1、什么情况下会用到dispose关键字?
dispose用于显示的回收托管和非托管资源。
托管资源指那些资源的回收工作由.net内存管理机制(CLR)的GC(Garbage Collection) 机制自动完成,无需显式释放的资源。比如int,string,float,DateTime对象,.net中超过80%的资源都是托管资源。
非托管资源指诸如包装操作系统资源的一类对象,例如文件,窗口或网络连接,对于这类资源虽然垃圾回收器(GC)可以跟踪封装非托管资源的对象的生存期,但它不了解具体如何清理这些资源。
int,string,float,DateTime等值类型,即基本数据类型都存放在栈,数组,用户定义的类、接口、委托,object,字符串等引用数据类型都存放在堆。
释放非托管资源主要有2种方式,Dispose(隐式操作),Finalize(显式操作)。Finalize一般情况下用于基类不带close方法或者不带Dispose显式方法的类,也就是说,在Finalize过程中我们需要隐式的去实现非托管资源的释放,然后系统会在Finalize过程完成后,自己的去释放托管资源。在.NET中应该尽可能的少用析构函数释放资源,MSDN2上有这样一段话:实现 Finalize 方法或析构函数对性能可能会有负面影响,因此应避免不必要地使用它们。用 Finalize 方法回收对象使用的内存需要至少两次垃圾回收。所以有析构函数的对象,需要两次,第一次调用析构函数,第二次删除对象。而且在析构函数中包含大量的释放资源代码,会降低垃圾回收器的工作效率,影响性能。所以对于包含非托管资源的对象,最好及时的调用Dispose()方法来回收资源,而不是依赖垃圾回收器。
析构函数用于释放被占用的系统资源,析构函数的名字由符号“~”加类名组成。不要在一个类中有定义任何Finalize方法的念头,因为那样会对你的“析构器链”造成潜在的严重的伤害。
2、能不能解释一下C#的垃圾回收机制?
GC是CLR的一个组件,它控制内存的分配与释放。当系统内存资源匮乏时,GC会被激发,自动去释放那些没有被使用的托管资源。堆和栈是程序运行中在内存中存放数据的区域。栈后进先出。
Microsoft为非托管资源的回收专门定义了一个接口:IDisposable,接口中只包含一个Dispose()方法。任何包含非托管资源的类,都应该继承此接口。
3、为什么不用JWT框架而要自己重写?Effort有做过评估吗?有多少差别?
JSON Web Token(JWT)是目前最流行的跨域身份验证解决方案,特别适用于分布式站点的单点登录。
跨域身份验证步骤:
1.用户向服务器发送用户名和密码。
2.验证服务器后,相关数据(如用户角色,登录时间等)将保存在当前会话中。
3.服务器向用户返回session_id,session信息都会写入到用户的Cookie。
4.用户的每个后续请求都将通过在Cookie中取出session_id传给服务器。
5.服务器收到session_id并对比之前保存的数据,确认用户的身份。
这种模式最大的问题是,没有分布式架构,无法支持横向扩展。如果使用一个服务器,该模式完全没有问题。但是,如果它是服务器群集或面向服务的跨域体系结构的话,则需要一个统一的session数据库库来保存会话数据实现共享,这样负载均衡下的每个服务器才可以正确的验证用户身份。
JWT的原则:
JWT的原则是在服务器身份验证之后,将生成一个JSON对象并将其发送回用户,当用户与服务器通信时,客户在请求中发回JSON对象。服务器仅依赖于这个JSON对象来标识用户。为了防止用户篡改数据,服务器将在生成对象时添加签名。服务器不保存任何会话数据,即服务器变为无状态,使其更容易扩展。即(appid +secret )获取到(access_token+expire_date),此后客户端将在与服务器交互中都会带access_token获取数据。为了减少盗用和窃取,JWT不建议使用HTTP协议来传输代码,而是使用加密的HTTPS协议进行传输。
WT是由三段信息构成:第一部分我们称它为头部(header),第二部分我们称其为载荷(payload),第三部分是签证(signature)。将header进行base64加密(该加密是可以对称解密的),构成了第一部分;对payload进行base64加密,得到Jwt的第二部分;base64加密后的header和base64加密后的payload,通过header中声明的加密方式和服务端的私钥进行组合加密,构成jwt的第三部分;将三部分用.连接成一个完整的字符串构成最终的jwt。
4、Http和Https的差异?Http是怎么握手的?Https为什么安全?为什么要用Https;
HTTP协议传输的数据都是未加密的,也就是明文的,因此使用HTTP协议传输隐私信息非常不安全,为了保证这些隐私数据能加密传输,于是网景公司设计了SSL(Secure Sockets Layer)协议用于对HTTP协议传输的数据进行加密,从而就诞生了HTTPS。简单来说,HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,要比http协议安全。
HTTPS和HTTP的区别主要如下:
1、https协议需要到CA申请证书,一般免费证书较少,因而需要一定费用。
2、http是超文本传输协议,信息是明文传输,https则是具有安全性的ssl加密传输协议。
3、http和https使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443。
4、http的连接很简单,是无状态的;HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,比http协议安全。
HTTPS的优点
(1)使用HTTPS协议可认证用户和服务器,确保数据发送到正确的客户机和服务器;
(2)HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,要比http协议安全,可防止数据在传输过程中不被窃取、改变,确保数据的完整性。
(3)HTTPS是现行架构下最安全的解决方案,虽然不是绝对安全,但它大幅增加了中间人攻击的成本。
HTTPS的缺点
虽然说HTTPS有很大的优势,但其相对来说,还是存在不足之处的:
(1)HTTPS协议握手阶段比较费时,会使页面的加载时间延长近50%,增加10%到20%的耗电;
(2)HTTPS连接缓存不如HTTP高效,会增加数据开销和功耗,甚至已有的安全措施也会因此而受到影响;
(3)SSL证书需要钱,功能越强大的证书费用越高,个人网站、小网站没有必要一般不会用。
(4)SSL证书通常需要绑定IP,不能在同一IP上绑定多个域名,IPv4资源不可能支撑这个消耗。
(5)HTTPS协议的加密范围也比较有限,在黑客攻击、拒绝服务攻击、服务器劫持等方面几乎起不到什么作用。最关键的,SSL证书的信用链体系并不安全,特别是在某些国家可以控制CA根证书的情况下,中间人攻击一样可行。
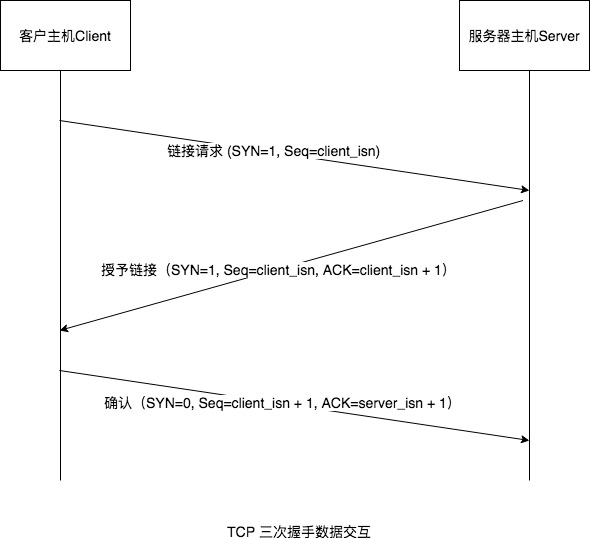
第一次握手: 建立连接,客户端A发送SYN=1、随机产生Seq=client_isn的数据包到服务器B,等待服务器确认。
第二次握手: 服务器B收到请求后确认联机(可以接受数据),发起第二次握手请求,ACK=(A的Seq+1)、SYN=1,随机产生Seq=client_isn的数据包到A。
第三次握手: A收到后检查ACK是否正确,若正确,A会在发送确认包ACK=服务器B的Seq+1、ACK=1,服务器B收到后确认Seq值与ACK值,若正确,则建立连接。
第一次握手: 建立连接,客户端A发送SYN=1、随机产生Seq=client_isn的数据包到服务器B,等待服务器确认。
第二次握手: 服务器B收到请求后确认联机(可以接受数据),发起第二次握手请求,ACK=(A的Seq+1)、SYN=1,随机产生Seq=client_isn的数据包到A。
第三次握手: A收到后检查ACK是否正确,若正确,A会在发送确认包ACK=服务器B的Seq+1、ACK=1,服务器B收到后确认Seq值与ACK值,若正确,则建立连接。
TCP标示
- SYN(synchronous建立联机)
- ACK(acknowledgement 确认)
- Sequence number(顺序号码)
第一次握手: 建立连接,客户端A发送SYN=1、随机产生Seq=client_isn的数据包到服务器B,等待服务器确认。
第二次握手: 服务器B收到请求后确认联机(可以接受数据),发起第二次握手请求,ACK=(A的Seq+1)、SYN=1,随机产生Seq=client_isn的数据包到A。
第三次握手: A收到后检查ACK是否正确,若正确,A会在发送确认包ACK=服务器B的Seq+1、ACK=1,服务器B收到后确认Seq值与ACK值,若正确,则建立连接。
TCP标示
- SYN(synchronous建立联机)
- ACK(acknowledgement 确认)
- Sequence number(顺序号码)
5、C#异步接口怎么设计;
设计API带回调参数,异步任务完成后的回调通知地址。
6、介绍一下需要同时获得多把锁的现象,应该怎么设计

死锁指的是某个资源被占用后,一直得不到释放,导致其他需要这个资源的线程进入阻塞状态。抢锁一定按照相同的顺序去抢,给抢锁加上超时,如果超时则放弃执行。
递归锁,同一个线程必须保证,加锁的次数和解锁的次数相同,其他线程才能够抢到这把锁。
乐观锁是一种思想,具体实现是,表中有一个版本字段,第一次读的时候,获取到这个字段。处理完业务逻辑开始更新的时候,需要再次查看该字段的值是否和第一次的一样。如果一样更新,反之拒绝。之所以叫乐观,因为这个模式没有从数据库加锁。
悲观锁是读取的时候为后面的更新加锁,之后再来的读操作都会等待。这种是数据库锁
乐观锁优点程序实现,不会存在死锁等问题。他的适用场景也相对乐观。阻止不了除了程序之外的数据库操作。
悲观锁是数据库实现,他阻止一切数据库操作。
所有的读锁都是为了保持数据一致性。乐观锁如果有人在你之前更新了,你的更新应当是被拒绝的,可以让用户从新操作。悲观锁则会等待前一个更新完成。这也是区别。具体业务具体分析。
当读取数据时,将version字段的值一同读出,数据每更新一次,对此version值加一。当我们提交更新的时候,判断当前版本信息与第一次取出来的版本值大小,如果数据库表当前版本号与第一次取出来的version值相等,则予以更新,否则认为是过期数据,拒绝更新,让用户重新操作。
ROWLOCK行级锁确保在用户取得被更新的行,到该行进行更新,这段时间内不被其它用户所修改。因而行级锁即可保证数据的一致性,又能提高数据操作的并发性。
锁和事务隔离级别:SQL Server中锁与事务隔离级别
数据库隔离级别设置:
- DEFAULT:使用数据库设置的隔离级别(默认),由DBA 默认的设置来决定隔离级别。
- READ_UNCOMMITTED:这是事务最低的隔离级别,它充许别外一个事务可以看到这个事务未提交的数据。会出现脏读、不可重复读、幻读 (隔离级别最低,并发性能高)。
- READ_COMMITTED:保证一个事务修改的数据提交后才能被另外一个事务读取。另外一个事务不能读取该事务未提交的数据。可以避免脏读,但会出现不可重复读、幻读问题(锁定正在读取的行)。
- REPEATABLE_READ:可以防止脏读、不可重复读,但会出幻读(锁定所读取的所有行)。
- SERIALIZABLE:这是花费最高代价但是最可靠的事务隔离级别,事务被处理为顺序执行。保证所有的情况不会发生(锁表)。
在.net框架中,事务的隔离级别是由枚举System.Data.IsolationLevel所定义的:
成 员 含 义
Chaos 无法改写隔离级别更高的事务中的挂起的更改。
ReadCommitted 在正在读取数据时保持共享锁,以避免脏读,但是在事务结束之前可以更改数据,从而导致不可重复的读取或幻像数据。
ReadUncommitted 可以进行脏读,意思是说,不发布共享锁,也不接受独占锁。
RepeatableRead 在查询中使用的所有数据上放置锁,以防止其他用户更新这些数据。防止不可重复的读取,但是仍可以有幻像行。
Serializable 在DataSet上放置范围锁,以防止在事务完成之前由其他用户更新行或向数据集中插入行。
Unspecified 正在使用与指定隔离级别不同的隔离级别,但是无法确定该级别。
锁的请求状态:
- CNVRT:锁正在从另一种模式进行转换,但是转换被另一个持有锁(模式相冲突)的进程阻塞。
- GRANT:已获取锁。
- WAIT:锁被另一个持有锁(模式相冲突)的进程阻塞。
7、是否了解Solid设计模式?最熟悉的设计模式有哪些?为什么要用这种模式?
分别是单一原则、开闭原则、里氏替换原则、迪米特法则、接口隔离原则、依赖倒置原则。前辈们总结出来的,遵循五大原则可以使程序解决紧耦合,更加健壮。
- Single Responsibility Principle:单一职责原则
- Open Closed Principle:开闭原则
- Liskov Substitution Principle:里氏替换原则
- Law of Demeter:迪米特法则
- Interface Segregation Principle:接口隔离原则
- Dependence Inversion Principle:依赖倒置原
单一责任原则(SRP,Single Responsibility Principle)
指的是一个类或者一个方法只做一件事。如果一个类承担的职责过多,就等于把这些职责耦合在一起,一个职责的变化就可能抑制或者削弱这个类完成其他职责的能力。例如餐厅服务员负责把订单给厨师去做,而不是服务员又要订单又要炒菜。类的单一职责在项目中是很难保证的。通常,接口和方法的单一职责更容易实现。
好处:
- 代码的粒度降低了,类的复杂度降低了。
- 可读性提高了,每个类的职责都很明确,可读性自然更好。
- 可维护性提高了,可读性提高了,一旦出现 bug ,自然更容易找到他问题所在。
- 改动代码所消耗的资源降低了,更改的风险也降低了。
开放封闭原则(Open Closed Principle) 对扩展开放,对修改关闭。意为一个类独立之后就不应该去修改它,而是以扩展的方式适应新需求。例如一开始做了普通计算器程序,突然添加新需求,要再做一个程序员计算器,这时不应该修改普通计算器内部,应该使用面向接口编程,组合实现扩展。里氏替换原则(LSP,Liskov Substitution Principle) 所有基类出现的地方都可以用派生类替换而不会程序产生错误。子类可以扩展父类的功能,但不能改变父类原有的功能。例如机动车必须有轮胎和发动机,子类宝马和奔驰不应该改写没轮胎或者没发动机。迪米特法则(Law of Demeter) 迪米特法则也叫最少知道原则(Least Knowledge Principle, LKP ),虽然名称不同,但都是同一个意思:一个对象应该对其他对象有最少的了解。在写类的时候,能不 public 就不 public ,所有暴露的属性或是接口,都是不得不暴露的。接口隔离原则(Interface Segregation Principle) 类不应该依赖不需要的接口,知道越少越好。例如电话接口只约束接电话和挂电话,不需要让依赖者知道还有通讯录。
与单一责任原则很相像,二者都是强调要将接口进行细分,只不过分的方式不同。单一责任原则是按照 职责 进行划分接口;而接口隔离原则是按照实现类对方法的使用来划分的,接口隔离原则更细一些。
要想完美地实现该原则,基本上就需要每个实现类都有一个专用的接口。但实际开发中,这样显然是不可能的,而且,这样很容易违背单一职责原则(可能出现同一个职责分成了好几个接口的情况),因此我们能做的就是尽量细分。 该原则主要强调两点:
- 接口尽量小:就像前面说的那样,接口中只有实现类中有用的方法。
- 接口要高内聚:在接口内部实现的方法,不管怎么改,都不会影响到接口外的其他接口或是实现类,只能影响它自己。
依赖倒置原则(Dependence Inversion Principle)
指的是高级模块不应该依赖低级模块,而是依赖抽象。抽象不能依赖细节,细节要依赖抽象。每个实现类都应该尽可能从抽象中派生。比如类A内有类B对象,称为类A依赖类B,但是不应该这样做,而是选择类A去依赖抽象。例如垃圾收集器不管垃圾是什么类型,要是垃圾就行。
8、写一段您觉得最自豪的代码;必问,关于多线程,高并发,安全,压力测试,自动化测试
为什么要压力测试
- 帮助我们了解服务器的性能以及并发
- 帮助我们查找程序问题
- 帮助我们了解网站的并发量
- 了解业务系统的瓶颈
- 了解服务器硬件的瓶颈
线程是进程的组成部分,一个进程可以拥有多个线程,而线程必须有一个父进程,线程可以有自己的堆栈、自己的程序计数器和自己的局部变量,但不拥有系统资源。
高并发一般是指在短时间内遇到大量操作请求,非常具有代表性的场景是秒杀活动与抢票,高并发是互联网分布式系统架构设计中必须考虑的因素之一,高并发相关常用的一些指标有响应时间(Response Time),吞吐量(Throughput),每秒查询率QPS(Query Per Second),并发用户数等。
多线程只是在同/异步角度上解决高并发问题的其中的一个方法手段,是在同一时刻利用计算机闲置资源的一种方式。
并发和并行是比较容易混淆的概念,他们都表示两个或者多个任务一起执行,但并发侧重多个任务交替执行,同一时刻只能有一条指令执行,但多个进程指令被快速轮换执行,使得在宏观上具有多个进程同时执行的效果。而并行确实真正的同时执行,有多条指令在多个处理器上同时执行,并行的前提条件就是多核CPU。
数据库用了锁,则tsql语句必须在事务中。
9、为什么使用REST API,不用SOAP
SOAP(Simple Object Access Protocol - 简单对象访问协议)定义了一种强类型的消息传递框架,该框架高度依赖XML和schemas。
REST(Representation State Transfer - 表示状态转移)是一种架构样式风格,它利用了当下被广泛采用的技术(特别是HTTP),本身却不创建任何新的标准。无状态,没有上下文的约束,如果做分布式、集群都不需要考虑上下文和会话保持的问题,极大的提高系统的可伸缩性。
架构风格和基于网络的软件架构设计。
10、Ditionary.add()方法的算法的时间复杂度
11、如何保证数据完整性、一致性
分布式事务服务 (Distributed Transaction Service, DTS) 是一个分布式事务框架,用来保障在大规模分布式环境下事务的最终一致性。
12、线程死锁什么意思?如何处理死锁
多个线程同时被阻塞,它们中的一个或者全部都在等待某个资源被释放。互相申请被其他进程所站用不会释放的资源而处于的一种永久等待状态。
同步机制就是使用互斥锁。
缩短事务处理时间,减少资源占用时间,避免事务中的交互减少竞争锁,避免循环。
按照顺序加锁是一种有效的死锁预防机制。但是需要事先知道所有可能会用到的锁,但总有些时候是无法预知的。
当一个线程在尝试获取锁的过程中超过了这个时限则该线程应该放弃对该锁进行请求。
锁检查,如乐观锁。
13、什么是多态,为什么要用多态
多态 同一种行为,对于不同的事物,有不同的表现形式;多态的表现形式:将父类类型作为方法的参数或将父类类型作为返回值。
14、什么是依赖注入,为什么要用依赖注入
依赖注入(Dependency Injection)把有依赖关系的类放到容器中,解析出这些类的实例,就是依赖注入。
用依赖注入进行解耦,在修改被依赖的类型实现时,不需要修改依赖类型的实现。
- 构造函数注入(Contructor Injection)
- Setter注入(Setter Injection)
- 接口注入
控制反转(Inversion of Control,缩写为IoC),是面向对象编程中的一种设计原则,可以用来减低计算机代码之间的耦合度。其中最常见的方式叫做依赖注入(Dependency Injection,简称DI),还有一种方式叫“依赖查找”(Dependency Lookup)。通过控制反转,对象在被创建的时候,由一个调控系统内所有对象的外界实体将其所依赖的对象的引用传递给它。也可以说,依赖被注入到对象中。
反射动态生成对象。
C# Unity
15、C#代码要怎么优化,曾经优化过代码吗
16、SQL中的锁:NOLOCK、HOLDLOCK、UPDLOCK、TABLOCK、TABLOCKX
NOLOCK(不加锁) 此选项被选中时,SQL Server 在读取或修改数据时不加任何锁。 在这种情况下,用户有可能读取到未完成事务(Uncommited Transaction)或回滚(Roll Back)中的数据, 即所谓的“脏数据”。
HOLDLOCK(保持锁) 此选项被选中时,SQL Server 会将此共享锁保持至整个事务结束,而不会在途中释放。
UPDLOCK(修改锁) 此选项被选中时,SQL Server 在读取数据时使用修改锁来代替共享锁,并将此锁保持至整个事务或命令结束。使用此选项能够保证多个进程能同时读取数据但只有该进程能修改数据。
TABLOCK(表锁) 此选项被选中时,SQL Server 将在整个表上置共享锁直至该命令结束。 这个选项保证其他进程只能读取而不能修改数据。
PAGLOCK(页锁) 此选项为默认选项, 当被选中时,SQL Server 使用共享页锁。
TABLOCKX(排它表锁) 此选项被选中时,SQL Server 将在整个表上置排它锁直至该命令或事务结束。这将防止其他进程读取或修改表中的数据。
HOLDLOCK 持有共享锁,直到整个事务完成,应该在被锁对象不需要时立即释放,等于SERIALIZABLE事务隔离级别
NOLOCK 语句执行时不发出共享锁,允许脏读 ,等于 READ UNCOMMITTED事务隔离级别
PAGLOCK 在使用一个表锁的地方用多个页锁
READPAST 让sql server跳过任何锁定行,执行事务,适用于READ UNCOMMITTED事务隔离级别只跳过RID锁,不跳过页,区域和表锁
ROWLOCK 强制使用行锁
TABLOCKX 强制使用独占表级锁,这个锁在事务期间阻止任何其他事务使用这个表
UPLOCK 强制在读表时使用更新而不用共享锁
注意: 锁定数据库的一个表的区别
SELECT * FROM table WITH (HOLDLOCK) 其他事务可以读取表,但不能更新删除
SELECT * FROM table WITH (TABLOCKX) 其他事务不能读取表,更新和删