链栈基本操作头文件代码:


typedef struct node{
DataType data;
struct node *next;
}LStackNode, *LinkStack;
void InitStack(LinkStack *top){
if ((*top = (LinkStack)malloc(sizeof(LStackNode))) == NULL){
//为头结点分配一个存储空间, 若失败, 则如下操作
printf("Error");
exit(-1);
}
(*top)->next = NULL;
}
int StackEmpty(LinkStack top){
if(top->next == NULL){ //这里表示当前结点的前一个结点如果是NULL, 表示
return 1;
}
else{
return 0;
}
}
int PushStack(LinkStack top, DataType e){
LStackNode *p;
if ((p = (LStackNode*)malloc(sizeof(LStackNode))) == NULL){
printf("Error");
exit(-1);
}
p->data = e;
p->next = top->next;
top->next =p;
return 1;
}
int PopStack(LinkStack top, DataType *e){
LStackNode *p;
p = top->next;
if(!p){
//printf("栈已空");
return 0;
}
top->next = p->next;
*e = p->data;
free(p); //释放p指向的结点
return 1;
}
int GetTop(LinkStack top, DataType *e){
LStackNode *p;
p = top->next;
if(!p){
printf("栈已空!");
return 0;
}
*e = p->data;
return 1;
}
int StackLength(LinkStack top){
LStackNode *p;
p = top;
int count = 0;
while (p->next != NULL){
count++;
p = p->next;
}
return count;
}
void DestroyStack(LinkStack top){
LStackNode *p, *q;
p = top;
while(!p){
q = p;
free(q);
p->next;
}
}
为了操作方便, 通常在链栈的第一个结点之前设置一个头结点.栈顶指针top指向头结点, 而头结点的指针指向链栈的第一个结点.
示意图参考<<跟我学数据结构>>p133, 图4.7
因为 不带头结点的单链表对于第一个节点的操作与其他节点不一样,需要特殊处理,这增加了程序的复杂性和出现bug的机会,因此,通常在单链表的开始结点之前附设一个头结点。
所以, 以下学习的为包含带头结点的链栈.
其余的结点包含了本身的值和尾指针,没有头指针(双向链表每个结点就有头指针)
头结点必须有个头指针, 这样可以方便进行操作!而头结点不包含任何值!
基本知识点:
链栈由一个个结点构成, 一个结点包括数据域和指针域两个部分.
在栈链中,利用每一个结点的数据域存储栈中的每一个元素, 利用指针域表示元素之间的关系.
链栈的基本操作与链表的类似, 结点使用完毕时, 应该释放其空间.
LinkStack top; top表示结点, 栈是由一个个结点组成的, 而每个结点有两个部分.
同样的 top->next;表示它的下一个结点, 不是什么下一个结点的指针和值, 而是一个整体.
单词:
stack 栈;
init 开始,初始;
push 增加,推;
pop 伸出;
资料查询: 带头结点与不带头结点的区别 : http://blog.csdn.net/xlf13872135090/article/details/8857632
其他有关知识点补漏:
1.
typedef: typedef声明,简称typedef,为现有类型创建一个新的名字,或称为类型别名,在结构体定义,还有一些数组等地方都大量的用到。 例如: typedef int size; 此声明定义了一个int的同义字,名字为size。注意typedef并不创建新的类型。它仅仅为现有类型添加一个同义字。你可以在任何需要int的上下文中使用size: 后面的 size array[4]; 相当于 int array[4]; size 被定义成int 的同义词.
百度百科 : http://baike.baidu.com/view/1283800.htm?fr=aladdin
2.
malloc: malloc的全称是memory allocation,中文叫动态内存分配,当无法知道内存具体位置的时候,想要绑定真正的内存空间,就需要用到动态的分配内存。
原型为extern void*malloc(unsigned int num_bytes)。
全名: void *malloc(size_t size); 备注: void* 表示未确定类型的指针,void *可以指向任何类型的数据,更明确的说是指申请内存空间时还不知道用户是用这段空间来存储什么类型的数据(比如是char还是int或者...)
注意与new 的区别:
new 返回指定类型的指针,并且可以自动计算所需要大小。 而 malloc 则必须要由我们计算字节数,并且在返回后强行转换为实际类型的指针。 第一、malloc 函数返回的是 void * 类型。对于C++,如果你写成:p = malloc (sizeof(int)); 则程序无法通过编译,报错:“不能将 void* 赋值给 int * 类型变量”。所以必须通过 (int *) 来将强制转换。而对于C,没有这个要求,但为了使C程序更方便的移植到C++中来,建议养成强制转换的习惯。 第二、函数的实参为 sizeof(int) ,用于指明一个整型数据需要的大小。
百度百科http://baike.baidu.com/view/1213621.htm?fromtitle=malloc&fromid=659960&type=syn
注意下面两段代码的区别, 第一段代码是错误的, 第二段代码是正确的:
第一段:
//LinkStack.h
typedef struct node{
DataType data;
struct node *next;
}LStackNode, *LinkStack;
void InitStack(LinkStack top){
if ((top = (LinkStack)malloc(sizeof(LStackNode))) == NULL){
printf("Error");
exit(-1);
}
top->next = NULL;
}
//demo.cpp
#include <iostream>
#include <cstdlib>
using namespace std;
typedef char DataType;
#include "LinkStack.h"
int main(){
LinkStack S;
LStackNode *s;
InitStack(S);
}
第二段:
//LinkStack.h
typedef struct node{
DataType data;
struct node *next;
}LStackNode, *LinkStack;
void InitStack(LinkStack *top){
if ((*top = (LinkStack)malloc(sizeof(LStackNode))) == NULL){
printf("Error");
exit(-1);
}
(*top)->next = NULL;
}
//demo.cpp
#include <iostream>
#include <cstdlib>
using namespace std;
typedef char DataType;
#include "LinkStack.h"
int main(){
LinkStack S;
LStackNode *s;
InitStack(&S);
}
这里面关系到地址和地址所在的值的问题, 在程序上, 每个值都有他的地址!
注意区别!
问答: S(student) T(teacher)
S: 这两个有什么区别...
T:第一个是错的,第二个是对的
S:是啊! 不过第二个都有 加上*, 不是一样吗?
T:函数内修改外部的指针,那就用指向指针的指针
S:找到指针的指针, 也就是指针的地址, 然后才能做修改
T:是的, 你这里是用一个指针来表示头结点,如果用一个结构体来表示就不用指针的指针了,不过传给函数用的时候又得取地址
S:懂了, 谢谢!
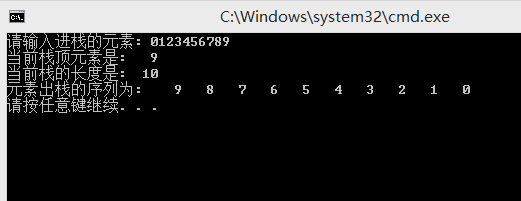
测试: demo.cpp
#include <iostream>
#include <cstdlib>
#include <string>
using namespace std;
typedef char DataType;
#include "LinkStack.h"
int main(){
LinkStack S; //S 表示头结点
//LStackNode *s;
DataType ch[50], e, *p; //ch用于输入字符, e用于操作时获取数据, *p操作用.
InitStack(&S); //初始化
printf("请输入进栈的元素: ");
gets(ch);
p = ch;
while(*p){
PushStack(S,*p);
p++;
}
if (StackEmpty(S)){
printf("栈为空");
exit(0);
}
else{
GetTop(S, &e);
printf("当前栈顶元素是:%4c
", e);
}
printf("当前栈的长度是:%4d
", StackLength(S));
printf("元素出栈的序列为: ");
while(PopStack(S, &e)){
printf("%4c", e);
}
printf("
");
return 0;
}
结果: