.pyc 是?
Python是一门先编译后解释的语言。
当我们在命令行中输入python hello.py时,其实是激活了Python的“解释器”,告诉“解释器”:你要开始工作了。可是在“解释”之前,其实执行的第一项工作和Java一样,是编译。
当python程序运行时,编译的结果则是保存在位于内存中的PyCodeObject中,当Python程序运行结束时,Python解释器则将PyCodeObject写回到pyc文件中。
当python程序第二次运行时,首先程序会在硬盘中寻找pyc文件,如果找到,则直接载入,否则就重复上面的过程。pyc文件其实是PyCodeObject的一种持久化保存方式。
一切皆对象
对于Python,一切事物都是对象,对象基于类创建
所以,以下这些值都是对象: "wupeiqi"、38、['北京', '上海', '深圳'],并且是根据不同的类生成的对象。


数据类型初识
1、数字
(1)int(整型)
在64位系统上,整数的位数为64位,取值范围为-2**63~2**63-1
Python没有限制长整数数值的大小,但实际上由于机器内存有限,我们使用的长整数数值不可能无限大。
自从Python2.2起,如果整数发生溢出,Python会自动将整数数据转换为长整数,所以如今在长整数数据后面不加字母L也不会导致严重后果了。
(3)float(浮点型)
(4)complex(复数)用不到
复数由实数部分和虚数部分组成,一般形式为x+yj,x是复数的实数部分,y是复数的虚数部分,这里的x和y都是实数。
2、布尔值
3、字符串
name = "alex" print "i am %s " % name #输出: i am alex
py3新增字节类型 bytes 类型
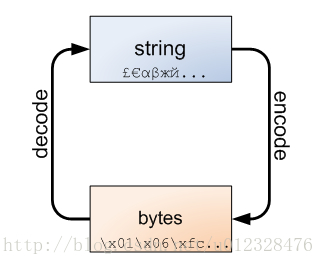
字符串可被编码为字节,字节可被解码为字符串
msg="我爱你" print(msg)#输出字符串 print(msg.encode(encoding="utf-8"))# 输出字节 print(msg.encode(encoding="utf-8").decode(encoding="utf-8"))#字符串
字符编码转换
s="我爱你" print(s)#输出字符串 s_gbk=s.encode("gbk")# 输出字节 编码 s_utf8=s.encode() gbk_to_utf8=s_gbk.decode("gbk").encode("utf_8")

4、列表
names = ['A',"B",'C','
索引:
通过下标访问列表中的元素,下标从0开始计数
切片:
print(names[0]) #A print(names[1]) #B print(names[0],names[1]) #AB print(names[0:3]) #ABC 顾头不顾尾 print(names[:3]) #ABC ,0可省略 print(names[1:3]) #BC print(names[-1]) #D 取最后一个 从后往前数 print(names[-3:-1]) #BC 顾头不顾尾 print(names[-2:]) #CD 后面全都取
追加:
print(names.append("E"))
ABCDE
插入:
print(names.insert(2,"F"))
想插入谁的位置就写谁 ABFCDE
修改:
names[2] = "该换人了"
删除:
del names[2] names.remove("Eric")#删除指定元素 names.pop(1)#删除指定元素 names.pop() #删除列表最后一个值
names=['Alex', 'Tenglan', 'Rain', 'Tom', 'Amy'] b = [1,2,3] names.extend(b) #['Alex', 'Tenglan', 'Rain', 'Tom', 'Amy', 1, 2, 3]
统计:
['Alex', 'Tenglan', 'Amy', 'Tom', 'Amy', 1, 2, 3] names.count("Amy") #2
排序&翻转
names = ['Alex', 'Tenglan', 'Amy', 'Tom', 'Amy', 1, 2, 3] names.sort() #排序 #3.0里不同数据类型不能放在一起排序了 names[-3] = '1' names[-2] = '2' names[-1] = '3' #['Alex', 'Amy', 'Amy', 'Tenglan', 'Tom', '1', '2', '3'] names.sort() #['1', '2', '3', 'Alex', 'Amy', 'Amy', 'Tenglan', 'Tom'] names.reverse() #反转 #['Tom', 'Tenglan', 'Amy', 'Amy', 'Alex', '3', '2', '1']
获取下标:
names.index("Amy") 2 #只返回找到的第一个下标
拷贝
(1)浅拷贝 只复制第一层操作
names=["a","b","c","d","e"] names2=names.copy() print(names) #["a","b","c","d","e"] print(names2) #["a","b","c","d","e"] names[2]="666" print(names) #["a","b","666","d","e"] print(names2) #["a","b","c","d","e"]
-----------------------------------------------
names3=["a","b","c",["d","e"]]
names4=names.copy()
print(names3) #["a","b","c",["d","e"]]
print(names4) #["a","b","c",["d","e"]]
names3[2]="666"
names3[3][0]="777"
print(names) #["a","b","666",["777","e"]]
print(names2) #["a","b","c",["777","e"]]
import copy names=["a","b","c",["d","e"]] names2=copy.copy(names)#同浅 names2=copy.deepcopy(names) #全部copy
names[2]="666"
names[3][0]="777" print(names) #["a","b","666",["777","e"]] print(names2) #["a","b","666",["777","e"]]
循环
for i in names: print(i)
5、元组(不可变列表)
names = ("alex","jack","eric")
它只有2个方法,一个是count,一个是index。
6、字典(无序)
字典一种key - value 的数据类型
info = { 'stu1101': "TengLan Wu", 'stu1102': "LongZe Luola", 'stu1103': "XiaoZe Maliya", }
字典的特性:
- dict是无序的
- key必须是唯一的,天生去重
info["stu1104"] = "苍井空" {'stu1102': 'LongZe Luola', 'stu1104': '苍井空', 'stu1103': 'XiaoZe Maliya', 'stu1101': 'TengLan Wu'}
修改
info['stu1101'] = "武藤兰" {'stu1102': 'LongZe Luola', 'stu1103': 'XiaoZe Maliya', 'stu1101': '武藤兰'}
{'stu1102': 'LongZe Luola', 'stu1103': 'XiaoZe Maliya', 'stu1101': '武藤兰'}
info.pop("stu1101") #标准删除姿势
->'武藤兰'
{'stu1102': 'LongZe Luola', 'stu1103': 'XiaoZe Maliya'}
del info['stu1103'] #换个姿势删除
{'stu1102': 'LongZe Luola'}
{'stu1102': 'LongZe Luola', 'stu1103': 'XiaoZe Maliya'}
info.popitem()#随机删除
->('stu1102', 'LongZe Luola')
{'stu1103': 'XiaoZe Maliya'}
查找
info = {'stu1102': 'LongZe Luola', 'stu1103': 'XiaoZe Maliya'}
info.get("stu1102") #获取'LongZe Luola'
info["stu1102"] #同上'LongZe Luola'
info["stu1105"] #如果一个key不存在,就报错,get不会,不存在只返回None
多级字典嵌套及操作
av_catalog = { "欧美":{ "www.youporn.com": ["很多免费的,世界最大的","质量一般"], "www.pornhub.com": ["很多免费的,也很大","质量比yourporn高点"], "letmedothistoyou.com": ["多是自拍,高质量图片很多","资源不多,更新慢"], "x-art.com":["质量很高,真的很高","全部收费,屌比请绕过"] }, "日韩":{ "tokyo-hot":["质量怎样不清楚,个人已经不喜欢日韩范了","听说是收费的"] }, "大陆":{ "1024":["全部免费,真好,好人一生平安","服务器在国外,慢"] } } av_catalog["大陆"]["1024"][1] += ",可以用爬虫爬下来" print(av_catalog["大陆"]["1024"]) ------>['全部免费,真好,好人一生平安', '服务器在国外,慢,可以用爬虫爬下来']
其他
#values 打印所有值 info.values() dict_values(['LongZe Luola', 'XiaoZe Maliya']) #keys 打印所有键 =info.keys() dict_keys(['stu1102', 'stu1103']) #setdefault 先找键 如果找到返回旧值 如果没找到返回新值 info.setdefault("stu1106","Alex") 'Alex' {'stu1102': 'LongZe Luola', 'stu1103': 'XiaoZe Maliya', 'stu1106': 'Alex'} info.setdefault("stu1102","龙泽萝拉") 'LongZe Luola' {'stu1102': 'LongZe Luola', 'stu1103': 'XiaoZe Maliya', 'stu1106': 'Alex'} #update 合并字典 有相同覆盖 {'stu1102': 'LongZe Luola', 'stu1103': 'XiaoZe Maliya', 'stu1106': 'Alex'} b = {1:2,3:4, "stu1102":"龙泽萝拉"} info.update(b) {'stu1102': '龙泽萝拉', 1: 2, 3: 4, 'stu1103': 'XiaoZe Maliya', 'stu1106': 'Alex'} #items 把字典转成列表 info.items() dict_items([('stu1102', '龙泽萝拉'), (1, 2), (3, 4), ('stu1103', 'XiaoZe Maliya'), ('stu1106', 'Alex')]) #通过一个列表生成默认dict 初始化新字典 dict.fromkeys([1,2,3],'testd') {1: 'testd', 2: 'testd', 3: 'testd'}
循环dict
#方法1 for key in info: print(key,info[key]) #方法2 for k,v in info.items(): #会先把dict转成list,数据里大时莫用 print(k,v)
7.字符串操作
特性:不可修改
name.capitalize() 首字母大写 name.casefold() 大写全部变小写 name.center(50,"-") 输出 '---------------------Alex Li----------------------' name.count('lex') 统计 lex出现次数 name.encode() 将字符串编码成bytes格式 name.endswith("Li") 判断字符串是否以 Li结尾 "Alex Li".expandtabs(10) 输出'Alex Li', 将 转换成多长的空格 name.find('A') 查找A,找到返回其索引, 找不到返回-1 。。。。
8.集合操作
集合是一个无序的,不重复的数据组合,它的主要作用如下:
- 去重,把一个列表变成集合,就自动去重了
- 关系测试,测试两组数据之前的交集、差集、并集等关系
s = set([3,5,9,10]) #创建一个数值集合 t = set("Hello") #创建一个唯一字符的集合 基本操作: t.add('x') # 添加一项 s.update([10,37,42]) # 在s中添加多项 t.remove('H') # 删除一项,没有则报错 len(s) #set 的长度 x in s #测试 x 是否是 s 的成员 x not in s #测试 x 是否不是 s 的成员 s.issubset(t) s <= t 测试是否 s 中的每一个元素都在 t 中 子集 s.issuperset(t) s >= t 测试是否 t 中的每一个元素都在 s 中 父集 s.union(t) s | t 返回一个新的 set 包含 s 和 t 中的每一个元素 t 和 s的并集 s.intersection(t) s & t 返回一个新的 set 包含 s 和 t 中的公共元素 t 和 s的交集 s.difference(t) s - t 返回一个新的 set 包含 s 中有但是 t 中没有的元素 求差集 s.symmetric_difference(t) s ^ t 返回一个新的 set 包含 s 和 t 中不重复的元素 对称差集(项在t或s中,但不会同时出现在二者中) s.copy() 返回 set “s”的一个浅复制
数据运算
三元运算:
result = 值1 if 条件 else 值2
如果条件为真:result = 值1
如果条件为假:result = 值2
a,b,c=1,3,5 d=a if a>b else c #d=5

比较运算:

赋值运算:

逻辑运算:

成员运算:

身份运算:

位运算:

运算符优先级:

文件操作
对文件操作流程
- 打开文件,得到文件句柄并赋值给一个变量
- 通过句柄对文件进行操作
- 关闭文件
如果不指定 默认用gbk 无法打开 或先保存成unicode格式 或者 data= open('lyrics',encoding="utf-8").read()
读 打开文件 不能写
f = open('lyrics') #打开文件 r 文件句柄 first_line = f.readline() print('first line:',first_line) #读一行 data = f.read()# 读取剩下的所有内容,文件大时不要用 print(data) #打印文件 f.close() #关闭文件
写 创建一个文件,会覆盖消失,不能读
f = open('lyrics',w,encoding="utf-8") f.write("...")
追加 不可读 不覆盖原文件
f = open('lyrics',a,encoding="utf-8") f.write("...")
读行
f = open('lyrics',w,encoding="utf-8") #读一行 print(f.readline()) #读前五行 for i in range(5): print(f.readline()) #依行打印 for line in f.readlines(): print(line) 由于每一句有换行符 打印出有空行 print(line.strip()) 去掉空格换行 #定制 第10 行不打印 for index,line in enumerate(f.readlines()): if index==9: print("------------") continue print(line.strip()) #保存成一行 ,节约空间 for line in f: print(line)
操作
#tell seek f = open('lyrics',w,encoding="utf-8") print(f.tell()) 打印文件句柄指针位置 现在为0 print(f.readline()) 读一行 print(f.tell()) 现在为72 print(f.read(5)) 读所指开头5个字符 f.seek(0)回到所指字符
print(f.flush()) 把缓存刷到内存
f = open('lyrics',a,encoding="utf-8")
f.truncate(10) 括号内不写则清空文件 写10 从文件开头截断10字符
在原文件修改 会覆盖掉
读写r+ ---------》读和追加方式
写读w+ -----------》创建新文件 写入 读取
文件修改
f = open('lyrics',r,encoding="utf-8") f_new = open('lyrics.bak',w,encoding="utf-8") #新文件 for line in f: if "我爱你" in line : line= line.replace("我爱你",“滚”) f_new.write(line) f.close() f_new.close()
with语句
为了避免打开文件后忘记关闭,可以通过管理上下文,即:
with open('log','r',encoding='utf-8') as f: ...
如此方式,当with代码块执行完毕时,内部会自动关闭并释放文件资源。
with open('log1') as obj1, open('log2') as obj2: pass