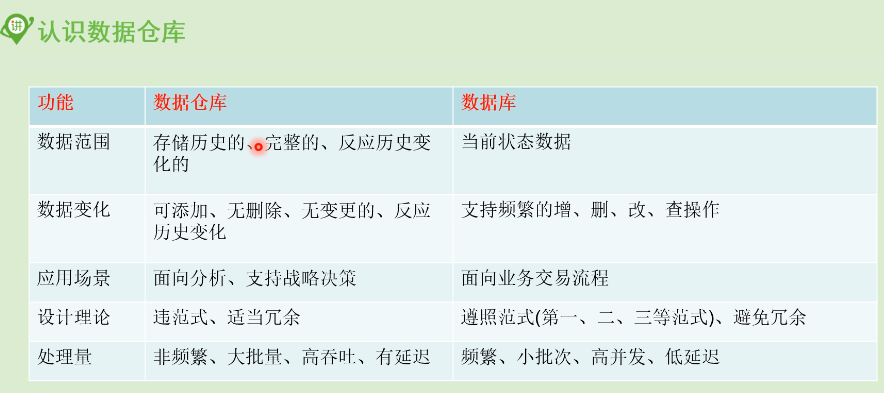
面向业务的数据库常叫 OLTP(on-line transaction processing)面向 分析的数据仓库常叫OLAP(On-Line Analytical Processing),区别见 :
https://www.cnblogs.com/hongfeng2019/p/12004551.html
一个交易流程包括多个事务,比如定单 ,支付 等,比如购物篮的分析 ,比如做了一次活动后的分析,比如拉新转换率有多高, 这些都是面向场景的分析。还有支持决策的分析,如BI

转换 : sqoop能做一些简单的转换 ,更多的是在ETL里面用 hive sql做的,或者用sacal,spark写。
Bill inmon <building the data warehouse>, 认为数仓是bi的一部分 ,自上而下,但往往实施时候在上层梳理业务工作量很大,而且不免遗漏。
RALPH KIMBALL 《the data warehouse toolkit》认为数据仓库是企业所有数据集市 的集合,分解,一个集市一个集市的做,比如先做财务的,再做出行的,一个一个的做成功率加大。数据集市多了后会出现 数据不一致的情况
两种思路和观点在实际的操作中都很难成功的完成项目交付,直至最终Bill Inmon提出了新的BI架
构CIF(Corporation information factory), 就是层次化划分 。把数据集市包含了进来。CIF的核心是将数仓架构划分为
不同的层次以满足不同场景的需求,比如常见的ODS、DW(又分为明细数据,和上层的汇总数据,根据不同公司的业务场景又分为DWDDWM层等)、DM等,每层根据实际场景采用不同
的建设方案,改思路也是目前数据仓库建设的架构指南,但自上而下还是自下而上的进行数据仓
库建设,并未统一。
ODS到数仓DW之间做的一件事就是数据的清洗。 APP指应用层,比如个性化推荐、用户画像等
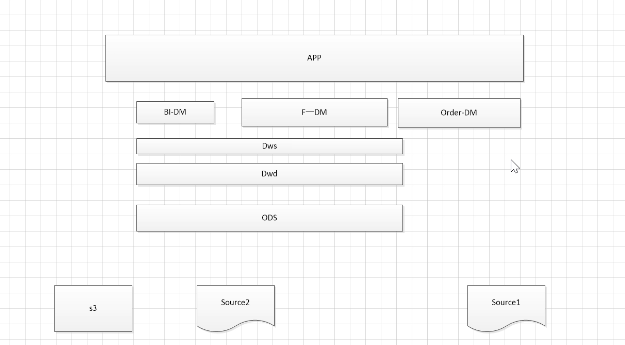
其实采集到ODS也是ETL的一部分,可以说整个架构都在做ETL

阿里: one data one service
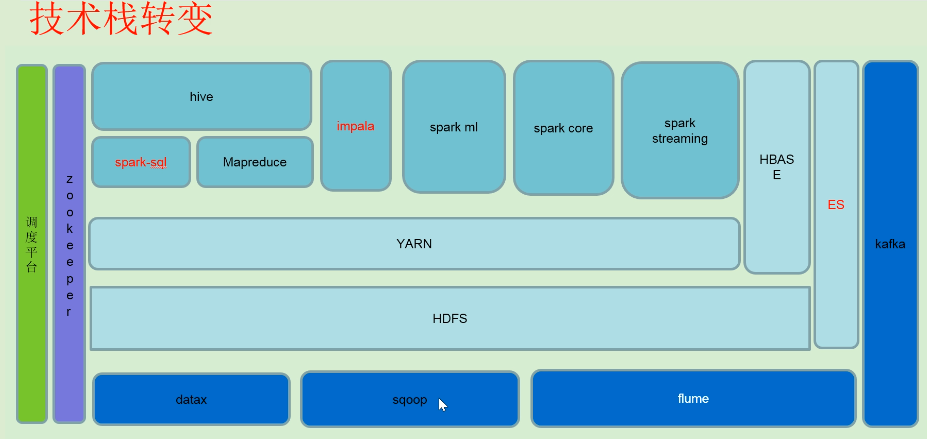
datax:阿里开源的,采集mango,es
flume:采集日志
------------------------------
spark ml:机器学习的
spark core,spark streaming: 实时的
-------------------------------
调度平台是核心:

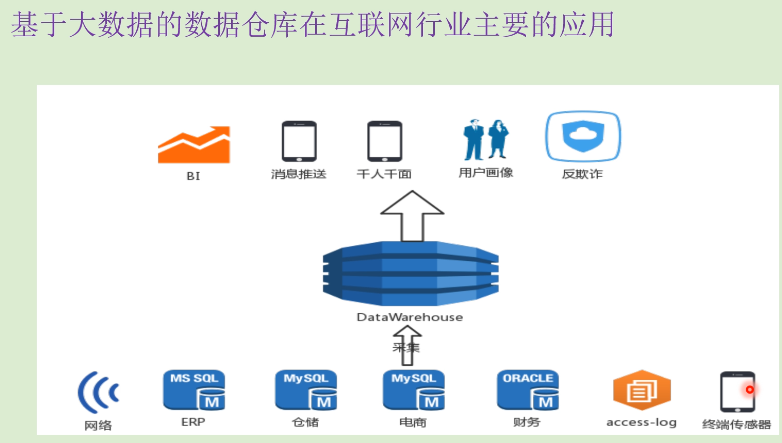
未来更广泛的应用场景:
数据分析、数据挖掘、人工智能、机器学习、风险控制、无人驾驶(需要根据大量的特征训练出来的结果)
数据化运营、精准运营
广告精准、智能投放
应用场景分类:

实时计算 :通常为 独立的常驻进程,实时处理数据流 ,也就是常说的流计算。
实时场景
1、个性化推荐
实时:用户实时信息,比如位置、设备、当前会话浏览情况、最近的浏览离线:商品关联关系、用户相似性特征、位置偏好、设备偏好、关联偏好
2、用户画像
实时:实时位置标注、当前偏好标注、当前设备标注
离线:常驻位置、稳定偏好、常用设备、消费水平等标签
3、风控
反欺诈、防刷单、薅羊毛等
实时:用户位置、IP、设备、通讯录等
离线:风险区域、风险用户、风险设备、多头等
实时推荐简单技术实现框架:
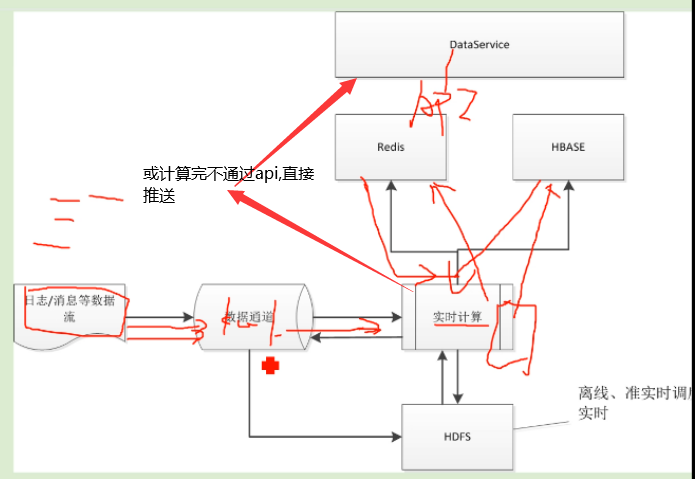
埋点日志也可以打到数据通道kafka里 ,然后传给ELK,做实时日志监控,即应用监控