上导出表的dir只是指示以下信息,dll的名称地址(ANSI字符串),有多少个导出函数,对导出函数有三个数组,分别是序号数组,函数名称(ANSI字符串)地址数组,函数入口地址(RVA)数组。导入表导出表可以说是直接和动态链接技术相关的 DataDirectory 了。
首先还是介绍导出表的唯一一个数据结构(仅列出比较关键的成员):
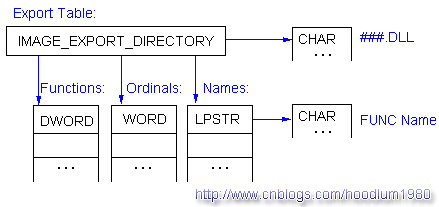
(1)IMAGE_EXPORT_DIRECTORY:
(1.1)DWORD Name; 这个DLL名称(ANSI)字符串的地址(RVA)。
(1.2)DWORD Base; 序号数组的计数起始值。(序号数组中的数值加上Base为最终的导出函数序号)
(1.3)DWORD NumberOfFunctions; 导出函数个数。
(1.4)DWORD NumberOfNames; 函数名个数。这个值通常应该和 NumberOfFunctions 相同(即所有导出函数都应该有一个名称)。
(1.5)DWORD AddressOfFunctions; 函数地址RVA的数组。
(1.6)DWORD AddressOfNames; 存储函数名称(ANSI)字符串的地址(RVA)的数组的地址(RVA)。
(1.7)DWORD AddressOfNameOrdinals; 存储函数序号的数组的地址(RVA)。
按照惯例,下面是导出表的结构示意图:
下面是读取导入表的代码,由于我的项目属性中使用的是unicode字符串,所以我在使用那些ANSI字符串之前,需要做一次到unicode的转换:
 code_load_exportTable
code_load_exportTable

void CPERcViewDlg::LoadExportTable(LPBYTE lpBaseAddress, PIMAGE_NT_HEADERS pNtHeaders, DWORD rva)
{
int i;
TCHAR wcsBuffer[256], nodeText[256];
HTREEITEM hItem_Export = NULL;
PIMAGE_EXPORT_DIRECTORY pExportTable = (PIMAGE_EXPORT_DIRECTORY)ImageRvaToVa(
pNtHeaders,
lpBaseAddress,
rva,
NULL
);
_stprintf(nodeText, _T("ExportTable (FileAddress: %08X)"), (DWORD)pExportTable - (DWORD)lpBaseAddress);
hItem_Export = m_tree.InsertItem(nodeText, TVI_ROOT, TVI_LAST);
//dll名称(char*)
LPCSTR szDllName = (LPCSTR)ImageRvaToVa(
pNtHeaders, lpBaseAddress,
pExportTable->Name,
NULL);
//把ANSI的名称转换到unicode
::MultiByteToWideChar(CP_ACP, MB_PRECOMPOSED, szDllName, -1, nodeText, sizeof(nodeText)/sizeof(TCHAR));
//append dll name node
HTREEITEM hDllName = m_tree.InsertItem(nodeText, hItem_Export, TVI_LAST);
//现在加载每个节点
DWORD ImageBase = pNtHeaders->OptionalHeader.ImageBase;
//以下全部是RVA。换算到数组入口处的VA:
PDWORD pFunctions = (PDWORD)ImageRvaToVa(
pNtHeaders, lpBaseAddress,
pExportTable->AddressOfFunctions,
NULL);
PWORD pOrdinals = (PWORD)ImageRvaToVa(
pNtHeaders, lpBaseAddress,
pExportTable->AddressOfNameOrdinals,
NULL);
BOOL hasNames = (pExportTable->AddressOfNames != 0);
PDWORD pNames = NULL;
if(hasNames)
{
pNames = (PDWORD)ImageRvaToVa(
pNtHeaders, lpBaseAddress,
pExportTable->AddressOfNames,
NULL);
}
for(i=0; i<pExportTable->NumberOfFunctions; i++)
{
//函数名称
if(hasNames)
{
LPCSTR szFuncName = (LPCSTR)ImageRvaToVa(
pNtHeaders, lpBaseAddress,
pNames[i],
NULL);
//转换成unicode
::MultiByteToWideChar(CP_ACP, MB_PRECOMPOSED, szFuncName, -1, wcsBuffer, sizeof(wcsBuffer)/sizeof(TCHAR));
}
_stprintf(nodeText, _T("Ordinal: %ld %s, VA: %08X"),
pExportTable->Base + pOrdinals[i],
hasNames? wcsBuffer : _T("(null)"),
ImageBase + pFunctions[i]
);
m_tree.InsertItem(nodeText, hDllName, TVI_LAST);
}
}
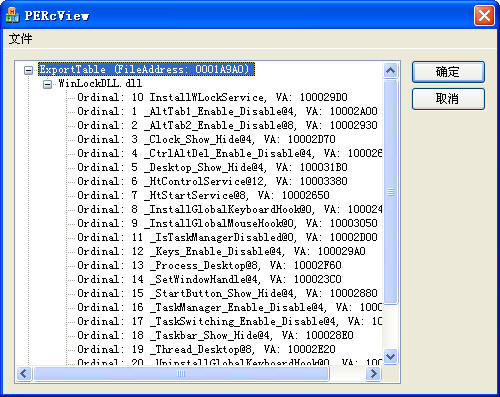
最后导出函数加载到 TreeCtrl 的效果如下:
【补充内容】关于pragma:
(1)指定内容在 obj 文件中所在的段,具体用法参考MSDN(不太常用),以下分别是代码(函数),初始化数据,未初始化数据,常量:
#pragma code_seg( [ [ { push | pop}, ] [ identifier, ] ] [ "segment-name" [, "segment-class" ] )
#pragma data_seg( [ [ { push | pop }, ] [ identifier, ] ] [ "segment-name" [, "segment-class" ] ) #pragma bss_seg( [ [ { push | pop }, ] [ identifier, ] ] [ "segment-name" [, "segment-class" ] )#pragma const_seg( [ [ { push | pop}, ] [ identifier, ] ] [ "segment-name" [, "segment-class" ] )
(2)在某个obj文件中指定一个在链接时需要搜索的库(比较常用):
#pragma comment( lib, "emapi" )
【参考资料】
(1)看雪论坛精华8;
(2)winnt.h;