hadoop2-hive
1.What,Why,How?

1.Hive是数据仓库,在MySQL或其他关系型数据库中存放元数据信息,而把真正的Data存放在HDFS上面。
2.主要使用Hive来对历史数据进行分析。
3.方便非Java开发者(或者没有编程基础的人员),但是会SQL,他们使用SQL对数据进行分析
4.Hive会将SQL转化为MapReduce进行工作。读取在MySQL或其他关系型数据库中存放元数据信息,再读取HDFS中的数据信息进行处理。
2.安装
在安装和测试hive之前,我们需要把Hadoop的所有服务启动
2.1.在安装Hive之前,我们需要安装mysql数据库
--mysql的安装 - (https://segmentfault.com/a/1190000003049498) --检测系统是否自带安装mysql yum list installed | grep mysql --删除系统自带的mysql及其依赖 yum -y remove mysql-libs.x86_64 --给CentOS添加rpm源,并且选择较新的源 wget dev.mysql.com/get/mysql-community-release-el6-5.noarch.rpm yum localinstall mysql-community-release-el6-5.noarch.rpm yum repolist all | grep mysql yum-config-manager --disable mysql55-community yum-config-manager --disable mysql56-community yum-config-manager --enable mysql57-community-dmr yum repolist enabled | grep mysql --安装mysql 服务器 yum install mysql-community-server --启动mysql service mysqld start --查看mysql是否自启动,并且设置开启自启动 chkconfig --list | grep mysqld chkconfig mysqld on --查找初始化密码 grep 'temporary password' /var/log/mysqld.log --mysql安全设置 mysql_secure_installation --启动mysql service mysqld start --登录 mysql –u root –p --设置的密码 !QAZ2wsx3edc --开通远程访问 grant all on *.* to root@'%' identified by '!QAZ2wsx3edc'; select * from mysql.user; --让node1也可以访问 grant all on *.* to root@'node1' identified by '!QAZ2wsx3edc'; --创建hive数据库,后面要用到,hive不会 自动创建 create database hive;
2.2.安装和配置Hive
--安装Hive cd ~ tar -zxvf apache-hive-0.13.1-bin.tar.gz --创建软链 ln -sf /root/apache-hive-0.13.1-bin /home/hive --修改配置文件 cd /home/hive/conf/ cp -a hive-default.xml.template hive-site.xml --启动Hive cd /home/hive/bin/ ./hive --退出hive quit; --修改配置文件 cd /home/hive/conf/ vi hive-site.xml --以下需要修改的地方 <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://node1/hive</value> <description>JDBC connect string for a JDBC metastore</description> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> <description>Driver class name for a JDBC metastore</description> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> <description>username to use against metastore database</description> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>!QAZ2wsx3edc</value> <description>password to use against metastore database</description> </property> :wq
2.3.添加mysql驱动
--拷贝mysql驱动到/home/hive/lib/ cp -a mysql-connector-java-5.1.23-bin.jar /home/hive/lib/
2.4.产生测试数据
在这里我写了一个生成文件的java文件
GenerateTestFile.java
import java.io.BufferedWriter; import java.io.File; import java.io.FileWriter; import java.util.Random; /** * @author Hongwei * @created 31 Oct 2018 */ public class GenerateTestFile { public static void main(String[] args) throws Exception{ int num = 20000000; File writename = new File("/root/output1.txt"); System.out.println("begin"); writename.createNewFile(); BufferedWriter out = new BufferedWriter(new FileWriter(writename)); StringBuilder sBuilder = new StringBuilder(); for(int i=1;i<num;i++){ Random random = new Random(); sBuilder.append(i).append(",").append("name").append(i).append(",") .append(random.nextInt(50)).append(",").append("Sales").append(" "); } System.out.println("done........"); out.write(sBuilder.toString()); out.flush(); out.close(); } }
编译和运行文件:
cd
javac GenerateTestFile.java
java GenerateTestFile
最终就会生成/root/output1.txt文件,为上传测试文件做准备。
2.5.启动Hive
--启动hive
cd /home/hive/bin/
./hive
2.6.创建t_tem2表
create table t_emp2( id int, name string, age int, dept_name string ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
输出结果:
hive> create table t_emp2( > id int, > name string, > age int, > dept_name string > ) > ROW FORMAT DELIMITED > FIELDS TERMINATED BY ','; OK Time taken: 0.083 seconds
2.7.上传文件
load data local inpath '/root/output1.txt' into table t_emp2;
输出结果:
hive> load data local inpath '/root/output1.txt' into table t_emp2; Copying data from file:/root/output1.txt Copying file: file:/root/output1.txt Loading data to table default.t_emp2 Table default.t_emp2 stats: [numFiles=1, numRows=0, totalSize=593776998, rawDataSize=0] OK Time taken: 148.455 seconds
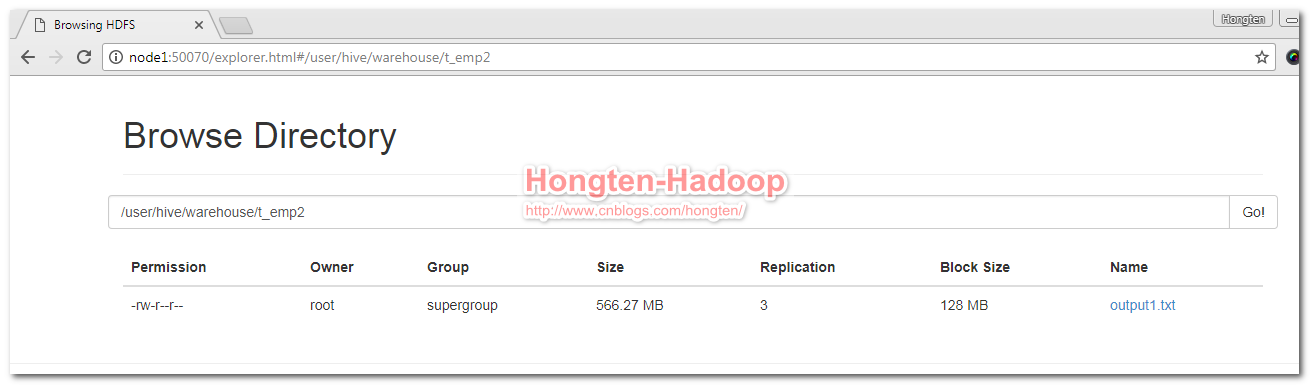

2.8.测试
查看t_temp2表里面所有记录的总条数:
hive> select count(*) from t_emp2; Total jobs = 1 Launching Job 1 out of 1 Number of reduce tasks determined at compile time: 1 In order to change the average load for a reducer (in bytes): set hive.exec.reducers.bytes.per.reducer=<number> In order to limit the maximum number of reducers: set hive.exec.reducers.max=<number> In order to set a constant number of reducers: set mapreduce.job.reduces=<number> Starting Job = job_1541003514112_0002, Tracking URL = http://node1:8088/proxy/application_1541003514112_0002/ Kill Command = /home/hadoop-2.5/bin/hadoop job -kill job_1541003514112_0002 Hadoop job information for Stage-1: number of mappers: 3; number of reducers: 1 2018-10-31 09:41:49,863 Stage-1 map = 0%, reduce = 0% 2018-10-31 09:42:26,846 Stage-1 map = 33%, reduce = 0%, Cumulative CPU 33.56 sec 2018-10-31 09:42:47,028 Stage-1 map = 44%, reduce = 0%, Cumulative CPU 53.03 sec 2018-10-31 09:42:48,287 Stage-1 map = 56%, reduce = 0%, Cumulative CPU 53.79 sec 2018-10-31 09:42:54,173 Stage-1 map = 67%, reduce = 0%, Cumulative CPU 56.99 sec 2018-10-31 09:42:56,867 Stage-1 map = 78%, reduce = 0%, Cumulative CPU 57.52 sec 2018-10-31 09:42:58,201 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 58.44 sec 2018-10-31 09:43:16,966 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 60.62 sec MapReduce Total cumulative CPU time: 1 minutes 0 seconds 620 msec Ended Job = job_1541003514112_0002 MapReduce Jobs Launched: Job 0: Map: 3 Reduce: 1 Cumulative CPU: 60.62 sec HDFS Read: 593794153 HDFS Write: 9 SUCCESS Total MapReduce CPU Time Spent: 1 minutes 0 seconds 620 msec OK 19999999 Time taken: 105.013 seconds, Fetched: 1 row(s)
查询表中age=20的记录总条数:
hive> select count(*) from t_emp2 where age=20; Total jobs = 1 Launching Job 1 out of 1 Number of reduce tasks determined at compile time: 1 In order to change the average load for a reducer (in bytes): set hive.exec.reducers.bytes.per.reducer=<number> In order to limit the maximum number of reducers: set hive.exec.reducers.max=<number> In order to set a constant number of reducers: set mapreduce.job.reduces=<number> Starting Job = job_1541003514112_0003, Tracking URL = http://node1:8088/proxy/application_1541003514112_0003/ Kill Command = /home/hadoop-2.5/bin/hadoop job -kill job_1541003514112_0003 Hadoop job information for Stage-1: number of mappers: 3; number of reducers: 1 2018-10-31 09:44:28,452 Stage-1 map = 0%, reduce = 0% 2018-10-31 09:44:45,102 Stage-1 map = 11%, reduce = 0%, Cumulative CPU 5.54 sec 2018-10-31 09:44:49,318 Stage-1 map = 33%, reduce = 0%, Cumulative CPU 7.63 sec 2018-10-31 09:45:14,247 Stage-1 map = 44%, reduce = 0%, Cumulative CPU 13.97 sec 2018-10-31 09:45:15,274 Stage-1 map = 67%, reduce = 0%, Cumulative CPU 14.99 sec 2018-10-31 09:45:41,594 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 18.7 sec 2018-10-31 09:45:50,973 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 26.08 sec MapReduce Total cumulative CPU time: 26 seconds 80 msec Ended Job = job_1541003514112_0003 MapReduce Jobs Launched: Job 0: Map: 3 Reduce: 1 Cumulative CPU: 33.19 sec HDFS Read: 593794153 HDFS Write: 7 SUCCESS Total MapReduce CPU Time Spent: 33 seconds 190 msec OK 399841 Time taken: 98.693 seconds, Fetched: 1 row(s)
3.hive中的内部表和外部表的区别
--hive中的内部表和外部表的区别 --内部表: --1.创建时需要定制目录 --2.删除时,内部表将表结构和元数据全部删除,外部表只是删除表结构,不会删除元数据 desc formatted table_name; --外部表 Table Type: EXTERNAL_TABLE --内部表 Table Type: MANAGED_TABLE
4.Hive create/drop table
--Hive create table cd /home/hive/bin ./hive create table t_user ( id int, name string, sports array<string>, address map<string, string> ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' COLLECTION ITEMS TERMINATED BY '-' MAP KEYS TERMINATED BY ':' LINES TERMINATED BY ' '; --hive test data vi hive_test_data_t_user 1,Tom,篮球-足球-乒乓球,address1:Orchard Singapore-address2:宁夏 China 2,John,体操-足球-乒乓球,address1:Novena China-address2:新疆 China 3,Jack,篮球-棒球,address1:Newton Singapore-address2:广东 China 4,Hongten,篮球-单杠-滑冰,address1:Bishan Singapore-address2:上海 China 5,Sum,篮球-皮划艇-拳击,address1:Yishun Singapore-address2:辽宁 China 6,Susan,体操-足球-跑步,address1:YCK Singapore-address2:湖南 China 7,Mark,柔术-骑马-骑车,address1:Chinatown Singapore-address2:江西 China :wq cd /home/hive/bin ./hive LOAD DATA LOCAL INPATH '/root/hive_test_data_t_user' INTO TABLE t_user; --创建外部表 create external table t_user_external ( id int, name string, sports array<string>, address map<string, string> ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' COLLECTION ITEMS TERMINATED BY '-' MAP KEYS TERMINATED BY ':' LINES TERMINATED BY ' ' LOCATION '/user/hive/warehouse/t_user_external'; --删除表 drop table t_user; -- drop table t_user_external;
5.hive分区
--hive分区 --为了提高查询的效率,将不同的数据文件存放到不同的目录,查询使可以查询部分目录,分区设计要跟业务相结合 create table t_user_with_partition ( id int, name string, sports array<string>, address map<string, string> ) PARTITIONED BY (age int,gender string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' COLLECTION ITEMS TERMINATED BY '-' MAP KEYS TERMINATED BY ':' LINES TERMINATED BY ' '; load data local inpath '/root/hive_test_data_t_user' into table t_user_with_partition partition(age=24,gender='m'); alter table t_user_with_partition add partition(age=24,gender='f'); alter table t_user_with_partition add partition(age=22,gender='m'); alter table t_user_with_partition add partition(age=22,gender='f'); --删除分区 alter table t_user_with_partition drop partition(age=22,gender='f'); --Hive分区 添加分区的时候,必须在现有分区的基础之上 删除分区的时候,会将所有存在的分区都删除 分区实质上就是加目录
6.hive插入数据
--- create table t_user_view2 ( id int, name string ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LINES TERMINATED BY ' '; from t_user insert overwrite table t_user_view select id, name; --创建table create table t_user_view1 ( id int, name string ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LINES TERMINATED BY ' '; create table t_user_view2 ( id int, name string ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LINES TERMINATED BY ' '; --插入数据 from t_user insert overwrite table t_user_view1 select id, name where id >=1 and id<=4 insert overwrite table t_user_view2 select id, name where id>4; --查询结果 hive> select * from t_user_view1; OK 1 Tom 2 John 3 Jack 4 Hongten Time taken: 0.169 seconds, Fetched: 4 row(s) hive> select * from t_user_view2; OK 5 Sum 6 Susan 7 Mark Time taken: 0.231 seconds, Fetched: 3 row(s)
7.Hive SerDe - Serializer and Deserializer
--Hive SerDe - Serializer and Deserializer --序列号和反序列化 CREATE TABLE t_tomcat_log ( col1 string, col2 string, col3 string, col4 string, col5 string, col6 string, col7 string ) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe' WITH SERDEPROPERTIES ( "input.regex" = "^([0-9.]+) ([\w.-]) ([\w.-]) \[([A-Za-z0-9:/]+ [+-][0-9]{4})\] "(.+?)" ([0-9]{3}) ([0-9]+)$" ) STORED AS TEXTFILE; --Tomcat log --进入node1 cd vi tomcat_log 64.242.88.10 - - [07/Mar/2004:16:06:51 -0800] "GET /twiki/bin/rdiff/TWiki/NewUserTemplate?rev1=1.3&rev2=1.2 HTTP/1.1" 200 4523 64.242.88.10 - - [07/Mar/2004:16:06:51 -0800] "GET /twiki/bin/rdiff/TWiki/NewUserTemplate?rev1=1.3&rev2=1.2 HTTP/1.1" 200 4523 64.242.88.10 - - [07/Mar/2004:16:06:51 -0800] "GET /twiki/bin/rdiff/TWiki/NewUserTemplate?rev1=1.3&rev2=1.2 HTTP/1.1" 200 4523 64.242.88.10 - - [07/Mar/2004:16:06:51 -0800] "GET /twiki/bin/rdiff/TWiki/NewUserTemplate?rev1=1.3&rev2=1.2 HTTP/1.1" 200 4523 64.242.88.10 - - [07/Mar/2004:16:06:51 -0800] "GET /twiki/bin/rdiff/TWiki/NewUserTemplate?rev1=1.3&rev2=1.2 HTTP/1.1" 200 4523 64.242.88.10 - - [07/Mar/2004:16:06:51 -0800] "GET /twiki/bin/rdiff/TWiki/NewUserTemplate?rev1=1.3&rev2=1.2 HTTP/1.1" 200 4523 :wq --载入数据 load data local inpath '/root/tomcat_log' into table t_tomcat_log; --查询数据 hive> select * from t_tomcat_log; OK 64.242.88.10 - - 07/Mar/2004:16:06:51 -0800 GET /twiki/bin/rdiff/TWiki/NewUserTemplate?rev1=1.3&rev2=1.2 HTTP/1.1 200 4523 64.242.88.10 - - 07/Mar/2004:16:06:51 -0800 GET /twiki/bin/rdiff/TWiki/NewUserTemplate?rev1=1.3&rev2=1.2 HTTP/1.1 200 4523 64.242.88.10 - - 07/Mar/2004:16:06:51 -0800 GET /twiki/bin/rdiff/TWiki/NewUserTemplate?rev1=1.3&rev2=1.2 HTTP/1.1 200 4523 64.242.88.10 - - 07/Mar/2004:16:06:51 -0800 GET /twiki/bin/rdiff/TWiki/NewUserTemplate?rev1=1.3&rev2=1.2 HTTP/1.1 200 4523 64.242.88.10 - - 07/Mar/2004:16:06:51 -0800 GET /twiki/bin/rdiff/TWiki/NewUserTemplate?rev1=1.3&rev2=1.2 HTTP/1.1 200 4523 64.242.88.10 - - 07/Mar/2004:16:06:51 -0800 GET /twiki/bin/rdiff/TWiki/NewUserTemplate?rev1=1.3&rev2=1.2 HTTP/1.1 200 4523 Time taken: 0.087 seconds, Fetched: 6 row(s)
8.Hive Beeline
--Hive Beeline --使用Beeline的时候,需要启动hiveserver2 cd /home/hive/bin/ ./hiveserver2 & [root@node1 bin]# ./hiveserver2 & [1] 5371 [root@node1 bin]# Starting HiveServer2 19/01/09 21:46:59 WARN conf.HiveConf: DEPRECATED: hive.metastore.ds.retry.* no longer has any effect. Use hive.hmshandler.retry.* instead SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/root/hadoop-2.5.1/share/hadoop/common/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/root/apache-hive-0.13.1-bin/lib/slf4j-log4j12-1.6.4.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory] --查询hiveserver2进程 netstat -lnp|grep 10000 [root@node1 bin]# netstat -lnp|grep 10000 tcp 0 0 127.0.0.1:10000 0.0.0.0:* LISTEN 5371/java --关闭hiveserver2 kill -9 5371 --客户的通过beeline两种方式连接到hive --第一种方式:这种跟我们平常使用的MySQL命令行差不多,查查来的数据都是很规范的 cd /home/hive/bin/ ./beeline -u jdbc:hive2://localhost:10000/default -n root [root@node1 bin]# ./beeline -u jdbc:hive2://localhost:10000/default -n root scan complete in 3ms Connecting to jdbc:hive2://localhost:10000/default SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/root/hadoop-2.5.1/share/hadoop/common/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/root/apache-hive-0.13.1-bin/lib/slf4j-log4j12-1.6.4.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory] Connected to: Apache Hive (version 0.13.1) Driver: Hive JDBC (version 0.13.1) Transaction isolation: TRANSACTION_REPEATABLE_READ Beeline version 0.13.1 by Apache Hive 0: jdbc:hive2://localhost:10000/default> show tables; OK +---------------------------------+ | tab_name | +---------------------------------+ | hive_access_hbase_table_t_user | | infos | | t_emp | | t_emp1 | | t_emp2 | | t_sqoop_mysql_t_user_to_hive | | t_tomcat_log | | t_user | | t_user_external | | t_user_view | | t_user_view1 | | t_user_view2 | | t_user_with_partition | | tmp_order | +---------------------------------+ 14 rows selected (0.868 seconds) 0: jdbc:hive2://localhost:10000/default> select * from t_user; OK +------------+--------------+--------------------+-----------------------------------------------------------+ | t_user.id | t_user.name | t_user.sports | t_user.address | +------------+--------------+--------------------+-----------------------------------------------------------+ | 1 | Tom | ["篮球","足球","乒乓球"] | {"address1":"Orchard Singapore","address2":"宁夏 China"} | | 2 | John | ["体操","足球","乒乓球"] | {"address1":"Novena China","address2":"新疆 China"} | | 3 | Jack | ["篮球","棒球"] | {"address1":"Newton Singapore","address2":"广东 China"} | | 4 | Hongten | ["篮球","单杠","滑冰"] | {"address1":"Bishan Singapore","address2":"上海 China"} | | 5 | Sum | ["篮球","皮划艇","拳击"] | {"address1":"Yishun Singapore","address2":"辽宁 China"} | | 6 | Susan | ["体操","足球","跑步"] | {"address1":"YCK Singapore","address2":"湖南 China"} | | 7 | Mark | ["柔术","骑马","骑车"] | {"address1":"Chinatown Singapore","address2":"江西 China"} | +------------+--------------+--------------------+-----------------------------------------------------------+ 7 rows selected (0.695 seconds) 0: jdbc:hive2://localhost:10000/default> select * from t_tomcat_log; OK +--------------------+--------------------+--------------------+-----------------------------+------------------------------------------------------------------------+--------------------+--+ | t_tomcat_log.col1 | t_tomcat_log.col2 | t_tomcat_log.col3 | t_tomcat_log.col4 | t_tomcat_log.col5 | t_tomcat_log.col6 | | +--------------------+--------------------+--------------------+-----------------------------+------------------------------------------------------------------------+--------------------+--+ | 64.242.88.10 | - | - | 07/Mar/2004:16:06:51 -0800 | GET /twiki/bin/rdiff/TWiki/NewUserTemplate?rev1=1.3&rev2=1.2 HTTP/1.1 | 200 | | | 64.242.88.10 | - | - | 07/Mar/2004:16:06:51 -0800 | GET /twiki/bin/rdiff/TWiki/NewUserTemplate?rev1=1.3&rev2=1.2 HTTP/1.1 | 200 | | | 64.242.88.10 | - | - | 07/Mar/2004:16:06:51 -0800 | GET /twiki/bin/rdiff/TWiki/NewUserTemplate?rev1=1.3&rev2=1.2 HTTP/1.1 | 200 | | | 64.242.88.10 | - | - | 07/Mar/2004:16:06:51 -0800 | GET /twiki/bin/rdiff/TWiki/NewUserTemplate?rev1=1.3&rev2=1.2 HTTP/1.1 | 200 | | | 64.242.88.10 | - | - | 07/Mar/2004:16:06:51 -0800 | GET /twiki/bin/rdiff/TWiki/NewUserTemplate?rev1=1.3&rev2=1.2 HTTP/1.1 | 200 | | | 64.242.88.10 | - | - | 07/Mar/2004:16:06:51 -0800 | GET /twiki/bin/rdiff/TWiki/NewUserTemplate?rev1=1.3&rev2=1.2 HTTP/1.1 | 200 | | +--------------------+--------------------+--------------------+-----------------------------+------------------------------------------------------------------------+--------------------+--+ 6 rows selected (0.132 seconds) --退出操作 !quit 0: jdbc:hive2://localhost:10000/default> !quit Closing: 0: jdbc:hive2://localhost:10000/default --第二种方式 ./beeline !connect jdbc:hive2://localhost:10000/default -n root [root@node1 bin]# ./beeline Beeline version 0.13.1 by Apache Hive beeline> !connect jdbc:hive2://localhost:10000/default -n root scan complete in 4ms Connecting to jdbc:hive2://localhost:10000/default SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/root/hadoop-2.5.1/share/hadoop/common/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/root/apache-hive-0.13.1-bin/lib/slf4j-log4j12-1.6.4.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory] Connected to: Apache Hive (version 0.13.1) Driver: Hive JDBC (version 0.13.1) Transaction isolation: TRANSACTION_REPEATABLE_READ 0: jdbc:hive2://localhost:10000/default> show tables; OK +---------------------------------+ | tab_name | +---------------------------------+ | hive_access_hbase_table_t_user | | infos | | t_emp | | t_emp1 | | t_emp2 | | t_sqoop_mysql_t_user_to_hive | | t_tomcat_log | | t_user | | t_user_external | | t_user_view | | t_user_view1 | | t_user_view2 | | t_user_with_partition | | tmp_order | +---------------------------------+ 14 rows selected (0.214 seconds)
9.Hive 函数
--Hive 函数 UDF - 一进一出 UDAF - 多进一出 UDTF - 一进多出 --自定义function create table t_score( name string, course string, score int ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LINES TERMINATED BY ' '; --测试数据 cd vi rowToColumn Tom,English,90 Tom,Math,78 Tom,Science,89 John,English,65 John,Math,42 John,Science,100 Susan,English,68 Susan,Math,89 Susan,Science,37 --加载数据 load data local inpath '/root/rowToColumn' into table t_score; --查看原始数据 hive> select name, course, score from t_score; Total jobs = 1 Launching Job 1 out of 1 Number of reduce tasks is set to 0 since there's no reduce operator Starting Job = job_1547093703749_0016, Tracking URL = http://node1:8088/proxy/application_1547093703749_0016/ Kill Command = /home/hadoop-2.5/bin/hadoop job -kill job_1547093703749_0016 Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0 2019-01-10 01:53:31,460 Stage-1 map = 0%, reduce = 0% 2019-01-10 01:53:44,443 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 2.59 sec MapReduce Total cumulative CPU time: 2 seconds 590 msec Ended Job = job_1547093703749_0016 MapReduce Jobs Launched: Job 0: Map: 1 Cumulative CPU: 2.59 sec HDFS Read: 346 HDFS Write: 136 SUCCESS Total MapReduce CPU Time Spent: 2 seconds 590 msec OK Tom English 90 Tom Math 78 Tom Science 89 John English 65 John Math 42 John Science 100 Susan English 68 Susan Math 89 Susan Science 37 Time taken: 37.511 seconds, Fetched: 9 row(s) --自定义函数类AddScore.java package com.b510.big.data.hive; import org.apache.hadoop.hive.ql.exec.UDF; import org.apache.hadoop.io.Text; public class AddScore extends UDF { // return 'v+1' public Text evaluate(int v) { return new Text(String.valueOf(Integer.valueOf(v) + 1)); } } --加入我们自己的jar文件 add jar /root/big_data_hive_addscore.jar; hive> add jar /root/big_data_hive_addscore.jar; Added /root/big_data_hive_addscore.jar to class path Added resource: /root/big_data_hive_addscore.jar --创建临时function create temporary function addScore as 'com.b510.big.data.hive.AddScore'; hive> create temporary function addScore as 'com.b510.big.data.hive.AddScore'; OK Time taken: 0.014 seconds --再次查询 --在之前的分数上面都加了1 select name, course, addScore(score) from t_score; hive> select name, course, addScore(score) from t_score; Total jobs = 1 Launching Job 1 out of 1 Number of reduce tasks is set to 0 since there's no reduce operator Starting Job = job_1547093703749_0017, Tracking URL = http://node1:8088/proxy/application_1547093703749_0017/ Kill Command = /home/hadoop-2.5/bin/hadoop job -kill job_1547093703749_0017 Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0 2019-01-10 01:59:24,026 Stage-1 map = 0%, reduce = 0% 2019-01-10 01:59:47,212 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 2.28 sec MapReduce Total cumulative CPU time: 2 seconds 280 msec Ended Job = job_1547093703749_0017 MapReduce Jobs Launched: Job 0: Map: 1 Cumulative CPU: 2.28 sec HDFS Read: 346 HDFS Write: 136 SUCCESS Total MapReduce CPU Time Spent: 2 seconds 280 msec OK Tom English 91 Tom Math 79 Tom Science 90 John English 66 John Math 43 John Science 101 Susan English 69 Susan Math 90 Susan Science 38 Time taken: 51.449 seconds, Fetched: 9 row(s)
10.结构体struct
--结构体struct create table t_user_struct ( id int, info struct<name:string,age:int> ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' collection items terminated by ':'; --test data cd vi hive_test_data_user_struct 1,Tom:31 2,John:23 3,Jack:45 4,Susan:23 5,Kuo:30 :wq load data local inpath '/root/hive_test_data_user_struct' into table t_user_struct; select * from t_user_struct; hive> select * from t_user_struct; OK 1 {"name":"Tom","age":31} 2 {"name":"John","age":23} 3 {"name":"Jack","age":45} 4 {"name":"Susan","age":23} 5 {"name":"Kuo","age":30} 1 {"name":"Tom","age":31} 2 {"name":"John","age":23} 3 {"name":"Jack","age":45} 4 {"name":"Susan","age":23} 5 {"name":"Kuo","age":30} Time taken: 0.065 seconds, Fetched: 10 row(s)
11.hive word count
--hive word count create table t_word_count( content string ); --test data cd vi hive_test_data_word_count this is test data hello hongten test data this is a test message good boy load data local inpath '/root/hive_test_data_word_count' into table t_word_count; --拆分 select split(content, ' ') from t_word_count; hive> select split(content, ' ') from t_word_count; Total jobs = 1 Launching Job 1 out of 1 Number of reduce tasks is set to 0 since there's no reduce operator Starting Job = job_1547180022884_0001, Tracking URL = http://node1:8088/proxy/application_1547180022884_0001/ Kill Command = /home/hadoop-2.5/bin/hadoop job -kill job_1547180022884_0001 Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0 2019-01-10 23:06:51,480 Stage-1 map = 0%, reduce = 0% 2019-01-10 23:07:02,207 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 4.14 sec MapReduce Total cumulative CPU time: 4 seconds 140 msec Ended Job = job_1547180022884_0001 MapReduce Jobs Launched: Job 0: Map: 1 Cumulative CPU: 4.14 sec HDFS Read: 303 HDFS Write: 74 SUCCESS Total MapReduce CPU Time Spent: 4 seconds 140 msec OK ["this","is","test","data"] ["hello","hongten","test","data"] ["this","is","a","test","message"] ["good","boy"] Time taken: 30.778 seconds, Fetched: 4 row(s) select explode(split(content, ' ')) from t_word_count; hive> select explode(split(content, ' ')) from t_word_count; Total jobs = 1 Launching Job 1 out of 1 Number of reduce tasks is set to 0 since there's no reduce operator Starting Job = job_1547180022884_0002, Tracking URL = http://node1:8088/proxy/application_1547180022884_0002/ Kill Command = /home/hadoop-2.5/bin/hadoop job -kill job_1547180022884_0002 Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0 2019-01-10 23:07:51,446 Stage-1 map = 0%, reduce = 0% 2019-01-10 23:08:03,041 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 3.93 sec MapReduce Total cumulative CPU time: 3 seconds 930 msec Ended Job = job_1547180022884_0002 MapReduce Jobs Launched: Job 0: Map: 1 Cumulative CPU: 3.93 sec HDFS Read: 303 HDFS Write: 74 SUCCESS Total MapReduce CPU Time Spent: 3 seconds 930 msec OK this is test data hello hongten test data this is a test message good boy Time taken: 19.418 seconds, Fetched: 15 row(s) --result table create table t_word_count_result( word string, count int ); --把结果输入到result table from (select explode(split(content, ' ')) word from t_word_count) t1 insert into table t_word_count_result select t1.word, count(t1.word) group by t1.word; --查询结果 hive> select * from t_word_count_result order by count desc; Total jobs = 1 Launching Job 1 out of 1 Number of reduce tasks determined at compile time: 1 In order to change the average load for a reducer (in bytes): set hive.exec.reducers.bytes.per.reducer=<number> In order to limit the maximum number of reducers: set hive.exec.reducers.max=<number> In order to set a constant number of reducers: set mapreduce.job.reduces=<number> Starting Job = job_1547180022884_0005, Tracking URL = http://node1:8088/proxy/application_1547180022884_0005/ Kill Command = /home/hadoop-2.5/bin/hadoop job -kill job_1547180022884_0005 Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1 2019-01-10 23:24:55,349 Stage-1 map = 0%, reduce = 0% 2019-01-10 23:25:01,706 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 3.44 sec 2019-01-10 23:25:09,051 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 5.23 sec MapReduce Total cumulative CPU time: 5 seconds 230 msec Ended Job = job_1547180022884_0005 MapReduce Jobs Launched: Job 0: Map: 1 Reduce: 1 Cumulative CPU: 5.23 sec HDFS Read: 290 HDFS Write: 71 SUCCESS Total MapReduce CPU Time Spent: 5 seconds 230 msec OK test 3 this 2 is 2 data 2 message 1 hongten 1 hello 1 good 1 boy 1 a 1 Time taken: 22.239 seconds, Fetched: 10 row(s)
12.hive 设置参数
--hive 设置参数 hive> set hive.cli.print.header; hive.cli.print.header=true hive> set hive.cli.print.header = false; hive> set hive.cli.print.header; hive.cli.print.header=false hive>set; ......
13.Hive动态分区
--Hive动态分区 --设置hive支持动态分区 set hive.exec.dynamic.partition=true set hive.exec.dynamic.partition.mode=nostrict; hive> set hive.exec.dynamic.partition; hive.exec.dynamic.partition=true hive> set hive.exec.dynamic.partition.mode; hive.exec.dynamic.partition.mode=strict set hive.exec.dynamic.partition.mode=nostrict; --创建表 cd /home/hive/bin ./hive create table t_user_partition ( id int, sex string, age int, name string, sports array<string>, address map<string, string> ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' COLLECTION ITEMS TERMINATED BY '-' MAP KEYS TERMINATED BY ':' LINES TERMINATED BY ' '; --hive test data vi hive_test_data_t_user_partition 1,Boy,20,Tom,篮球-足球-乒乓球,address1:Orchard Singapore-address2:宁夏 China 2,Girl,30,John,体操-足球-乒乓球,address1:Novena China-address2:新疆 China 3,Boy,20,Jack,篮球-棒球,address1:Newton Singapore-address2:广东 China 4,Girl,30,Hongten,篮球-单杠-滑冰,address1:Bishan Singapore-address2:上海 China 5,Girl,20,Sum,篮球-皮划艇-拳击,address1:Yishun Singapore-address2:辽宁 China 6,Girl,30,Susan,体操-足球-跑步,address1:YCK Singapore-address2:湖南 China 7,Boy,20,Mark,柔术-骑马-骑车,address1:Chinatown Singapore-address2:江西 China :wq --导入数据 cd /home/hive/bin ./hive LOAD DATA LOCAL INPATH '/root/hive_test_data_t_user_partition' INTO TABLE t_user_partition; --创建结果表 create table t_user_partition_result ( id int, name string, sports array<string>, address map<string, string> ) partitioned by (age int, sex string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' COLLECTION ITEMS TERMINATED BY '-' MAP KEYS TERMINATED BY ':' LINES TERMINATED BY ' '; --导入数据 from t_user_partition insert overwrite table t_user_partition_result partition(age, sex) select id, name, sports, address, age, sex distribute by age, sex; hive> from t_user_partition > insert overwrite table t_user_partition_result partition(age, sex) > select id, name, sports, address, age, sex distribute by age, sex; Total jobs = 1 Launching Job 1 out of 1 Number of reduce tasks not specified. Estimated from input data size: 1 In order to change the average load for a reducer (in bytes): set hive.exec.reducers.bytes.per.reducer=<number> In order to limit the maximum number of reducers: set hive.exec.reducers.max=<number> In order to set a constant number of reducers: set mapreduce.job.reduces=<number> Starting Job = job_1547180022884_0006, Tracking URL = http://node1:8088/proxy/application_1547180022884_0006/ Kill Command = /home/hadoop-2.5/bin/hadoop job -kill job_1547180022884_0006 Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1 2019-01-11 00:14:23,816 Stage-1 map = 0%, reduce = 0% 2019-01-11 00:14:30,348 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.41 sec 2019-01-11 00:14:38,759 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 3.44 sec MapReduce Total cumulative CPU time: 3 seconds 440 msec Ended Job = job_1547180022884_0006 Loading data to table default.t_user_partition_result partition (age=null, sex=null) Loading partition {age=20, sex=Boy} Loading partition {age=30, sex=Girl} Loading partition {age=20, sex=Girl} Partition default.t_user_partition_result{age=20, sex=Boy} stats: [numFiles=1, numRows=3, totalSize=227, rawDataSize=224] Partition default.t_user_partition_result{age=20, sex=Girl} stats: [numFiles=1, numRows=1, totalSize=78, rawDataSize=77] Partition default.t_user_partition_result{age=30, sex=Girl} stats: [numFiles=1, numRows=3, totalSize=228, rawDataSize=225] MapReduce Jobs Launched: Job 0: Map: 1 Reduce: 1 Cumulative CPU: 3.44 sec HDFS Read: 825 HDFS Write: 769 SUCCESS Total MapReduce CPU Time Spent: 3 seconds 440 msec OK Time taken: 25.321 seconds hive> select * from t_user_partition_result; OK 7 Mark ["柔术","骑马","骑车"] {"address1":"Chinatown Singapore","address2":"江西 China"} 20 Boy 3 Jack ["篮球","棒球"] {"address1":"Newton Singapore","address2":"广东 China"} 20 Boy 1 Tom ["篮球","足球","乒乓球"] {"address1":"Orchard Singapore","address2":"宁夏 China"} 20 Boy 5 Sum ["篮球","皮划艇","拳击"] {"address1":"Yishun Singapore","address2":"辽宁 China"} 20 Girl 6 Susan ["体操","足球","跑步"] {"address1":"YCK Singapore","address2":"湖南 China"} 30 Girl 4 Hongten ["篮球","单杠","滑冰"] {"address1":"Bishan Singapore","address2":"上海 China"} 30 Girl 2 John ["体操","足球","乒乓球"] {"address1":"Novena China","address2":"新疆 China"} 30 Girl Time taken: 0.046 seconds, Fetched: 7 row(s)
14.Hive 分桶
--Hive 分桶 --分桶的目的在于将同一个目录里面的文件拆分成多个文件 --分桶表时对列值取哈希值的方式,将不同数据放到不同文件中存储。 --对于Hive中给每一个表,分区都可以进一步分桶 --由列的哈希值除以桶的个数来决定每条数据话费在哪个桶中 --场景: --数据抽样 --开启分桶 set hive.enforce.bucketing=true; hive> set hive.enforce.bucketing; hive.enforce.bucketing=false hive> set hive.enforce.bucketing=true; hive> set hive.enforce.bucketing; hive.enforce.bucketing=true --抽样 select * from t_bucket tablesample(bucket 1 out of 4 on columns); --tablesample(bucket 1 out of 4 on columns) --1 : 表示从第1个bucket开始抽取数据 --4 : 表示必须为该表总的bucket数的倍数或因子 --e.g. bucket总数为32 --tablesample(bucket 2 out of 4) --表示从第2个bucket开始,每隔4个bucket抽取一次,总共抽取32/4=8次 --2,6,10,14,18,22,26,30 --tablesample(bucket 3 out of 8) --表示从第3个bucket开始,每隔8个bucket抽取一次,总共抽取32/8=4次 --3,11,19,27 --tablesample(bucket 3 out of 64) --表示从第3个bucket开始,每隔64个bucket抽取一次,总共抽取32/64=1/2次 --抽取第3个bucket里面的1/2数据即可 --创建表 create table t_user_info( id int, name string, age int ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ','; --test data cd vi hive_test_data_user_info 1,Tom,34 2,John,32 3,Susan,23 4,Make,21 5,Jack,19 :wq --加载数据 load data local inpath '/root/hive_test_data_user_info' into table t_user_info; --创建分桶表 create table t_user_info_bucket( id int, name string, age int ) clustered by (age) into 4 buckets ROW FORMAT DELIMITED FIELDS TERMINATED BY ','; --导入数据 from t_user_info insert into table t_user_info_bucket select id, name, age; --抽样数据 --从第1个bucket开始,每隔2个bucket抽一次,总共抽取4/2=2次 --1,3 select * from t_user_info_bucket tablesample(bucket 1 out of 2 on age); hive> select * from t_user_info_bucket tablesample(bucket 1 out of 2 on age); Total jobs = 1 Launching Job 1 out of 1 Number of reduce tasks is set to 0 since there's no reduce operator Starting Job = job_1547180022884_0010, Tracking URL = http://node1:8088/proxy/application_1547180022884_0010/ Kill Command = /home/hadoop-2.5/bin/hadoop job -kill job_1547180022884_0010 Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0 2019-01-11 01:47:42,857 Stage-1 map = 0%, reduce = 0% 2019-01-11 01:47:52,331 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 4.22 sec MapReduce Total cumulative CPU time: 4 seconds 220 msec Ended Job = job_1547180022884_0010 MapReduce Jobs Launched: Job 0: Map: 1 Cumulative CPU: 4.22 sec HDFS Read: 318 HDFS Write: 19 SUCCESS Total MapReduce CPU Time Spent: 4 seconds 220 msec OK 2 John 32 1 Tom 34 Time taken: 16.995 seconds, Fetched: 2 row(s)
15.Hive Lateral View -侧视图
--Hive Lateral View -侧视图 --Lateral View用于和UDTF函数(explode, split)结合来使用 --首先,通过UDTF函数拆分成多行,再将多行结果组合成一个支持特别名的虚拟表 --主要解决在select使用UDTF做查询过程中,查询只能包含单个UDTF,不能包含其他字段,已经多个UDTF的问题 --语法 --lateral view udtf(expression) tableAlias as columnAlias(',', columnAlias) select count(distinct(sportColumn)), count(distinct(addressColumn1)), count(distinct(addressColumn2)) from t_user lateral view explode(sports) t_user as sportColumn lateral view explode(address) t_user as addressColumn1, addressColumn2;
16.Hive 视图
--Hive 视图 --只做查询 --不支持物化视图(不可以持久化数据) --语法结构 CREATE VIEW [IF NOT EXISTS] [db_name.]view_name [(column_name [COMMENT column_comment], ...) ] [COMMENT view_comment] [TBLPROPERTIES (property_name = property_value, ...)] AS SELECT ...; create view if not exists v_t_user as select id, name from t_user; --查看视图 show tables; --查询视图 hive> select * from v_t_user; Total jobs = 1 Launching Job 1 out of 1 Number of reduce tasks is set to 0 since there's no reduce operator Starting Job = job_1547287439785_0003, Tracking URL = http://node1:8088/proxy/application_1547287439785_0003/ Kill Command = /home/hadoop-2.5/bin/hadoop job -kill job_1547287439785_0003 Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0 2019-01-12 02:29:59,826 Stage-1 map = 0%, reduce = 0% 2019-01-12 02:30:08,286 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.25 sec MapReduce Total cumulative CPU time: 1 seconds 250 msec Ended Job = job_1547287439785_0003 MapReduce Jobs Launched: Job 0: Map: 1 Cumulative CPU: 1.25 sec HDFS Read: 752 HDFS Write: 51 SUCCESS Total MapReduce CPU Time Spent: 1 seconds 250 msec OK v_t_user.id v_t_user.name 1 Tom 2 John 3 Jack 4 Hongten 5 Sum 6 Susan 7 Mark Time taken: 18.514 seconds, Fetched: 7 row(s) --删除视图 drop view v_t_user;
17.Hive 索引
--Hive 索引 --在经常查询的列上面添加索引 --1,sjygOM,17 create table t_index_user( id int, name string, age int ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ','; --测试数据,使用java来生成test data cd vi TestData.java import java.io.BufferedWriter; import java.io.FileWriter; import java.util.Random; public class TestData { public static void main(String[] args) throws Exception{ int num=20000000; StringBuilder sb = new StringBuilder(); Random random = new Random(); for(int i=0;i<num;i++){ sb.append(++i+ "," + getname() +","+ (random.nextInt(18)+random.nextInt(18))).append(" "); } String result = sb.toString(); BufferedWriter writer = new BufferedWriter(new FileWriter("/root/hive_test_data_index_t_index_user")); writer.write(result); writer.close(); } private static String getname() { String randomcode = ""; for (int i = 0; i < 6; i++) { int value = (int) (Math.random() * 58 + 65); while (value >= 91 && value <= 96) value = (int) (Math.random() * 58 + 65); randomcode = randomcode + (char) value; } //System.out.println(randomcode); String randomcode2 = ""; String model = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz"; char[] m = model.toCharArray(); for (int j = 0; j < 6; j++) { char c = m[(int) (Math.random() * 52)]; randomcode2 = randomcode2 + c; } //System.out.println(randomcode2); return randomcode2; } } :wq javac TestData.java java TestData --会生成测试数据 /root/hive_test_data_index_t_index_user --载入数据 load data local inpath '/root/hive_test_data_index_t_index_user' into table t_index_user; --创建索引 create index index_t_user on table t_index_user (name) as 'org.apache.hadoop.hive.ql.index.compact.CompactIndexHandler' WITH DEFERRED REBUILD; --查看某个table里面的index信息 show index on t_index_user; hive> show index on t_index_user; OK idx_name tab_name col_names idx_tab_name idx_type comment index_t_user t_index_user name default__t_index_user_index_t_user__ compact Time taken: 0.032 seconds, Fetched: 1 row(s) --重建索引 alter index index_t_user on t_index_user rebuild; hive> alter index index_t_user on t_index_user rebuild; Total jobs = 1 Launching Job 1 out of 1 Number of reduce tasks not specified. Estimated from input data size: 1 In order to change the average load for a reducer (in bytes): set hive.exec.reducers.bytes.per.reducer=<number> In order to limit the maximum number of reducers: set hive.exec.reducers.max=<number> In order to set a constant number of reducers: set mapreduce.job.reduces=<number> Starting Job = job_1547287439785_0008, Tracking URL = http://node1:8088/proxy/application_1547287439785_0008/ Kill Command = /home/hadoop-2.5/bin/hadoop job -kill job_1547287439785_0008 Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1 2019-01-12 05:08:31,292 Stage-1 map = 0%, reduce = 0% 2019-01-12 05:09:31,820 Stage-1 map = 0%, reduce = 0%, Cumulative CPU 78.14 sec 2019-01-12 05:10:31,847 Stage-1 map = 0%, reduce = 0%, Cumulative CPU 131.69 sec 2019-01-12 05:11:44,356 Stage-1 map = 0%, reduce = 0%, Cumulative CPU 162.59 sec 2019-01-12 05:12:45,741 Stage-1 map = 0%, reduce = 0%, Cumulative CPU 227.39 sec 2019-01-12 05:13:57,290 Stage-1 map = 0%, reduce = 0%, Cumulative CPU 227.39 sec 2019-01-12 05:14:50,634 Stage-1 map = 49%, reduce = 0%, Cumulative CPU 345.03 sec 2019-01-12 05:15:45,370 Stage-1 map = 67%, reduce = 0%, Cumulative CPU 400.16 sec 2019-01-12 05:15:55,696 Stage-1 map = 68%, reduce = 0%, Cumulative CPU 409.55 sec 2019-01-12 05:16:01,857 Stage-1 map = 69%, reduce = 0%, Cumulative CPU 415.6 sec 2019-01-12 05:16:05,128 Stage-1 map = 70%, reduce = 0%, Cumulative CPU 418.95 sec 2019-01-12 05:16:14,785 Stage-1 map = 71%, reduce = 0%, Cumulative CPU 428.17 sec 2019-01-12 05:16:36,402 Stage-1 map = 72%, reduce = 0%, Cumulative CPU 447.68 sec 2019-01-12 05:16:51,929 Stage-1 map = 73%, reduce = 0%, Cumulative CPU 463.48 sec 2019-01-12 05:17:01,223 Stage-1 map = 74%, reduce = 0%, Cumulative CPU 473.22 sec 2019-01-12 05:17:17,704 Stage-1 map = 75%, reduce = 0%, Cumulative CPU 487.52 sec 2019-01-12 05:17:27,030 Stage-1 map = 76%, reduce = 0%, Cumulative CPU 496.37 sec 2019-01-12 05:17:30,113 Stage-1 map = 78%, reduce = 0%, Cumulative CPU 498.47 sec 2019-01-12 05:17:33,207 Stage-1 map = 79%, reduce = 0%, Cumulative CPU 500.89 sec 2019-01-12 05:17:36,358 Stage-1 map = 80%, reduce = 0%, Cumulative CPU 502.61 sec 2019-01-12 05:17:39,543 Stage-1 map = 81%, reduce = 0%, Cumulative CPU 505.31 sec 2019-01-12 05:17:42,632 Stage-1 map = 83%, reduce = 0%, Cumulative CPU 507.38 sec 2019-01-12 05:17:45,743 Stage-1 map = 84%, reduce = 0%, Cumulative CPU 508.97 sec 2019-01-12 05:17:53,961 Stage-1 map = 85%, reduce = 0%, Cumulative CPU 509.68 sec 2019-01-12 05:17:57,097 Stage-1 map = 87%, reduce = 0%, Cumulative CPU 511.71 sec 2019-01-12 05:18:00,181 Stage-1 map = 88%, reduce = 0%, Cumulative CPU 513.3 sec 2019-01-12 05:18:04,109 Stage-1 map = 89%, reduce = 0%, Cumulative CPU 515.24 sec 2019-01-12 05:18:07,633 Stage-1 map = 90%, reduce = 0%, Cumulative CPU 518.52 sec 2019-01-12 05:18:09,692 Stage-1 map = 92%, reduce = 0%, Cumulative CPU 520.84 sec 2019-01-12 05:18:12,878 Stage-1 map = 94%, reduce = 0%, Cumulative CPU 522.26 sec 2019-01-12 05:18:20,114 Stage-1 map = 96%, reduce = 0%, Cumulative CPU 525.03 sec 2019-01-12 05:18:23,248 Stage-1 map = 97%, reduce = 0%, Cumulative CPU 526.31 sec 2019-01-12 05:18:26,368 Stage-1 map = 98%, reduce = 0%, Cumulative CPU 527.5 sec 2019-01-12 05:18:29,465 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 529.56 sec 2019-01-12 05:19:29,738 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 539.03 sec 2019-01-12 05:20:20,804 Stage-1 map = 100%, reduce = 67%, Cumulative CPU 569.11 sec 2019-01-12 05:20:30,410 Stage-1 map = 100%, reduce = 69%, Cumulative CPU 578.13 sec 2019-01-12 05:20:33,711 Stage-1 map = 100%, reduce = 70%, Cumulative CPU 580.4 sec 2019-01-12 05:20:36,856 Stage-1 map = 100%, reduce = 71%, Cumulative CPU 583.8 sec 2019-01-12 05:20:40,294 Stage-1 map = 100%, reduce = 72%, Cumulative CPU 586.75 sec 2019-01-12 05:20:43,507 Stage-1 map = 100%, reduce = 73%, Cumulative CPU 588.73 sec 2019-01-12 05:20:48,905 Stage-1 map = 100%, reduce = 74%, Cumulative CPU 591.11 sec 2019-01-12 05:20:52,113 Stage-1 map = 100%, reduce = 75%, Cumulative CPU 594.65 sec 2019-01-12 05:20:58,448 Stage-1 map = 100%, reduce = 76%, Cumulative CPU 597.07 sec 2019-01-12 05:21:01,572 Stage-1 map = 100%, reduce = 77%, Cumulative CPU 600.41 sec 2019-01-12 05:21:04,792 Stage-1 map = 100%, reduce = 78%, Cumulative CPU 602.9 sec 2019-01-12 05:21:07,912 Stage-1 map = 100%, reduce = 79%, Cumulative CPU 604.49 sec 2019-01-12 05:21:20,823 Stage-1 map = 100%, reduce = 80%, Cumulative CPU 607.93 sec 2019-01-12 05:21:24,206 Stage-1 map = 100%, reduce = 82%, Cumulative CPU 611.29 sec 2019-01-12 05:21:35,558 Stage-1 map = 100%, reduce = 84%, Cumulative CPU 617.26 sec 2019-01-12 05:21:39,479 Stage-1 map = 100%, reduce = 85%, Cumulative CPU 619.68 sec 2019-01-12 05:21:57,423 Stage-1 map = 100%, reduce = 86%, Cumulative CPU 625.01 sec 2019-01-12 05:22:05,947 Stage-1 map = 100%, reduce = 87%, Cumulative CPU 633.59 sec 2019-01-12 05:22:12,473 Stage-1 map = 100%, reduce = 88%, Cumulative CPU 638.58 sec 2019-01-12 05:22:18,038 Stage-1 map = 100%, reduce = 89%, Cumulative CPU 643.35 sec 2019-01-12 05:22:30,221 Stage-1 map = 100%, reduce = 91%, Cumulative CPU 649.43 sec 2019-01-12 05:22:33,363 Stage-1 map = 100%, reduce = 92%, Cumulative CPU 652.77 sec 2019-01-12 05:22:36,491 Stage-1 map = 100%, reduce = 93%, Cumulative CPU 655.37 sec 2019-01-12 05:22:39,677 Stage-1 map = 100%, reduce = 94%, Cumulative CPU 658.08 sec 2019-01-12 05:22:45,870 Stage-1 map = 100%, reduce = 95%, Cumulative CPU 660.48 sec 2019-01-12 05:22:55,481 Stage-1 map = 100%, reduce = 96%, Cumulative CPU 663.64 sec 2019-01-12 05:23:01,984 Stage-1 map = 100%, reduce = 97%, Cumulative CPU 666.04 sec 2019-01-12 05:23:08,244 Stage-1 map = 100%, reduce = 98%, Cumulative CPU 668.49 sec 2019-01-12 05:23:11,584 Stage-1 map = 100%, reduce = 99%, Cumulative CPU 671.87 sec 2019-01-12 05:23:21,038 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 674.85 sec MapReduce Total cumulative CPU time: 11 minutes 14 seconds 850 msec Ended Job = job_1547287439785_0008 Loading data to table default.default__t_index_user_index_t_user__ rmr: DEPRECATED: Please use 'rm -r' instead. Deleted hdfs://mycluster/user/hive/warehouse/default__t_index_user_index_t_user__ Table default.default__t_index_user_index_t_user__ stats: [numFiles=1, numRows=9997434, totalSize=1003498708, rawDataSize=993501274] MapReduce Jobs Launched: Job 0: Map: 1 Reduce: 1 Cumulative CPU: 674.85 sec HDFS Read: 182752679 HDFS Write: 1003498820 SUCCESS Total MapReduce CPU Time Spent: 11 minutes 14 seconds 850 msec OK Time taken: 912.183 seconds --查询 hive> select * from t_index_user where name = 'skXltC'; Total jobs = 1 Launching Job 1 out of 1 Number of reduce tasks is set to 0 since there's no reduce operator Starting Job = job_1547287439785_0010, Tracking URL = http://node1:8088/proxy/application_1547287439785_0010/ Kill Command = /home/hadoop-2.5/bin/hadoop job -kill job_1547287439785_0010 Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0 2019-01-12 05:25:08,587 Stage-1 map = 0%, reduce = 0% 2019-01-12 05:25:24,597 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 7.55 sec MapReduce Total cumulative CPU time: 7 seconds 550 msec Ended Job = job_1547287439785_0010 MapReduce Jobs Launched: Job 0: Map: 1 Cumulative CPU: 7.55 sec HDFS Read: 182752679 HDFS Write: 12 SUCCESS Total MapReduce CPU Time Spent: 7 seconds 550 msec OK t_index_user.id t_index_user.name t_index_user.age 1 skXltC 10 Time taken: 25.724 seconds, Fetched: 1 row(s) --删除索引 drop index index_t_user on t_index_user; hive> drop index index_t_user on t_index_user; OK Time taken: 0.317 seconds --删除完index后查询,花的时间要多一些 hive> select * from t_index_user where name = 'skXltC'; Total jobs = 1 Launching Job 1 out of 1 Number of reduce tasks is set to 0 since there's no reduce operator Starting Job = job_1547287439785_0011, Tracking URL = http://node1:8088/proxy/application_1547287439785_0011/ Kill Command = /home/hadoop-2.5/bin/hadoop job -kill job_1547287439785_0011 Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0 2019-01-12 06:52:46,631 Stage-1 map = 0%, reduce = 0% 2019-01-12 06:53:02,036 Stage-1 map = 73%, reduce = 0%, Cumulative CPU 9.17 sec 2019-01-12 06:53:03,549 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 9.85 sec MapReduce Total cumulative CPU time: 9 seconds 850 msec Ended Job = job_1547287439785_0011 MapReduce Jobs Launched: Job 0: Map: 1 Cumulative CPU: 9.85 sec HDFS Read: 182752679 HDFS Write: 12 SUCCESS Total MapReduce CPU Time Spent: 9 seconds 850 msec OK t_index_user.id t_index_user.name t_index_user.age 1 skXltC 10 Time taken: 40.618 seconds, Fetched: 1 row(s)
18.Hive 运行方式
--Hive 运行方式 --脚本运行方式 --查询结果显示在控制台 ./hive -e 'select * from t_user' [root@node1 bin]# ./hive -e 'select * from t_user' 19/01/13 04:19:50 WARN conf.HiveConf: DEPRECATED: hive.metastore.ds.retry.* no longer has any effect. Use hive.hmshandler.retry.* instead Logging initialized using configuration in jar:file:/root/apache-hive-0.13.1-bin/lib/hive-common-0.13.1.jar!/hive-log4j.properties SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/root/hadoop-2.5.1/share/hadoop/common/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/root/apache-hive-0.13.1-bin/lib/slf4j-log4j12-1.6.4.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory] OK t_user.id t_user.name t_user.sports t_user.address 1 Tom ["篮球","足球","乒乓球"] {"address1":"Orchard Singapore","address2":"宁夏 China"} 2 John ["体操","足球","乒乓球"] {"address1":"Novena China","address2":"新疆 China"} 3 Jack ["篮球","棒球"] {"address1":"Newton Singapore","address2":"广东 China"} 4 Hongten ["篮球","单杠","滑冰"] {"address1":"Bishan Singapore","address2":"上海 China"} 5 Sum ["篮球","皮划艇","拳击"] {"address1":"Yishun Singapore","address2":"辽宁 China"} 6 Susan ["体操","足球","跑步"] {"address1":"YCK Singapore","address2":"湖南 China"} 7 Mark ["柔术","骑马","骑车"] {"address1":"Chinatown Singapore","address2":"江西 China"} Time taken: 1.535 seconds, Fetched: 7 row(s) --把结果输入到指定的文件 ./hive -e 'select * from t_user' >> /root/t_user_data [root@node1 bin]# ./hive -e 'select * from t_user' >> /root/t_user_data 19/01/13 04:21:08 WARN conf.HiveConf: DEPRECATED: hive.metastore.ds.retry.* no longer has any effect. Use hive.hmshandler.retry.* instead Logging initialized using configuration in jar:file:/root/apache-hive-0.13.1-bin/lib/hive-common-0.13.1.jar!/hive-log4j.properties SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/root/hadoop-2.5.1/share/hadoop/common/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/root/apache-hive-0.13.1-bin/lib/slf4j-log4j12-1.6.4.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory] OK Time taken: 1.414 seconds, Fetched: 7 row(s) [root@node1 bin]# more /root/t_user_data t_user.id t_user.name t_user.sports t_user.address 1 Tom ["篮球","足球","乒乓球"] {"address1":"Orchard Singapore","address2":"宁夏 China"} 2 John ["体操","足球","乒乓球"] {"address1":"Novena China","address2":"新疆 China"} 3 Jack ["篮球","棒球"] {"address1":"Newton Singapore","address2":"广东 China"} 4 Hongten ["篮球","单杠","滑冰"] {"address1":"Bishan Singapore","address2":"上海 China"} 5 Sum ["篮球","皮划艇","拳击"] {"address1":"Yishun Singapore","address2":"辽宁 China"} 6 Susan ["体操","足球","跑步"] {"address1":"YCK Singapore","address2":"湖南 China"} 7 Mark ["柔术","骑马","骑车"] {"address1":"Chinatown Singapore","address2":"江西 China"} --执行指定的sql文件 cd vi hive_query_t_user.sql select * from t_user; :wq ./hive -f '/root/hive_query_t_user.sql' [root@node1 bin]# ./hive -f '/root/hive_query_t_user.sql' 19/01/13 04:26:51 WARN conf.HiveConf: DEPRECATED: hive.metastore.ds.retry.* no longer has any effect. Use hive.hmshandler.retry.* instead Logging initialized using configuration in jar:file:/root/apache-hive-0.13.1-bin/lib/hive-common-0.13.1.jar!/hive-log4j.properties SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/root/hadoop-2.5.1/share/hadoop/common/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/root/apache-hive-0.13.1-bin/lib/slf4j-log4j12-1.6.4.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory] OK t_user.id t_user.name t_user.sports t_user.address 1 Tom ["篮球","足球","乒乓球"] {"address1":"Orchard Singapore","address2":"宁夏 China"} 2 John ["体操","足球","乒乓球"] {"address1":"Novena China","address2":"新疆 China"} 3 Jack ["篮球","棒球"] {"address1":"Newton Singapore","address2":"广东 China"} 4 Hongten ["篮球","单杠","滑冰"] {"address1":"Bishan Singapore","address2":"上海 China"} 5 Sum ["篮球","皮划艇","拳击"] {"address1":"Yishun Singapore","address2":"辽宁 China"} 6 Susan ["体操","足球","跑步"] {"address1":"YCK Singapore","address2":"湖南 China"} 7 Mark ["柔术","骑马","骑车"] {"address1":"Chinatown Singapore","address2":"江西 China"} Time taken: 1.215 seconds, Fetched: 7 row(s) --执行完后,进行hive命令行 ./hive -i /root/hive_query_t_user.sql [root@node1 bin]# ./hive -i /root/hive_query_t_user.sql 19/01/13 04:33:50 WARN conf.HiveConf: DEPRECATED: hive.metastore.ds.retry.* no longer has any effect. Use hive.hmshandler.retry.* instead Logging initialized using configuration in jar:file:/root/apache-hive-0.13.1-bin/lib/hive-common-0.13.1.jar!/hive-log4j.properties SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/root/hadoop-2.5.1/share/hadoop/common/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/root/apache-hive-0.13.1-bin/lib/slf4j-log4j12-1.6.4.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory] t_user.id t_user.name t_user.sports t_user.address 1 Tom ["篮球","足球","乒乓球"] {"address1":"Orchard Singapore","address2":"宁夏 China"} 2 John ["体操","足球","乒乓球"] {"address1":"Novena China","address2":"新疆 China"} 3 Jack ["篮球","棒球"] {"address1":"Newton Singapore","address2":"广东 China"} 4 Hongten ["篮球","单杠","滑冰"] {"address1":"Bishan Singapore","address2":"上海 China"} 5 Sum ["篮球","皮划艇","拳击"] {"address1":"Yishun Singapore","address2":"辽宁 China"} 6 Susan ["体操","足球","跑步"] {"address1":"YCK Singapore","address2":"湖南 China"} 7 Mark ["柔术","骑马","骑车"] {"address1":"Chinatown Singapore","address2":"江西 China"} hive> --在hive命令行,执行sql文件 hive> source /root/hive_query_t_user.sql; OK t_user.id t_user.name t_user.sports t_user.address 1 Tom ["篮球","足球","乒乓球"] {"address1":"Orchard Singapore","address2":"宁夏 China"} 2 John ["体操","足球","乒乓球"] {"address1":"Novena China","address2":"新疆 China"} 3 Jack ["篮球","棒球"] {"address1":"Newton Singapore","address2":"广东 China"} 4 Hongten ["篮球","单杠","滑冰"] {"address1":"Bishan Singapore","address2":"上海 China"} 5 Sum ["篮球","皮划艇","拳击"] {"address1":"Yishun Singapore","address2":"辽宁 China"} 6 Susan ["体操","足球","跑步"] {"address1":"YCK Singapore","address2":"湖南 China"} 7 Mark ["柔术","骑马","骑车"] {"address1":"Chinatown Singapore","address2":"江西 China"} Time taken: 0.074 seconds, Fetched: 7 row(s)
19.Hive GUI
--Hive GUI --在浏览器 --解压apache-hive-1.2.1-src.tar.gz --运行命令jar -cvf hive-hwi.war * D:apache-hive-1.2.1-srchwiweb>jar -cvf hive-hwi.war * added manifest adding: authorize.jsp(in = 2729) (out= 1201)(deflated 55%) adding: css/(in = 0) (out= 0)(stored 0%) adding: css/bootstrap.min.css(in = 90193) (out= 14754)(deflated 83%) adding: diagnostics.jsp(in = 2365) (out= 1062)(deflated 55%) adding: error_page.jsp(in = 1867) (out= 931)(deflated 50%) adding: img/(in = 0) (out= 0)(stored 0%) adding: img/glyphicons-halflings-white.png(in = 4352) (out= 4190)(deflated 3%) adding: img/glyphicons-halflings.png(in = 4352) (out= 4192)(deflated 3%) adding: index.jsp(in = 1876) (out= 981)(deflated 47%) adding: left_navigation.jsp(in = 1553) (out= 709)(deflated 54%) adding: navbar.jsp(in = 1345) (out= 681)(deflated 49%) adding: session_create.jsp(in = 2690) (out= 1248)(deflated 53%) adding: session_diagnostics.jsp(in = 2489) (out= 1155)(deflated 53%) adding: session_history.jsp(in = 3150) (out= 1334)(deflated 57%) adding: session_kill.jsp(in = 2236) (out= 1108)(deflated 50%) adding: session_list.jsp(in = 2298) (out= 1059)(deflated 53%) adding: session_manage.jsp(in = 6738) (out= 2198)(deflated 67%) adding: session_remove.jsp(in = 2359) (out= 1151)(deflated 51%) adding: session_result.jsp(in = 2488) (out= 1149)(deflated 53%) adding: show_database.jsp(in = 2346) (out= 1133)(deflated 51%) adding: show_databases.jsp(in = 2096) (out= 1039)(deflated 50%) adding: show_table.jsp(in = 4996) (out= 1607)(deflated 67%) adding: view_file.jsp(in = 2653) (out= 1257)(deflated 52%) adding: WEB-INF/(in = 0) (out= 0)(stored 0%) adding: WEB-INF/web.xml(in = 1438) (out= 741)(deflated 48%) --把hive-hwi.war上传到/home/hive/lib D:apache-hive-1.2.1-srchwiwebhive-hwi.war cp /root/hive-hwi.war /home/hive/lib --把tools.jar上传到/home/hive/lib C:Program FilesJavajdk1.7.0_80lib ools.jar cp /root/tools.jar /home/hive/lib --修改/home/hive/conf/hive-site.xml文件 cd /home/hive/conf/ vi hive-site.xml <!--Hive Web GUI Interface--> <property> <name>hive.hwi.listen.host</name> <value>0.0.0.0</value> </property> <property> <name>hive.hwi.listen.port</name> <value>9999</value> </property> <property> <name>hive.hwi.war.file</name> <value>lib/hive-hwi.war</value> </property> :wq --启动服务 cd /home/hive/lib ./hive --service hwi [root@node1 bin]# ./hive --service hwi ls: cannot access /home/hive/lib/hive-hwi-*.war: No such file or directory 19/01/13 05:08:26 INFO hwi.HWIServer: HWI is starting up 19/01/13 05:08:26 WARN conf.HiveConf: DEPRECATED: hive.metastore.ds.retry.* no longer has any effect. Use hive.hmshandler.retry.* instead SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/root/hadoop-2.5.1/share/hadoop/common/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/root/apache-hive-0.13.1-bin/lib/slf4j-log4j12-1.6.4.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory] 19/01/13 05:08:26 INFO mortbay.log: Logging to org.slf4j.impl.Log4jLoggerAdapter(org.mortbay.log) via org.mortbay.log.Slf4jLog 19/01/13 05:08:27 INFO mortbay.log: jetty-6.1.26 19/01/13 05:08:27 INFO mortbay.log: Extract /home/hive/lib/hive-hwi.war to /tmp/Jetty_0_0_0_0_9999_hive.hwi.war__hwi__3rbmda/webapp 19/01/13 05:08:27 INFO mortbay.log: Started SocketConnector@0.0.0.0:9999 --打开浏览器 http://node1:9999/hwi
20.Hive 权限管理
--Hive 权限管理 --https://cwiki.apache.org/confluence/display/Hive/SQL+Standard+Based+Hive+Authorization --配置hive-site.xml文件 cd /home/hive/conf vi hive-site.xml <property> <name>hive.security.authorization.enabled</name> <value>true</value> </property> <property> <name>hive.server2.enable.doAs</name> <value>false</value> </property> <property> <name>hive.users.in.admin.role</name> <value>root</value> </property> <property> <name>hive.security.metastore.authorization.manager</name> <value>org.apache.hadoop.hive.ql.security.authorization.MetaStoreAuthzAPIAuthorizerEmbedOnly</value> </property> <property> <name>hive.security.authorization.manager</name> <value>org.apache.hadoop.hive.ql.security.authorization.plugin.sqlstd.SQLStdConfOnlyAuthorizerFactory</value> </property> -- cd /home/hive/bin ./hiveserver2 & ./beeline -u jdbc:hive2://node1:10001/default -n root <property> <name>hive.server2.thrift.port</name> <value>10001</value> <description>Port number of HiveServer2 Thrift interface. Can be overridden by setting $HIVE_SERVER2_THRIFT_PORT</description> </property> <property> <name>hive.server2.thrift.bind.host</name> <value>node1</value> <description>Bind host on which to run the HiveServer2 Thrift interface. Can be overridden by setting $HIVE_SERVER2_THRIFT_BIND_HOST</description> </property> --Create Role CREATE ROLE role_name; --Drop Role DROP ROLE role_name; --Show Roles SHOW CURRENT ROLES; SET ROLE (role_name|ALL|NONE); --Grant Role GRANT role_name [, role_name] ... TO principal_specification [, principal_specification] ... [ WITH ADMIN OPTION ]; principal_specification : USER user | ROLE role
21.Hive 优化
--Hive 优化 --把Hive SQL当做Mapreduce程序去优化 --显示执行计划 explai [extended] query; hive> explain select count(*) from t_user; OK Explain STAGE DEPENDENCIES: Stage-1 is a root stage Stage-0 is a root stage STAGE PLANS: Stage: Stage-1 Map Reduce Map Operator Tree: TableScan alias: t_user Statistics: Num rows: 0 Data size: 533 Basic stats: PARTIAL Column stats: COMPLETE Select Operator Statistics: Num rows: 0 Data size: 533 Basic stats: PARTIAL Column stats: COMPLETE Group By Operator aggregations: count() mode: hash outputColumnNames: _col0 Statistics: Num rows: 1 Data size: 8 Basic stats: COMPLETE Column stats: COMPLETE Reduce Output Operator sort order: Statistics: Num rows: 1 Data size: 8 Basic stats: COMPLETE Column stats: COMPLETE value expressions: _col0 (type: bigint) Reduce Operator Tree: Group By Operator aggregations: count(VALUE._col0) mode: mergepartial outputColumnNames: _col0 Statistics: Num rows: 1 Data size: 8 Basic stats: COMPLETE Column stats: COMPLETE Select Operator expressions: _col0 (type: bigint) outputColumnNames: _col0 Statistics: Num rows: 1 Data size: 8 Basic stats: COMPLETE Column stats: COMPLETE File Output Operator compressed: false Statistics: Num rows: 1 Data size: 8 Basic stats: COMPLETE Column stats: COMPLETE table: input format: org.apache.hadoop.mapred.TextInputFormat output format: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe Stage: Stage-0 Fetch Operator limit: -1 Time taken: 0.255 seconds, Fetched: 44 row(s) hive> explain extended select count(*) from t_user; OK Explain ABSTRACT SYNTAX TREE: TOK_QUERY TOK_FROM TOK_TABREF TOK_TABNAME t_user TOK_INSERT TOK_DESTINATION TOK_DIR TOK_TMP_FILE TOK_SELECT TOK_SELEXPR TOK_FUNCTIONSTAR count STAGE DEPENDENCIES: Stage-1 is a root stage Stage-0 is a root stage STAGE PLANS: Stage: Stage-1 Map Reduce Map Operator Tree: TableScan alias: t_user Statistics: Num rows: 0 Data size: 533 Basic stats: PARTIAL Column stats: COMPLETE GatherStats: false Select Operator Statistics: Num rows: 0 Data size: 533 Basic stats: PARTIAL Column stats: COMPLETE Group By Operator aggregations: count() mode: hash outputColumnNames: _col0 Statistics: Num rows: 1 Data size: 8 Basic stats: COMPLETE Column stats: COMPLETE Reduce Output Operator sort order: Statistics: Num rows: 1 Data size: 8 Basic stats: COMPLETE Column stats: COMPLETE tag: -1 value expressions: _col0 (type: bigint) Path -> Alias: hdfs://mycluster/user/hive/warehouse/t_user [t_user] Path -> Partition: hdfs://mycluster/user/hive/warehouse/t_user Partition base file name: t_user input format: org.apache.hadoop.mapred.TextInputFormat output format: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat properties: COLUMN_STATS_ACCURATE true bucket_count -1 colelction.delim - columns id,name,sports,address columns.comments columns.types int:string:array<string>:map<string,string> field.delim , file.inputformat org.apache.hadoop.mapred.TextInputFormat file.outputformat org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat line.delim location hdfs://mycluster/user/hive/warehouse/t_user mapkey.delim : name default.t_user numFiles 1 numRows 0 rawDataSize 0 serialization.ddl struct t_user { i32 id, string name, list<string> sports, map<string,string> address} serialization.format , serialization.lib org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe totalSize 533 transient_lastDdlTime 1547021182 serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe input format: org.apache.hadoop.mapred.TextInputFormat output format: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat properties: COLUMN_STATS_ACCURATE true bucket_count -1 colelction.delim - columns id,name,sports,address columns.comments columns.types int:string:array<string>:map<string,string> field.delim , file.inputformat org.apache.hadoop.mapred.TextInputFormat file.outputformat org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat line.delim location hdfs://mycluster/user/hive/warehouse/t_user mapkey.delim : name default.t_user numFiles 1 numRows 0 rawDataSize 0 serialization.ddl struct t_user { i32 id, string name, list<string> sports, map<string,string> address} serialization.format , serialization.lib org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe totalSize 533 transient_lastDdlTime 1547021182 serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe name: default.t_user name: default.t_user Truncated Path -> Alias: /t_user [t_user] Needs Tagging: false Reduce Operator Tree: Group By Operator aggregations: count(VALUE._col0) mode: mergepartial outputColumnNames: _col0 Statistics: Num rows: 1 Data size: 8 Basic stats: COMPLETE Column stats: COMPLETE Select Operator expressions: _col0 (type: bigint) outputColumnNames: _col0 Statistics: Num rows: 1 Data size: 8 Basic stats: COMPLETE Column stats: COMPLETE File Output Operator compressed: false GlobalTableId: 0 directory: hdfs://mycluster/tmp/hive-root/hive_2019-01-13_07-11-14_731_8514781577525697015-1/-ext-10001 NumFilesPerFileSink: 1 Statistics: Num rows: 1 Data size: 8 Basic stats: COMPLETE Column stats: COMPLETE Stats Publishing Key Prefix: hdfs://mycluster/tmp/hive-root/hive_2019-01-13_07-11-14_731_8514781577525697015-1/-ext-10001/ table: input format: org.apache.hadoop.mapred.TextInputFormat output format: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat properties: columns _col0 columns.types bigint escape.delim hive.serialization.extend.nesting.levels true serialization.format 1 serialization.lib org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe TotalFiles: 1 GatherStats: false MultiFileSpray: false Stage: Stage-0 Fetch Operator limit: -1 Time taken: 0.088 seconds, Fetched: 141 row(s) --hive 本地模式 --1.开启本地模式 --set hive.exec.mode.local.auto=true --注意: --hive.exec.mode.local.auto.inputbytes.amx=128M --表示加载文件的最大值,若大于该配置文件仍然会以集群方式来运行。 --2.hive 并行计算 --set hive.exec.parallel=true --sql要支持并行计算才有用 --3.严格模式 --set hive.mapred.mode=strict --查询限制 --a.对于分区表,必须添加where对于分区字段的条件过滤 --b.order by语句必须包含limit输出限制 --c.限制执行笛卡尔积的查询 select t1.ct1, t2.ct2 from (select count(id) ct1 from t_user) t1, (select count(name) ct2 from t_user) t2; --4.hive 排序 --Order By 对于查询结果做全排序,只允许一个reduce处理 --如果数据量大时,应该和limit一起使用 --sort by 对于单个reduce的数据进行排序 --distribute by 分区排序,经常和sort by结合使用 --cluster by 相当于sort by + distribute by --cluster by不能通过asc,desc的方式指定排序规则 --可以通过distribute by c1 sort by c1 asc|desc的方式来指定排序规则 --5.hive join --join计算时,将小表放在join的左边 --开启自动的mapjoin --set hive.auto.convert.join=true; --SQL方式,在sql语句中添加mapjoin标记(mapjoin hint) seelct /*+ mapjoin(smallTable)*/ smallTable.key, bigTable.value from smailTable join bigTable on smailTable.key=bigTable.key; --相关配置 --hive.mapjoin.smalltable.filesize; --大表小表判断的阈值,如果表的大小小于该值,则会被加载到内存中运行 --hive.ignore.mapjoin.hint --默认值为true,是否忽略mapjoin hint即mapjoin标记 --hive.auto.convert.join.noconditionaltask --默认值为true,将普通的join转化为普通的mapjoin时,是否将多个mapjoin转化为一个mapjoin --hive.auto.convert.join.noconditionaltask.size --将多个mapjoin转化为一个mapjoin时,其表的最大值 --6.map端聚合 --set hive.map.aggr=true --相关配置 --hive.groupby.mappaggr.checkinterval --默认值:100000,map端group by执行聚合时处理的多少行数据 --hive.map.aggr.hash.min.reduction --进行聚合的最小比例(预先对100000条数据进行聚合,如果聚合之后的数据量/100000的值大于该配置0.5,则不会聚合) --hive.map.aggr.hash.percentmamory --map端聚合使用的内存的最大值 --hive.map.aggr.hash.force.flush.memory.threshold --map端做聚合操作时hash表的最大可用容量,大于该值就会发生flush --hive.groupby.skewindata --是否对group by产生的数据倾斜做优化,默认值为false --7.控制hive中map和reduce的数量 --map数量设置 --mapred.max.split.size --一个split的最大值,即每个map处理文件的最大值 --mapred.min.split.size.per.node --一个节点上的split的最小值 --mapred.min.split.size.per.rack --一个机架上split的最小值 --reduce数量设置 --mapred.reduce.tasks --强制指定reduce任务的数量 --hive.exec.reducers.bytes.per.reducer --每个reduce任务㔘的数据量 --hive.exec.reducers.max --每个任务最大的reduce数 --8.hive -JVM重用 --场景 --a.小文件个数过多 --b.task个数过多 --set mapred.job.reuse.jvm.num.tasks=n --n为taks插槽个数 --缺点 --设置开启后,task插槽会一直占用资源,不论是否有task运行,知道所有的task即整个job全部完成执行,才会释放所有task插槽资源
========================================================
More reading,and english is important.
I'm Hongten
大哥哥大姐姐,觉得有用打赏点哦!你的支持是我最大的动力。谢谢。
Hongten博客排名在100名以内。粉丝过千。
Hongten出品,必是精品。
E | hongtenzone@foxmail.com B | http://www.cnblogs.com/hongten
========================================================