Hadoop是什么:
1) Hadoop 是一个由Apache 基金会所开发的分布式系统基础架构
2)主要解决,海量数据的存储和海量数据的分析计算问题。
3) 广义上来说,HADOOP 通常是指一个更广泛的概念——HADOOP 生态圈
发展历史:
1)Lucene--Doug Cutting 开创的开源软件,用java 书写代码,实现与Google 类似的全文搜索功能,它提供了全文检索引擎的架构,包括完整的查询引擎和索引引擎
2)2001 年年底成为apache 基金会的一个子项目
3) 对于大数量的场景,Lucene 面对与Google 同样的困难
4) 学习和模仿Google 解决这些问题的办法 :微型版 Nutch
5) 可以说Google 是hadoop 的思想之源(Google 在大数据方面的三篇论文) GFS --->HDFS
Map-Reduce --->MR BigTable --->Hbase
6)2003-2004 年,Google 公开了部分GFS 和Mapreduce 思想的细节,以此为基础 Doug Cutting
等人用了 2 年业余时间实现了DFS 和 Mapreduce 机制,使 Nutch 性能飙升
7)2005 年Hadoop 作为 Lucene 的子项目 Nutch 的一部分正式引入Apache 基金会。2006 年 3 月份,Map-Reduce 和 Nutch Distributed File System (NDFS) 分别被纳入称为 Hadoop 的项目中
8) 名字来源于Doug Cutting 儿子的玩具大象
9) Hadoop 就此诞生并迅速发展,标志这云计算时代来临
名字来源于Doug Cutting 儿子的玩具大象
Hadoop自发布以来,架构经历了三次大的调整,分别是hadoop1->Hadoop2-> Hadoop3,当前主流为hadoop2版本.
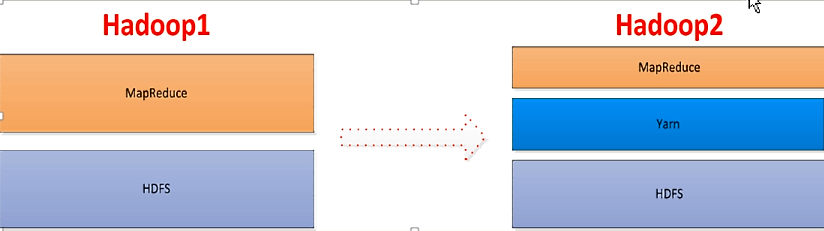
Yarn,一个构建在N个节点的集群上的资源容器,负责集群中资源的统一管理,实现资源分配、调度,带有多种资源的分配、调度策略,能够实现资源在不同应用上的隔离和优先级分配。同时提供统一的资源入口,使得不同计算框架能够运行在一个yarn资源集群上,比如spark、Mapreduce、impala、storm等,可以运行在同一个yarn集群之上
元数据:就是描述数据的数据.
数据存了多个副本,怎么知道文件存放在哪儿呢.Namenode就存放了元数据,告诉服务去哪儿拿数据.
设计时namenode的内存一般要比datanode大,且一般不做计算,即不起datanode,nodemanager或RM
减少小文件:
1/ 减少map数
2/ 减少nn的内存占用量.
mapreduce,一个分布式的编程模型,将输入数据切割成多个小的文件块,在多个进程中进行并行处理,这些进程可以是在同一台机器上,也可以分布在不同的机器上,以此实现分布式、并行处理,解决大数据、高吞吐的计算能力
三个臭皮匠顶个诸葛亮
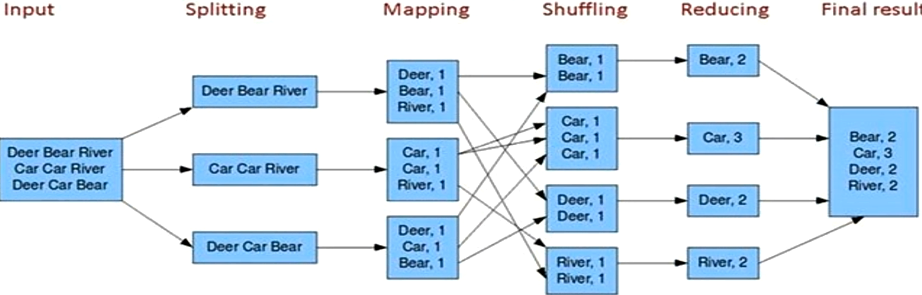
shuffer:就是把相同的key放到一起,扔到一个reduce里去
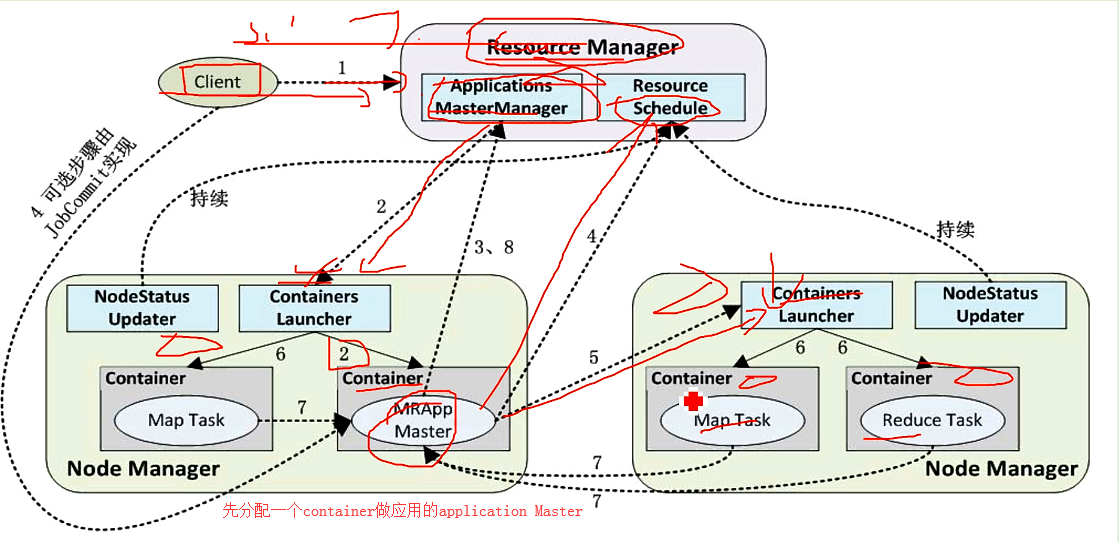
Resource Manger
负责对各NodeManger的cpu、内存资源进行调度统一管理(container,资源分配的最小粒度),包括调度器、应用程序管理器两部分
Application Manger
负责相关AM(applicatioin master) 跟踪、失败重启等,一般每个yarn上的应用程序都包含一个AM,AM跟踪任务的状态、重试
Node Manger
每个节点有一个Node Manger,负责管理本地的Container,向Resource Manger汇报本节点的资源利用情况和Container的状态
hive语句SUM(SCORE) GROUP BY NAME的MR过程:
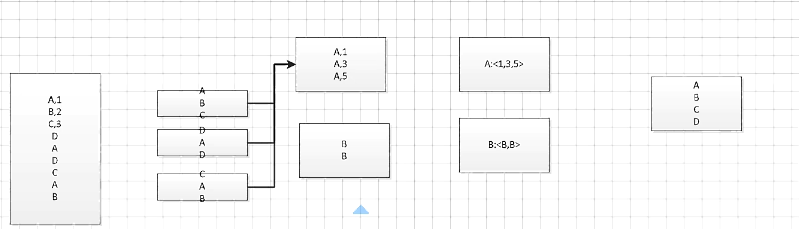
hive没有索引,hive的优化就是对MR的优化
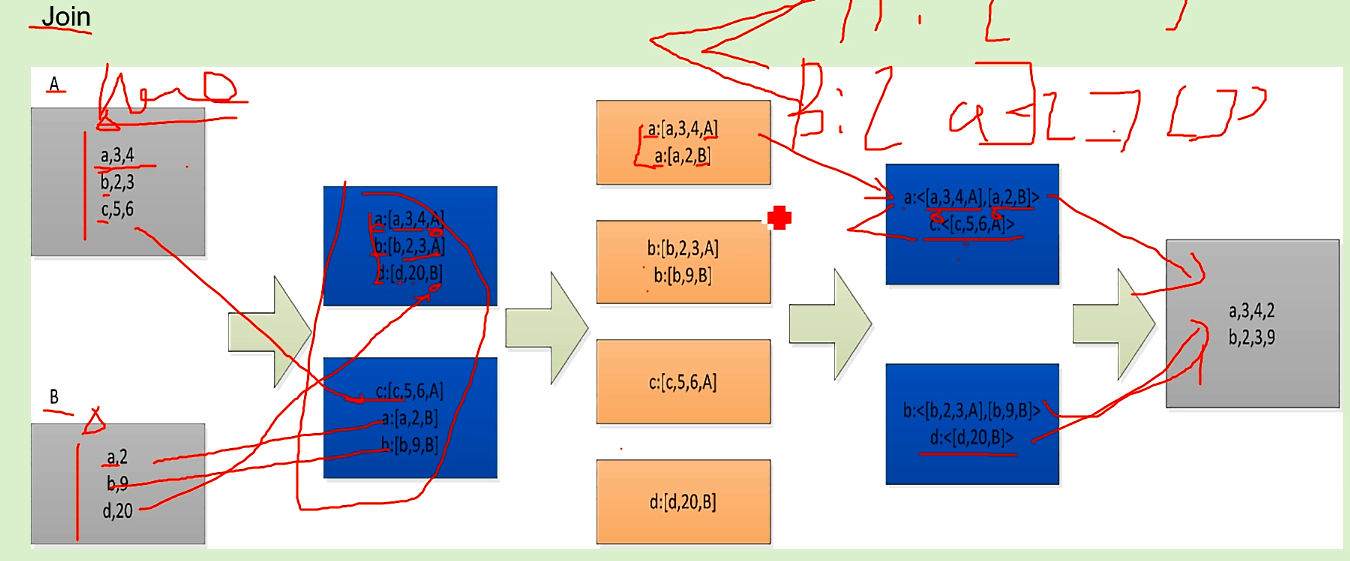
hive的join: