我们都知道volatile为共享变量提供了可见性,下面就来分析这种可见性是如何实现的。
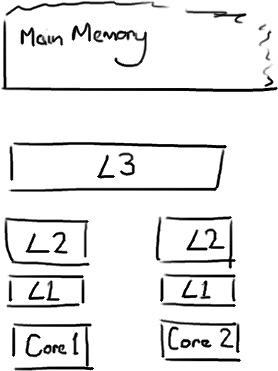
在说volatile之前,首先需要引入一个概念:缓存行。为了增加cpu的访存速度,通常会在cpu和内存之间增加多级缓存,如下图,L1、L2都是核心独享的缓存,L3为单个插槽上所有cpu共享的缓存,MainMemory为所有cpu共享。
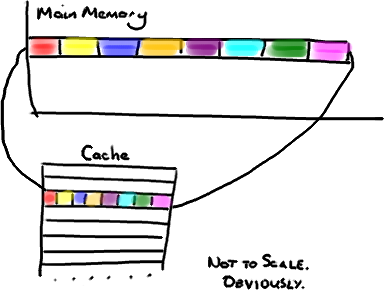
根据局部性原理,cpu每次访问主存时都会读取至少一个缓存行的数据(通常一个缓存行为64字节,哪怕读取4字节数据,也会连续读取该数据之后的60字节),这里省略了多级缓存。
下面来做一个测试,两个线程分别对一个共享int变量进行10000000次++操作,最终的输出大概率小于20000000且大于10000000,这说明JMM对共享变量的更新操作的逻辑大致是,先同步会主存,然后再从主存读取该共享变量。
1 private int i = 0; 2 @Test 3 public void testIPlusPlus() throws InterruptedException { 4 CountDownLatch countDownLatch = new CountDownLatch(2); 5 class Task implements Runnable { 6 7 @Override 8 public void run() { 9 for(int j=0; j<10000000; j++) { 10 i++; 11 } 12 countDownLatch.countDown(); 13 } 14 } 15 new Thread(new Task()).start(); 16 new Thread(new Task()).start(); 17 countDownLatch.await(); 18 System.out.println(i); 19 }
说了这么多,现在来看volatile。
| Java代码: | instance = new Singleton();//instance是volatile变量 |
| 汇编代码: |
movb $0x0,0x1104800(%esi); lock addl $0x0,(%esp); |
lock指令会锁定共享变量所在的所有缓存行,变量更新完成同步回内存后再释放,这样就会产生一个性能问题,当一个线程更新变量时,其他线程都无法对该变量的相邻变量操作了(因为相邻变量被预读取在同一缓存行)。
造成这种情况的根本原因在于,volatile锁定了缓存行,故要想优化volatile,可以使用填充空白字节的方法,将多个无关的共享变量存放在多个缓存行中。但这样做并不都是有利的,因为填充空白字节使得对象膨胀。
注意,要区分缓存(行)、工作内存、主内存,缓存是硬件概念,工作内存、主内存是JMM概念。假如有如下一个类,线程B读取value字段,线程A更新value字段,线程A更新next字段,此时双核cpu中每个核心的缓存可能都会有一个缓存行包含着value、next,线程A更新next的操作会使两个缓存行都失效,此时线程B再次读取value时就需要再次从工作内存中读取了(这就是要注意的地方,由于value只是普通字段,故不需要从主内存读取,又由于cpu缓存失效,故才需要从工作内存中读取,而此时工作内存中的值仍然是旧值)。
1 class Node{ 2 private int value; 3 private volatile Node next; 4 }
还要注意的是正是由于volatile声明才使得所有与volatile字段相关的缓存行失效,普通字段不会有这种效果。
参考:http://ifeve.com/volatile/
http://ifeve.com/disruptor-cacheline-padding/