参考:
hive参数:
https://www.cnblogs.com/yinzhengjie/articles/11065409.html
官网:
hive.apache.org
选Getting Started Guide会转到wiki, 中文翻译--里面搜索想要的,比如hiveserver2
Getting started guide:
https://cwiki.apache.org/confluence/display/Hive/GettingStarted
Hive是构建在hadoop之上的一个数据仓库平台,将结构化的数据映射为结构化的表,使用较为易用的SQL来处理数据,使用SQL来代替编程门槛较高的Mapreduce,但本质上依然是将SQL转换为响应逻辑的Mapreduce来对大规模数据进行分布式计算处理
几乎在hive的同一时期,还有一种比较简单的Mapreduce编程接口,即Pig;其通过简单的语义表达式来描述对数据的处理,为分析师或者ETL开发人员进行大规模数据处理大大降低了门槛,其执行过程依然是将语义描述转换为Mapreduce程序,在hadoop上进行分布式计算;和hive相比,pig更加灵活,也可以脱离hadoop进行简单的数据处理。由于SQL的普及率更高以及易用性,所以hive的发展更加迅速
#三个入口: cli, JDBC/ODBC(java是用JDBC), web UI.
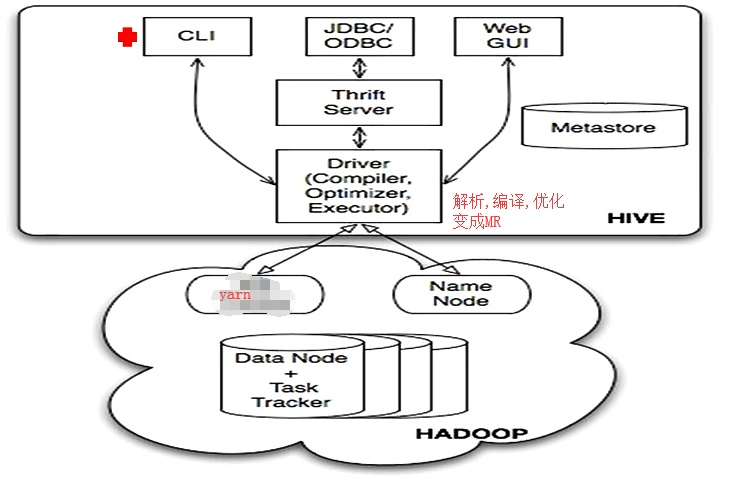
hive可以部署在不同的hadoop节点或有客户端的机器上,共用metadata.
hive的作用就是, 提个sql进来,解析成MR,提到yarn运行.
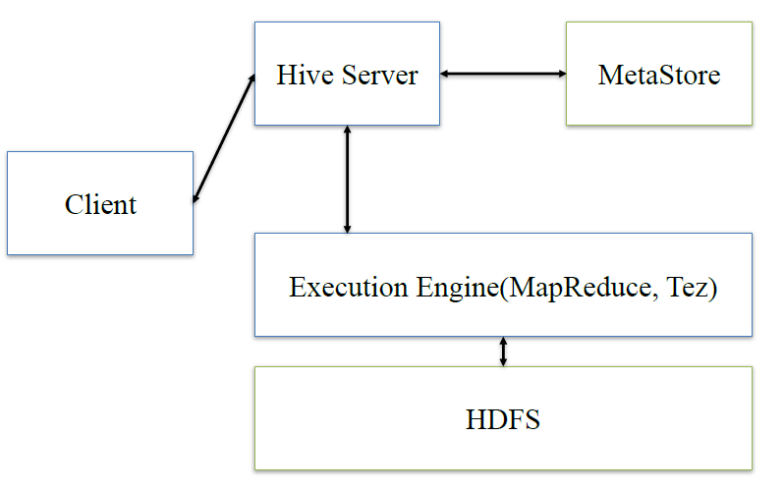
hive:client将查询请求发送到hive server,它会和metastor交互,获取表的元信息,如表的位置结构等,之后hive server会进行语法解析,解析成语法树,变成查询计划,进行优化后,将查询计划交给执行引擎,默认是MR,然后翻译成MR
Hive元数据的三种方案:
1/ 内嵌Derby方式
使用内嵌的Derby库存储元数据,不能多用户并行操作,适合单机测试、学习.自带
2/ Local方式
使用mysql、pg等RDBMS作为hive元数据存储介质,运行多用户并行操作,是较为常用的方式

hive.metastore.local true
javax.jdo.option.ConnectionURL
javax.jdo.option.ConnectionDriverName
javax.jdo.option.ConnectionUserName
javax.jdo.option.ConnectionPassword
3/ Remote方式
在元数据库上启动一个独立的metastore server,客户端通过metastore server与元数据库交
互,对客户端隐藏数据库信息
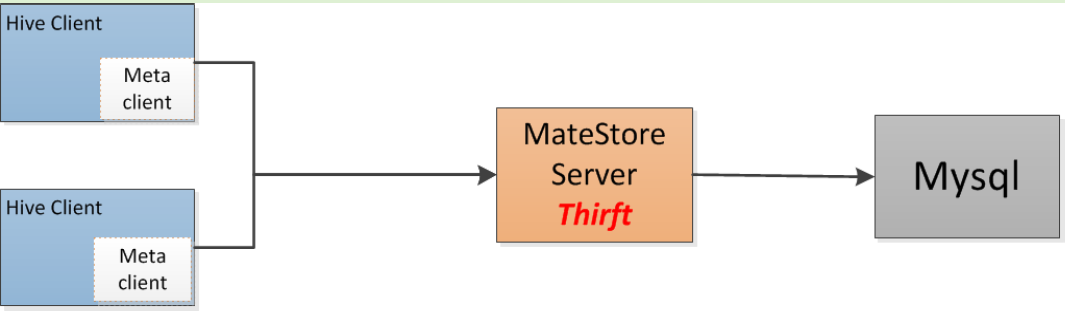
hive.metastore.local true
hive.metastore.uris thrift://ip :9083
show databases慢的话,可从访问元数据库慢的方向排查或Thirft这个服务的问题
Metastore Server与HiveServer2区别:
两个独立的服务
MetaStore Server:
hive元数据的访问入口,使用thirft协议(支持多种语言),提供对hive元数据的跨语言访问
HiveServer2:
hive库中数据的访问入口,同样适用thirft协议,提供对hive中数据的跨语言访问,比如
常见的python、java等对hive数据的远程访问,beeline客户端也是通过Hiveserver2方式访问数据
hive的数据结构:
见G:文档大数据
因为hive有很多宽表,很多时候需要读取的是其中的字段,所以列式存储对这种场景更快.
列式存储,即存储以行为单位,常见的文件格式有rcfile(不推荐了)、orc(orc是rcfile的优化,presto低版本只支持ORC)、parquet(上层用了impala的话最好用这种)
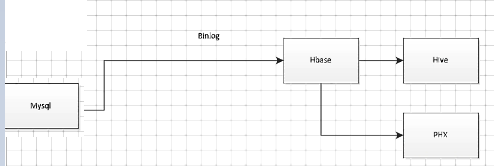
#先存在hbase的采集方案,以支持事务来实时查询,在数据量不大(千万条时),后端可用hive,和phx来实时查询(当然hive如果选MR作引擎,做不了准实时,有MR的时间)
Hive事务:
hive适合于大规模,高吞吐的数据处理
提供基本的查询、分析能力,所以hive
并不是为事务、交易处理场景而存在的,
最初hive并不支持事务。由于部分场景的
需要,对hive进行了扩展,提供了基本
的事务支持,但限制较多:
1/ 复杂的配置
2/ 文件格式必须是ORC
3/ 表必须分桶
4/ 对事务的支持不够完善,性能、稳定性欠缺。脏数据,多用户的并发支持不好等。
生产不建议用,如果对使用hive事务有非常强的需求,建议考虑上面的hbase+hive的方案,利用hbase的实时写入以及事务支持的特性,hive的hql易用并且高吞吐的能力,组合来满足。
hive命令:
把hive结果保存在本地:
1/ hive -e 'select id from db.tab_test where...'
2/ echo 'select id from db.tab_test where...' >insql.hql
hive -f ./insql.hql
优化
hive参数设置:
参数设置的方式:
1/是hive-site里全局变量
2/ 针对一次会话的set设置
设置是否在map前合并小文件以减少map数
hive>set hive.hadoop.supports.splittable.combineinputformat=true;
在map-only的任务结束时合并小文件
hive>set hive.merge.mapfiles=true;
在map-reduce的任务结束时合并小文件
hive>set hive.merge.mapredfiles=true;
使用tez引擎
hive>set hive.execution.engine=tez #还可选spark
注:tez还是走的MR,只不过把中间数据存在内存里。
github.com/rcongiu/Hive-JSON-Serde
优化:
合理控制并行:并不是所有任务都能并行,如group by, 没有依赖关系的join可以
开启任务并行执行
set hive.exec.parallel=true;
允许并行任务的最大线程数:
set hive.exec.parallel.thread.number=8;
合理控制map数:
小文件的来源有两个:
一种是数据本身就小
一种是map阶段一些参数的设置问题
map数太少了,意味着并发性不好.太多了也不好,浪费了很多内存.(map运行在container里, 需要去申请更多的container,这种调度本身就很浪费资源)
256000000=256M,比如1个G的文件, 就拆分成4个map
最后一个合并文件是发生在map端.

#Reduce合理控制:
指定reduce的数量要合理,数据量大的时候要设置大些,不要让每个reduce处理的数据量过大,消耗的时间就长.

map-only是指一些任务只有map没有reduce,如一些sqoop任务

sort,order by:
sort是在reduce里做的排序
order by是全局的,只能有一个reduce.
所以大数据量的时候要尽量避免order by.
在只能使用order by的场景一般要和limit搭配用.
场景六:
map多承担问题,减少reduce的计算成本和数据传输成本
-map join
-map aggr
场景七:
数据倾斜问题:
1/ 空值问题
一般只会发生在空值的量太大的情况下.
解决:
做join的加个条件不空, 或union is not null
2/ 数据类型不一致
产生原因: hive默认是用hash, 不像自己写MR
在join的时候自己强转移一下,比如cost -as bigint
3/ 业务数据本身导致
在某个区域它的业务量不一样:
比如在北京业务多.
解决:
增加一个job,如group by xx
场景八:
数据裁减:
-记录裁剪
分区、分桶
无效记录map阶段剔除
-列裁剪
剔除无效、非计算范围内的列数据(只拿自己需要的列,如不用select * 用select name,id)
列式存储
#多表插入,一次计算多次使用

hive-site.xml
hive.async.log.enabled false #控制beeline日志,跑时是否输出执行日志,默认是true提升性能. 设置为false表示输出日志,包括map, application id等.便于排错.
Hive自定义UDF的JAR包加入运行环境的方法:
https://blog.csdn.net/fjssharpsword/article/details/70271671
一般放到:hive-site.xml文件配置hive.aux.jars.path参数的目录下,配置多个目录中间用逗号隔开.
hive:
hive.exec.parallel.thread.number 50
hive.exec.reducers.bytes.per.reducer
该参数在0.14.0之前默认为1,000,000,000(约1GB),在0.14.0及以后默 认为256,000,000(约256MB)。该参数控制每个reducer平均处理的字节 数,默认值不一定适合所有的情况,应该根据企业内Hive作业通常处理的 数据量、集群节点数等参数来酌情配置
hive.exec.dynamic.partition
hive.exec.reducers.max 250
hive.server2.thrift.max.worker.threads 5000