我选择的是爬取慕课网的关于java的课程,网址为https://www.imooc.com/search/course?words=java;
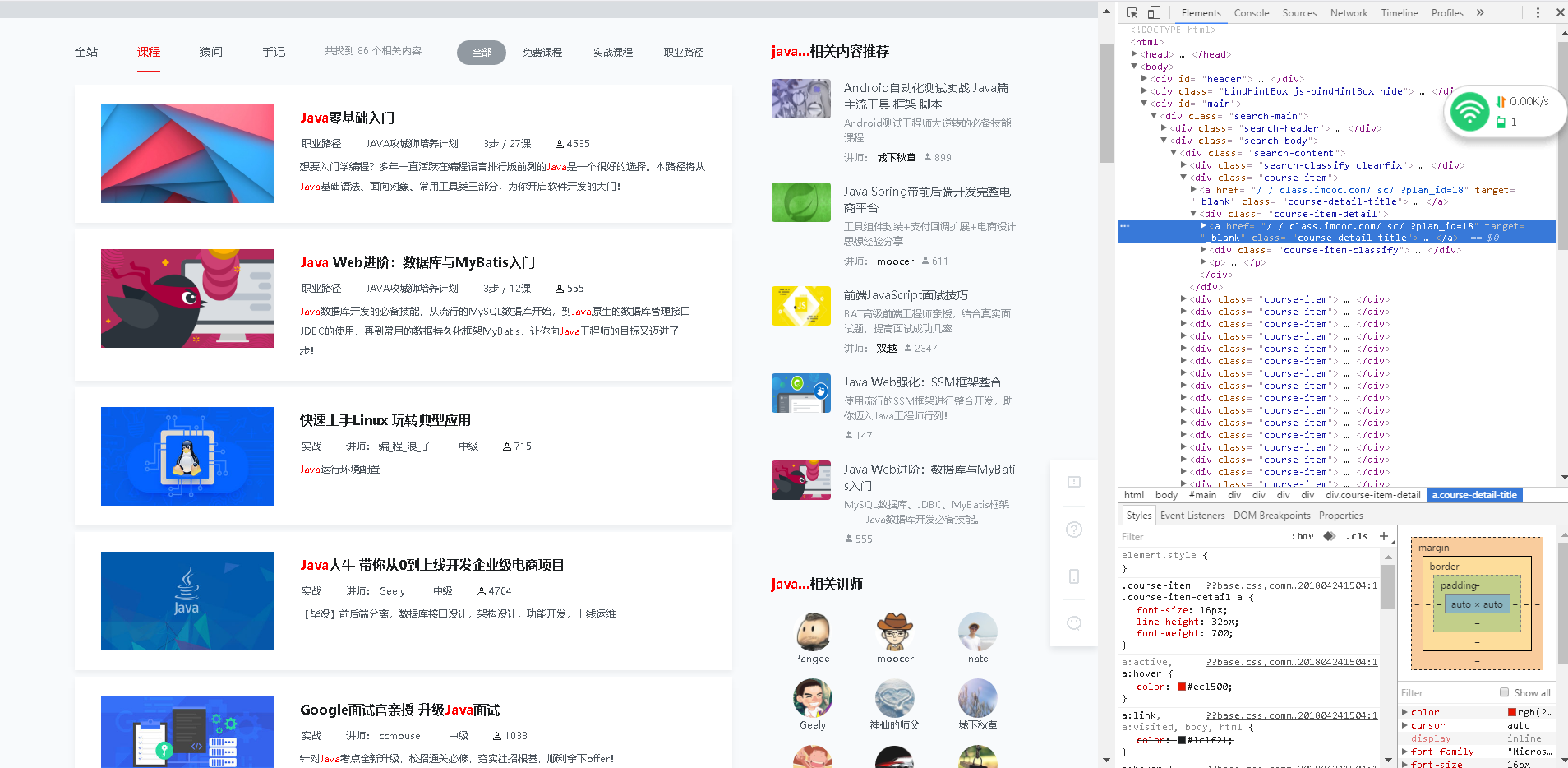
慕课网上关于java的课程总共有三页:
for i in range(1, 4):
pageUrl = "https://www.imooc.com/search/course?words=java&page={}".format(i)
gettitle(pageUrl, i)
通过这一方法获取每一页的网址跟页码,并将它们传给我自己定义的gettitle函数。
使用浏览器自带的检查功能打开网页的源代码,找到自己想要爬取的部分的标签,我要爬取的是class为course-item的相关信息:
for i in soup.select(".course-item"):
if len(i.select(".course-item-detail")) > 0:
count = count + 1
if num <= 2:
title = i.select(".course-item-detail")[0].select("a")[0].text
a=i.select("a")[0].attrs['href']
print(title,a)
SAVE(title)
else:
if count <= 26:
title = i.select(".course-item-detail")[0].select("a")[0].text
a = i.select("a")[0].attrs['href']
print(title,a)
SAVE(title)
else:
break;
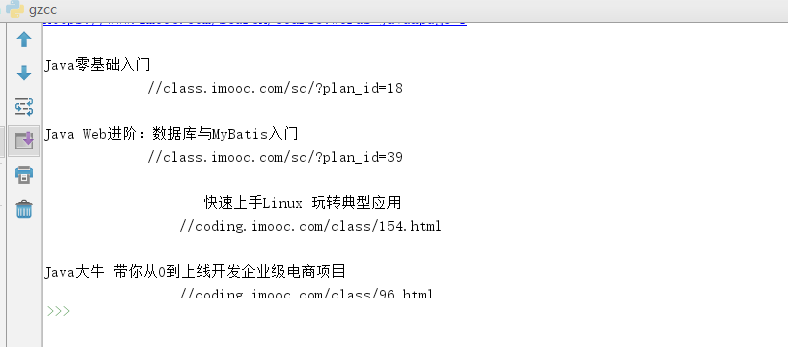
再将这些爬取的信息保存为txt文档:
def SAVE(title):
f = open("java.txt", "a", encoding='utf-8')
f.write(title )
f.close()
最后生成词云:
abel_mask = np.array(Image.open("timg.jpg"))
#读取要生成词云的文件
text_from_file_with_apath = open('java.txt',encoding='utf-8').read()
#通过jieba分词进行分词并通过空格分隔
wordlist_after_jieba = jieba.cut(text_from_file_with_apath, cut_all = True)
wl_space_split = " ".join(wordlist_after_jieba)
my_wordcloud = WordCloud(
background_color='white',
mask = abel_mask,
max_words = 100,
stopwords = {}.fromkeys(['nbsp', 'br']),
font_path = 'C:/Users/Windows/fonts/simkai.ttf',
max_font_size = 150,
random_state = 30,
scale=.5
).generate(wl_space_split)
# 根据图片生成词云颜色
image_colors = ImageColorGenerator(abel_mask)
# 以下代码显示图片
plt.imshow(my_wordcloud)
plt.axis("off")
plt.show()
使用的图片:
生成的图片:
遇到的问题及解决方法:
在pycharm中安装wordcloud时失败了,然后就去百度按照百度上提供的方法最后安装成功。
总结:
这次的爬虫作业基本上都是老师课上讲到的,这提醒我要在课上认真听讲在课后多加练习。