python爬虫都应用requests库来处理复杂的http请求。requests库语法上简洁明了,使用上简单易懂,而且正逐步成为大多数网络爬取的标准。
1.先找到自己python安装目录下的pip
2.在自己的电脑里打开cmd窗口。先点击开始栏,在搜索栏输入cmd,按Enter,打开cmd窗口。
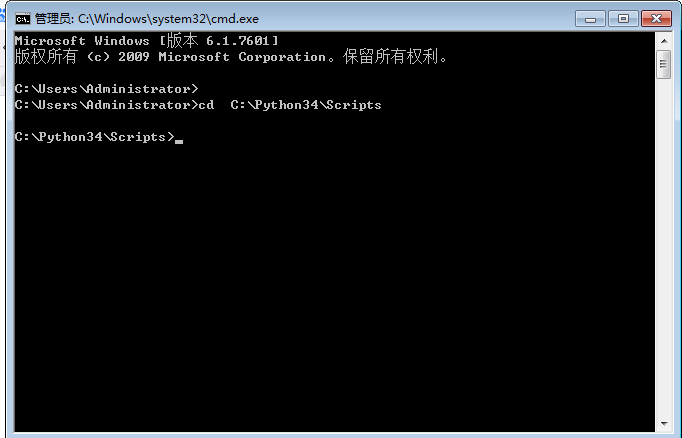
3.在cmd里将目录切换到你的pip所在路径。比如我的在C:Python34Scripts这个目录下,先切换到d盘,再进入这个路径。输入:cd C:Python34Scripts
4.输入命令pip install requests 执行安装,等待他安装完成就可以了。下图:我之前已经安装成功了

5.安装完之后,就可以使用了
代码:
import requests
#定义请求url
url='https://www.zhaohengrui.cn/'
#发起get请求
res=requests.get(url=url)
#获取响应结果
print(res) #<Response [200]>
print(res.content) #b 二进制的文本流
print(res.content.decode('utf-8'))
print(res.text) #获取响应的内容
print(res.headers) #响应头信息{'Server': 'nginx/1.16.1', 'Date': 'Sun, 19 Apr 2020 13:59:16 GMT', 'Content-Type': 'text/html', 'Last-Modified': 'Fri, 06 Mar 2020 02:42:13 GMT', 'Transfer-Encoding': 'chunked', 'Connection': 'keep-alive', 'ETag': 'W/"5e61b885-d848"', 'Content-Encoding': 'gzip'}
print(res.status_code) #请求状态码 200
print(res.url) #请求url地址
print(res.request.headers) #请求头信息{'User-Agent': 'python-requests/2.23.0', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'}
当禁止爬虫网页时:
打开源代码页面,找到Network,重新刷新网页,找到第一个网址进入Request Headers中的User-Agent复杂成功
import requests
#定义请求的url
#url='https://www.lmonkey.com/'
url='https://www.xicidaili.com/'
#定义请求头信息
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36'
}
#发起get请求
res=requests.get(url=url,headers=headers)
#获取响应状态码
code=res.status_code
print(code)
#响应成功后把响应内容写入文件中
if code==200:
with open('./out.html','w',encoding='utf-8') as fp:
fp.write(res.text)
post请求:找到关键字Form Data看关键字
import requests #定义请求的URL url='https://fanyi.baidu.com/sug' #定义请求头信息 headers={ 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36' } #post发送的数据 如何做到自己输入自动翻译 data={'kw':'你好'} #字典的值为输入要翻译的内容 #data['ke']=input("输入要翻译的话语:") #发送请求 res=requests.post(url=url,headers=headers,data=data) #接受返回数据 code=res.status_code if code==200: print("请求成功") data=res.json() if data['errno']==0: print("响应成功") #print(data) #print(data['data'][0]['k']) k=data['data'][0]['k'] v=data['data'][0]['v'].split(';')[-2] #print(v.split(';')[-2]) print(k,'==',v)